pyspark minHash LSH 查找相似度
先看看官方文档:
MinHash for Jaccard Distance
MinHash is an LSH family for Jaccard distance where input features are sets of natural numbers. Jaccard distance of two sets is defined by the cardinality of their intersection and union:
d(A,B)=1−|A∩B||A∪B|d(A,B)=1−|A∩B||A∪B|MinHash applies a random hash function g to each element in the set and take the minimum of all hashed values:
The input sets for MinHash are represented as binary vectors, where the vector indices represent the elements themselves and the non-zero values in the vector represent the presence of that element in the set. While both dense and sparse vectors are supported, typically sparse vectors are recommended for efficiency. For example, Vectors.sparse(10, Array[(2, 1.0), (3, 1.0), (5, 1.0)]) means there are 10 elements in the space. This set contains elem 2, elem 3 and elem 5. All non-zero values are treated as binary “1” values.
Note: Empty sets cannot be transformed by MinHash, which means any input vector must have at least 1 non-zero entry.
Refer to the MinHashLSH Python docs for more details on the API.
from pyspark.ml.feature import MinHashLSH
from pyspark.ml.linalg import Vectors
from pyspark.sql.functions import col dataA = [(0, Vectors.sparse(6, [0, 1, 2], [1.0, 1.0, 1.0]),),
(1, Vectors.sparse(6, [2, 3, 4], [1.0, 1.0, 1.0]),),
(2, Vectors.sparse(6, [0, 2, 4], [1.0, 1.0, 1.0]),)]
dfA = spark.createDataFrame(dataA, ["id", "features"]) dataB = [(3, Vectors.sparse(6, [1, 3, 5], [1.0, 1.0, 1.0]),),
(4, Vectors.sparse(6, [2, 3, 5], [1.0, 1.0, 1.0]),),
(5, Vectors.sparse(6, [1, 2, 4], [1.0, 1.0, 1.0]),)]
dfB = spark.createDataFrame(dataB, ["id", "features"]) key = Vectors.sparse(6, [1, 3], [1.0, 1.0]) mh = MinHashLSH(inputCol="features", outputCol="hashes", numHashTables=5)
model = mh.fit(dfA) # Feature Transformation
print("The hashed dataset where hashed values are stored in the column 'hashes':")
model.transform(dfA).show() # Compute the locality sensitive hashes for the input rows, then perform approximate
# similarity join.
# We could avoid computing hashes by passing in the already-transformed dataset, e.g.
# `model.approxSimilarityJoin(transformedA, transformedB, 0.6)`
print("Approximately joining dfA and dfB on distance smaller than 0.6:")
model.approxSimilarityJoin(dfA, dfB, 0.6, distCol="JaccardDistance")\
.select(col("datasetA.id").alias("idA"),
col("datasetB.id").alias("idB"),
col("JaccardDistance")).show() # Compute the locality sensitive hashes for the input rows, then perform approximate nearest
# neighbor search.
# We could avoid computing hashes by passing in the already-transformed dataset, e.g.
# `model.approxNearestNeighbors(transformedA, key, 2)`
# It may return less than 2 rows when not enough approximate near-neighbor candidates are
# found.
print("Approximately searching dfA for 2 nearest neighbors of the key:")
model.approxNearestNeighbors(dfA, key, 2).show()
[PySpark] LSH相似度计算

一、问题场景
假设我们要找海量用户中哪些是行为相似的——
用户A:
id: 1001
name: 用户A
data: "07:00 吃早餐,09:00 工作,12:00 吃午饭,13:00 打王者,18:00 吃晚饭,22:00 睡觉"
mat: "1010001000010001100001101010000"用户B:
id: 1002
name: 用户B
data: "07:00 晨运,08:00 吃早餐,12:30 吃午饭,13:00 学习,19:00 吃晚饭,21:00 学习,23:00 睡觉"
mat: "1110001000010000001011101010000"用户C:......
mat是对用户的数据的特征化描述,比如可以定义第一位为“早起”,第二位为“晨运”,第三位为“吃早餐”,那么我们有了这个矩阵,怎么找到和他相近行为习惯的人呢?
从描述的one-hot向量中,我们看到A和B其实有很多相似性,但有部分不同,比如A打王者、但是B爱学习——
用户A: "1010001000010000001001101010000"
用户B: "1110001000010000000011101010000"这就可以用LSH大法了。
二、思路介绍
Q:LSH相似度用来干嘛?
A:全称是“局部敏感哈希”(Locality Sensitive Hashing)。能在特征向量相似又不完全相同的情况下,找出尽可能近的样本。当然了,还是需要先定义好特征,再用LSH方法。
参考资料:Extracting, transforming and selecting features(特征的提取,转换和选择)
工作中的问题是如何在海量数据中跑起来,pyspark实现时,有MinHashLSH, BucketedRandomProjectionLSH两个选择。
MinHashLSH
MinHash 是一个用于Jaccard 距离的 LSH family,它的输入特征是自然数的集合。 两组的Jaccard距离由它们的交集和并集的基数定义:
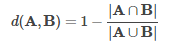
MinHash 将随机哈希函数g应用于集合中的每个元素,并取得所有哈希值中的最小值。
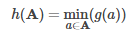
BucketedRandomProjectionLSH(欧几里得度量的随机投影)
随机桶投影是用于欧几里德距离的 LSH family。 欧氏度量的定义如下:
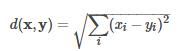
其LSH family将向量x特征向量映射到随机单位矢量v,并将映射结果分为哈希桶中:
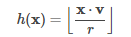
其中r是用户定义的桶长度,桶长度可用于控制哈希桶的平均大小(因此也可用于控制桶的数量)。 较大的桶长度(即,更少的桶)增加了将特征哈希到相同桶的概率(增加真实和假阳性的数量)。
桶随机投影接受任意向量作为输入特征,并支持稀疏和密集向量。
三、代码实现
不多说了,直接上代码吧。
import os
import re
import hashlib
from pyspark import SparkContext, SparkConf
from pyspark import Row
from pyspark.sql import SQLContext, SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
from pyspark.sql.functions import udf,collect_list, collect_set
from pyspark.ml.feature import MinHashLSH, BucketedRandomProjectionLSH
from pyspark.ml.linalg import Vectors, VectorUDT
# 控制spark服务启动
spark = SparkSession.builder.appName('app_name').getOrCreate()
spark.stop()
spark = SparkSession.builder.appName('app_name').getOrCreate()
class PySpark(object):
@staticmethod
def execute(df_input):
"""
程序入口,需用户重载
:return:必须返回一个DataFrame类型对象
"""
# step 1:读入DataFrame
df_mid = df_input.select('id','name','data','mat')
# step 2:特征向量预处理
def mat2vec(mat):
"""
定义UDF函数,将特征矩阵向量化
:return:返回相似度计算所需的VectorUDT类型
"""
arr = [0.0]*len(mat)
for i in range(len(mat)):
if mat[i]!='0':
arr[i]=1.0
return Vectors.dense(arr)
udf_mat2vec = udf(mat2vec,VectorUDT())
df_mid = df_mid.withColumn('vec', udf_mat2vec('mat')).select(
'id','name','data','mat','vec')
# step 3:计算相似度
## MinHashLSH,可用EuclideanDistance
minlsh = MinHashLSH(inputCol="vec", outputCol="hashes", seed=123, numHashTables=3)
model_minlsh = minlsh.fit(df_mid)
## BucketedRandomProjectionLSH
brplsh = BucketedRandomProjectionLSH(inputCol="vec", outputCol="hashes", seed=123, bucketLength=10.0, numHashTables=10)
model_brplsh = brplsh.fit(df_mid)
# step 4:计算(忽略自相似,最远距离限制0.8)
## model_brplsh类似,可用EuclideanDistance
df_ret = model_minlsh.approxSimilarityJoin(df_mid, df_mid, 0.8, distCol='JaccardDistance').select(
col("datasetA.id").alias("id"),
col("datasetA.name").alias("name"),
col("datasetA.data").alias("data"),
col("datasetA.mat").alias("mat"),
col("JaccardDistance").alias("distance"),
col("datasetB.id").alias("ref_id"),
col("datasetB.name").alias("ref_name"),
col("datasetB.data").alias("ref_data"),
col("datasetB.mat").alias("ref_mat")
).filter("id=ref_id")
return df_ret
df_in = spark.createDataFrame([
(1001,"A","xxx","1010001000010000001001101010000"),
(1002,"B","yyy","1110001000010000000011101010000"),
(1003,"C","zzz","1101100101010111011101110111101")],
['id', 'name', 'data', 'mat'])
df_out = PySpark.execute(df_in)
df_out.show()跑出来的效果是,MinHashLSH模式下,A和B距离是0.27,比较近,但A、B到C都是0.75左右,和预期相符。

好了,够钟上去举铁了……
MLlib支持两种矩阵,dense密集型和sparse稀疏型。一个dense类型的向量背后其实就是一个数组,而sparse向量背后则是两个并行数组——索引数组和值数组。比如向量(1.0, 0.0, 3.0)既可以用密集型向量表示为[1.0, 0.0, 3.0],也可以用稀疏型向量表示为(3, [0,2],[1.0,3.0]),其中3是数组的大小。
pyspark minHash LSH 查找相似度的更多相关文章
- hash 哈希查找复杂度为什么这么低?
hash 哈希查找复杂度为什么这么低? (2017-06-23 21:20:36) 转载▼ 分类: c from: 作者:jillzhang 出处:http://jillzhang.cnblogs ...
- 【剑指Offer面试编程题】题目1384:二维数组中的查找--九度OJ
题目描述: 在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. 输入: 输入可能包含 ...
- 文本相似性计算--MinHash和LSH算法
给定N个集合,从中找到相似的集合对,如何实现呢?直观的方法是比较任意两个集合.那么可以十分精确的找到每一对相似的集合,但是时间复杂度是O(n2).此外,假如,N个集合中只有少数几对集合相似,绝大多数集 ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似近期邻高速查找技术--局部敏感哈希(Locality-Sensitive ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)
本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive Hashing, LSH),内容包括了LSH的原理.LSH哈希函数集.以及LSH的一些参 ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍(转)
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive ...
- LSH︱python实现局部敏感随机投影森林——LSHForest/sklearn(一)
关于局部敏感哈希算法.之前用R语言实现过,可是由于在R中效能太低.于是放弃用LSH来做类似性检索.学了python发现非常多模块都能实现,并且通过随机投影森林让查询数据更快.觉得能够试试大规模应用在数 ...
- [Data Structure & Algorithm] 七大查找算法
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找.本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找.插值查找以及斐波那契查找 ...
- 实习日记:图像检索算法 LSH 的总结与分析(matlab)
最开始仿真和精度测试,基于 matlab 完成的. Demo_MakeTable.m (生成 Hash 表) %======================================== %** ...
随机推荐
- [LeetCode] 330. Patching Array 数组补丁
Given a sorted positive integer array nums and an integer n, add/patch elements to the array such th ...
- python:对list去重
1.set()方法 numbers = [1,7,3,2,5,6,2,3,4,1,5] new_numbers = list(set(numbers)) print new_numbers 输出 [1 ...
- Python代码编码规范
目录 1. Introduction 介绍 2. A Foolish Consistency is the Hobgoblin of Little Minds 尽信书,则不如无书 3. Code la ...
- python is 和 == 区别(8)
在python中is和==都说常用的运算符之一,主要用于检测两个变量是否相等,返回True或者False,具体区别在哪呢? 一.前言 在讲解is和==区别直接先讲解一下内置函数id(),其实在文章 p ...
- mysql 的日期和时间函数
执行函数方式 select 函数 函数名称 函 数 功 能 CURDATE() 获取当前日期 CURTIME() 获取当前时间 NOW() 获取当前的日期和时间 UNIX_TIMESTAMP ...
- Python之让 字符串内的转义字符 不做任何处理
一.在字符串前面加上 'r' 就可以了 print("\ntext_1") print(r"\ntest_2") 二.在转义字符的 '\' 前面再加一个 '\' ...
- python学习-64 面向对象三大特性----继承1
面向对象三大特性 1.三大特性? 继承,多态,封装 2.什么是继承? 类的继承和现实生活中的父与子,继承关系是一样的,父类为基类. python中的类继承分为:单继承和多继承 3.举例说明 class ...
- 路由Routers
路由Routers 对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来帮助我们快速实现路由信息. REST framework提供 ...
- Linux进程间通信—使用共享内存
Linux进程间通信-使用共享内存 转自: https://blog.csdn.net/ljianhui/article/details/10253345 下面将讲解进程间通信的另一种方式,使用共享内 ...
- Linux中su和sudo的用法整理
一.为什么会有su和sudo命令? 主要是因为在实际工作当中需要在Linux不同用户之间进行切换.root用户权限最高很多时候需要root用户才能执行一些关键命令.所以需要临时切换为root用户.工作 ...