NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa。
一,SpanBERT
论文:SpanBERT: Improving Pre-training by Representing and Predicting Spans
GitHub:https://github.com/facebookresearch/SpanBERT
这篇论文中提出了一种新的mask的方法,以及一个新损失函数对象。并且讨论了bert中的NSP任务是否有用。接下来SpanBERT是如何预训练的,具体如下图所示:
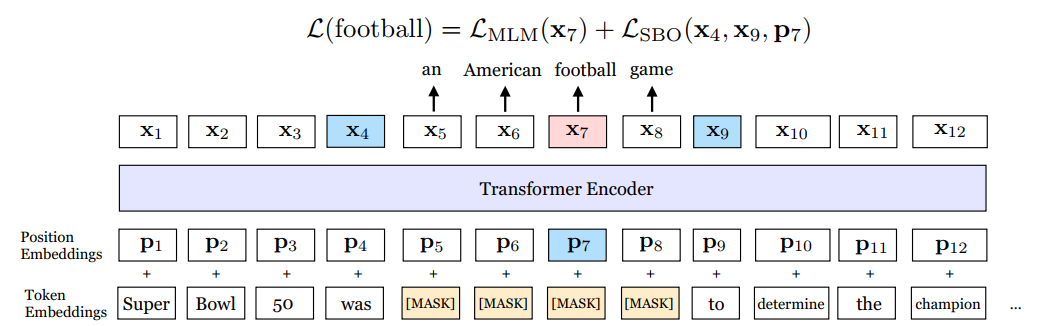
如上图所示,首先这里的mask策略是span mask。具体的做法是首先从一个几何分布中采样span的长度,且限制最大长度为10,然后再随机采样(如均匀分布) span的初始位置。整个训练任务就是预测mask的token,另外mask的比例问题和bert中类似。但是在这里引入了两个损失对象,$L_{MLM}$ 和$L_{SBO}$,$L_{MLM}$和bert中的一样,而这个$L_{SBO}$是只通过span的边界处的两个token来预测span中mask的词,公式表示如下:
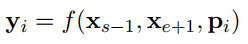
函数$f(.)$表示如下:
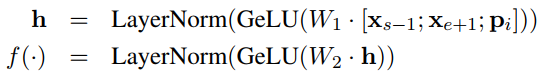
除了这些之外还有两个策略,一是动态mask,在bert中是在数据预处理阶段对一条序列随机不同的mask 10次,而在这里是每次epoch时对序列使用不同的mask。二是bert中会在数据预处理阶段生成10%的长度短于512的序列,而在这里不做这样的操作,只是对一个document一直截取512长度的序列,但最后一个序列长度可能会小于512。另外将adam中的$\epsilon$设置为1e-8。作者根据这两个策略从新训练了一个bert模型,同时去除NSP任务只使用单条序列训练了一个bert模型。因此作者给出了四个模型的性能对比:
Google BERT:谷歌开源的bert
Our BERT:基于上面两个策略训练出来的bert
Our BERT-1seq:基于上面两个策略,且去除NSP任务的bert
SpanBERT:本篇论文提出的模型
作者给出的第一个性能测试的表格是在SQuAD数据集上,

SpanBERT是有很大的提升的,另外去除NSP任务也有提升,作者认为NSP任务使得单条序列的长度不够,以至于模型无法很好的捕获长距离信息。另外在其他的抽取式QA任务上也有很大的提升
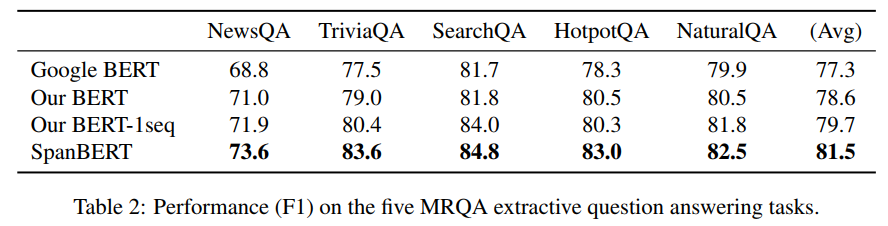
个人认为SpanBERT在抽取式QA任务上能取得如此大的提升,是因为SpanBERT中构造的任务,尤其是SBO任务实际上是有点贴合抽取式QA任务的。
在其他任务上SpanBERT也有一些提升,但是没有在抽取式QA任务上提升这么大,此外作者也做实验表示随机mask span的效果是要优于mask 实体或者短语的。
综合来说,SpanBERT在抽取式QA上的效果表现优异,在抽取式QA上是值得尝试的。
二,RoBERTa
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
GitHub:https://github.com/brightmart/roberta_zh
本篇论文主要是在bert的基础上做精细化调参,可以看作是终极调参,最后性能不仅全面碾压bert,且在大部分任务上超越了XL-Net。
总结下,主要有以下六处改变的地方:
1)Adam算法中的参数调整,$\epsilon$由1e-6改成1e-8,$\beta_2$由0.999改成0.98。
2)使用了更多的数据,从16GB增加到160GB。
3)动态mask取代静态mask。
4)去除NSP任务,并采用full-length 序列。
5)更大的batch size,更多的训练步数。
6)用byte-level BPE取代character-level BPE。
接下来我们来结合作者的实验看看。首先作者任务调整adam的参数是可以使得训练更加稳定且也能取得更好的性能,但并没有给出实验数据。增加数据提升性能是毋庸置疑的。
动态mask
在bert中是在数据预处理时做不同的mask 10次,这样在epochs为40的时候,平均每条mask的序列会出现4次,作者在这里使用动态mask,即每次epochs时做一次不同的mask。结果对比如下:

说实话,没觉得有多大提升,毕竟我们在训练模型的时候,一条数据也会被模型看到多次。
模型输入
对比了有无NSP任务的性能,以及不同的序列输入的性能,作者在这里给出了四种输入形式:
1)SEGMENT-PAIR + NSP:两个segment组成句子对,并且引入NSP任务
2)SENTENCE-PAIR + NSP:两个sentence组成句子对,并且引入NSP任务,总长可能会比512小很多。
3)FULL-SENTENCES:有多个完成的句子组成,对于跨文档的部分,用一个标识符分开,但是总长不超过512,无NSP任务
4)DOC-SENTENCES:有多个完整的句子组成,但是不跨文档,总长不超过512
性能如下:
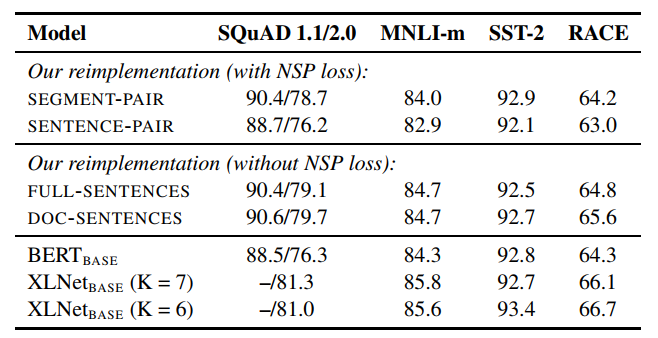
显然直接用句子对效果最差,作者认为主要时序列长度不够,导致模型无法捕捉长距离信息。并且去除NSP任务效果也有所提升。
更大的batch size,更多的训练次数
作者认为适当的加大batch size,既可以加速模型的训练,也可以提升模型的性能。

之后作者在8k的batch size下又增大训练次数
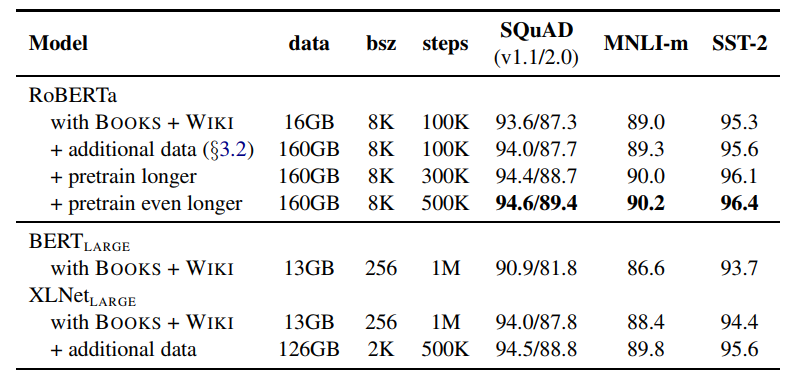
从实验中可以看出采用更大的训练次数,性能也是有不小的提升的。并且可以看到即使在训练数据差不多的情况下,RoBERTa也是要优于BERT的。
总之RoBERTa是一个调参成功的BERT,在诸多任务上全面超越bert,大部分超越XL-Net。
NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa的更多相关文章
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键, ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
随机推荐
- 初学树型dp
树型DP DFS的回溯是树形DP的重点以及核心,当回溯结束后,root的子树已经被遍历完并处理完了.这便是树形DP的最重要的特点 自己认为应该注意的点 好多人都说在更新当前节点时,它的儿子结点都给更新 ...
- logistic 回归(线性和非线性)
一:线性logistic 回归 代码如下: import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
- day73_10_18视图家族与序列化的传参。
一.序列化传参 在视图类中实例化序列对象时,还有一个参数为context,这个参数是存放字典,将所有从前端传来的数据传输到序列化中,比如需要在序列化中校验当前用户. 传入的request参数也是一个对 ...
- MySQL的delete误操作的快速恢复方法
1. 根据误操作时间定位binlog位置找到数据库的binlog存放位置,当前正在使用的binlog文件里面就有我们要恢复的数据.一般生产环境中的binlog文件都是几百M乃至上G的大小,我们不能逐行 ...
- Linux学习笔记-第17天 有点赶
第十章开始进度感觉有些快,该加把劲儿了
- LeetCode 150:逆波兰表达式求值 Evaluate Reverse Polish Notation
题目: 根据逆波兰表示法,求表达式的值. 有效的运算符包括 +, -, *, / .每个运算对象可以是整数,也可以是另一个逆波兰表达式. Evaluate the value of an arithm ...
- 软件 ---- intelij IDEA安装
官网下载, 下载地址: https://www.jetbrains.com/idea/download/#section=windows 版本说明:Ultimate 为旗舰版,功能全面,按年收费,这个 ...
- Taxi Cab Scheme POJ - 2060 二分图最小路径覆盖
Running a taxi station is not all that simple. Apart from the obvious demand for a centralised coord ...
- Entity Framework 6 中如何获取 EntityTypeConfiguration 的 Edm 信息?(一)
1. 案例1 - 类型和表之间的EF代码优先映射 从EF6.1开始,有一种更简单的方法可以做到这一点.有关 详细信息,请参阅我的新EF6.1类型和表格之间的映射. 直接贴代码了 从EF6.1开始,有一 ...
- Window权限维持(七):安全支持提供者
安全支持提供程序(SSP)是Windows API,用于扩展Windows身份验证机制.LSASS进程正在Windows启动期间加载安全支持提供程序DLL.这种行为使红队的攻击者可以删除一个任意的SS ...