MySQL 快速添加百万条数据
需要向数据库添加100W条测试数据,直接在普通表中添加速度太慢,可以使用内存表添加,然后将内存表数据复制到普通表
创建表
# 内存表
DROP TABLE IF EXISTS `test_memory`;
CREATE TABLE `test_page_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_time` datetime(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING HASH
) ENGINE = MEMORY AUTO_INCREMENT = 1000001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Fixed STORAGE MEMORY;
SET FOREIGN_KEY_CHECKS = 1;
# 普通表
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test_page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_time` datetime(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1000001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
编写函数
CREATE DEFINER=`root`@`localhost` FUNCTION `rand_str`(n INT) RETURNS varchar(255) CHARSET utf8
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE char_str VARCHAR(255) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE return_str VARCHAR(255) DEFAULT '';
WHILE i < n DO
SET return_str = CONCAT(return_str,substring(char_str, FLOOR(1 + RAND()*62), 1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END
编写存储过程
CREATE DEFINER=`root`@`localhost` PROCEDURE `add_data`(IN `n` int)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < n DO
INSERT INTO test_memory(username,`password`,create_time,update_time) VALUES (rand_str(8),MD5('123456'),NOW(),NOW());
SET i = i + 1;
END WHILE;
END
执行
# 调用存储过程
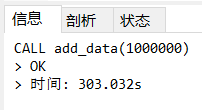
CALL add_data(1000000);
# 将内存表数据复制到普通表
INSERT INTO test SELECT * FROM test_memory;
结果
可以看到添加数据一共只花了6分钟左右。
MySQL 快速添加百万条数据的更多相关文章
- 如何在mysql数据库生成百万条数据来测试页面加载速度
1.首先复制一条sql 在复制前,需要确定该记录是否有主键 若无,则代码非常简单, "; 复制的表名↑ 粘贴的表名↑ ...
- mysql 快速生成百万条测试数据
1.生成思路 利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生成数据,然后再从内存表插入普通表中 2.创建内存表及普通表 CREATE TABLE `vote_record_me ...
- 利用bulk添加百万条数据,进行测试
(1)连接数据库 public static void BulkToDB(DataTable dt) { //数据库连接 SqlConnection sqlCon = new SqlConnectio ...
- 提高MYSQL百万条数据的查询速度
提高MYSQL百万条数据的查询速度 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 nul ...
- 查询优化百万条数据量的MySQL表
转自https://www.cnblogs.com/llzhang123/p/9239682.html 1.两种查询引擎查询速度(myIsam 引擎 ) InnoDB 中不保存表的具体行数,也就是说, ...
- MySQL快速生成100W条测试数据
https://blog.csdn.net/qq_16946803/article/details/81870174 1.生成思路利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生 ...
- 向数据库添加100W 条数据 性能测试
向数据库添加100W 条数据 性能测试 : 参考的相关网站目录: JDBC实现往MySQL插入百万级数据 https://www.cnblogs.com/fnz0/p/5713102.html MyS ...
- 复杂业务下向Mysql导入30万条数据代码优化的踩坑记录
从毕业到现在第一次接触到超过30万条数据导入MySQL的场景(有点low),就是在顺丰公司接入我司EMM产品时需要将AD中的员工数据导入MySQL中,因此楼主负责的模块connector就派上了用场. ...
- MySQL处理达到百万级数据时,如何优化?
1.两种查询引擎查询速度(myIsam 引擎 ) InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行. ...
随机推荐
- python numba讲解
目录 一:什么是numba 二:如何使用numba 由于python有动态解释性语言的特性,跑起代码来相比java.c++要慢很多,尤其在做科学计算的时候,十亿百亿级别的运算,让python的这种 ...
- 纯C语言实现链队
#include <stdio.h> #include <stdlib.h> typedef int QElemType; typedef struct QNode{ QEle ...
- 汇编指令之ADC、SBB、XCHG、MOVS指令
版权声明:本文为博主原创文章,转载请附上原文出处链接和本声明.2019-08-25,23:52:49作者By-----溺心与沉浮----博客园 介绍完这些基础指令,后面就讲到汇编JCC指令了,我觉得介 ...
- Redis 3.2.x版本 redis.conf 的配置文件参数详解
[root@web01 blog]# egrep -v"#|^$" /application/redis/conf/6379.conf bind127.0.0.1 #绑定的主机地址 ...
- Linux---用户及权限管理类命令
1.Linux用户 分为三类: 超级用户:拥有最高权限 系统用户:与系统服务相关,但不能用于登录 普通用户:由超级用户创建并赋予权限,只能操作其拥有权限的文件和目录,只能管理自己启动的进程 2.用户管 ...
- 201871010112-梁丽珍《面向对象程序设计(java)》第十五周学习总结
博文正文开头格式:(2分) 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.co ...
- Linux服务器惨遭挖矿
昨天为了协助客户测试业务,帮客户开通了一台云主机,因为是测试环境所以密码设置的很简单:1qaz@WSX,今天登陆的是否发现密码认证不通过了,确定机器是被黑掉了,估计多半是被国外小哥入侵挖矿了,记录 ...
- 3.GO-项目结构、包访问权限、闭包和值传递引用传递
3.1.goland中项目结构 (1)在goland中创建标准Go项目 (2)goland配置 创建项目Learn-Go file-settings-go-GOPATH-添加 在项目目录下创建src目 ...
- CSP2019&&AFO
day-1 attack回来了,颓废,吃蛋糕. day-0 和attack继续车上颓废. 报道,志愿者胖乎乎的,学校很新. day-1 T1写完写T2,两小时T310分 出来发现,T2好像有个地方没路 ...
- 洛谷 P1016 旅行者的预算
传送门 感觉自己连点生活常识都没有,竟然连油用过之后要减去都不知道,这种贪心模拟题都做不出来--思路在代码里,我菜死了 思路&&代码 //看题解过的..一点都没有成就感 #includ ...