系统树图 | Dendrogram construction | Phylogenetic Analysis
Molecular Architecture of the Mouse Nervous System
表示亲缘关系的树状图解
先看文章里是怎么做的:
Dendrogram construction
All linkage and distance calculations were performed after Log2 transformation. log2转换,很好理解。
The starting point of the dendrogram construction was the 265 clusters. 这里使用了所有的cluster。
For each gene, we computed average expression, trinarization with f = 0.2, trinarization with f = 0.05 and enrichment score. 这里应该是对每一个gene,计算在每一个cluster里的平均表达,trinarization和富集得分。
For each cluster we also know the number of cells, annotations, tissue distribution and samples of origin. We defined major classes of cell types based on prior knowledge: neurons, astroependymal, oligodendrocytes, vascular (without VLMC), immune cells and neural crest-like. 每个类已经有比较好的注释了。
For each class, we defined pan-enriched genes based on the trinarization 5% score. Each class (except neurons) was tested against neurons, to find all the genes where the fraction of clusters with trinarization score = 1 in the class was greater than the fraction of clusters with trinarization score > 0.9 among neurons. 定义了pan-enriched genes
In order to suppress batch effects (mainly due to ambient oligodenderocyte RNA in hindbrain and spinal cord samples), we collected the unique set of genes pan-enriched in the non-neuronal clusters, as well as a set of non-neuronal genes that we believe to have tendency to appear in floating RNA (Trf, Plp1, Mog, Mobp, Mfge8, Mbp, Hbb-bs, H2-DMb2) and a set of immediate early genes (Fos, Jun, Junb, Egr1). These genes were set to zero within the neuronal clusters to avoid any batch effect when clustering the neuronal clusters. 去掉批次效应
We further removed sex specific genes (Xist, Tsix, Eif2s3y, Ddx3y, Uty, and Kdm5d) and immediate early genes Egr1 and Jun from all clusters. We bounded the number of detected genes in each cluster to the top 5000 genes expressed, followed by scaling the total sum of each cluster profile to 10,000. 去掉性别基因
Next, we selected genes for linkage analysis: from each cluster select the top N = 28 enriched genes (based on pre-calculated enrichment score), perform initial clustering using linkage (Euclidean distance, Ward in MATLAB), and cut the tree based on distance criterion 50. This clustering aimed to capture the coarse structure of the hierarchy. 初步筛选基因
For each of the resulting clusters, we calculated the enrichment score as the mean over the cluster divided by the total sum and selected the 1.5 N top genes. These were added to the previously selected genes. 添加基因
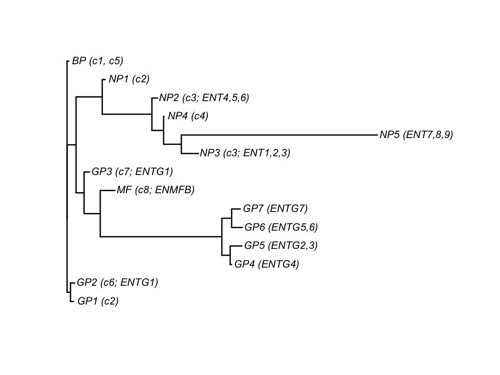
Finally, we built the dendrogram using linkage (correlation distance and Ward method). 最终用MATLAB的linkage包来作图。
如何选择基因和整合基因才是绘制dendrogram的核心。
这不是最优的作图,每个支的长短应该不一样,以表示发育的距离。
TreeExp计算,R默认plot函数成图效果非常好:
参考:
Phylogenetic Analysis of Gene Expression
Estimating the strength of expression conservation from high throughput RNA-seq data sci-hub
TreeExp - github
Data Integration, Manipulation and Visualization of Phylogenetic Trees - Guangchuang Yu
系统树图 | Dendrogram construction | Phylogenetic Analysis的更多相关文章
- CRM系统新思维
客户关系管理系统(CRM系统)是管理公司当前以及未来潜在客户的系统,其主要目的是通过优化客户关系实现公司销售业绩的长期增长,它是企业信息系统的核心之一.目前,移动互联网.大数据以及人工智能技术发展日新 ...
- R语言错误的提示(中英文翻译)
# Chinese translations for R package # Copyright (C) 2005 The R Foundation # This file is distribute ...
- INTRODUCTION TO BIOINFORMATICS
INTRODUCTION TO BIOINFORMATICS 这套教程源自Youtube,算得上比较完整的生物信息学领域的视频教程,授课内容完整清晰,专题化的讲座形式,细节讲解比国内的京师大 ...
- SCI&EI 英文PAPER投稿经验【转】
英文投稿的一点经验[转载] From: http://chl033.woku.com/article/2893317.html 1. 首先一定要注意杂志的发表范围, 超出范围的千万别投,要不就是浪费时 ...
- [Z] 计算机类会议期刊根据引用数排名
一位cornell的教授做的计算机类期刊会议依据Microsoft Research引用数的排名 link:http://www.cs.cornell.edu/andru/csconf.html Th ...
- Chapter 1 Securing Your Server and Network(8):停止未使用的服务
原文:Chapter 1 Securing Your Server and Network(8):停止未使用的服务 原文出处:http://blog.csdn.net/dba_huangzj/arti ...
- 各类聚类(clustering)算法初探
1. 聚类简介 0x1:聚类是什么? 聚类是一种运用广泛的探索性数据分析技术,人们对数据产生的第一直觉往往是通过对数据进行有意义的分组.很自然,首先要弄清楚聚类是什么? 直观上讲,聚类是将对象进行分组 ...
- AI人工智能顶级实战工程师 课程大纲
课程名称 内容 阶段一.人工智能基础 — 高等数学必知必会 1.数据分析 "a. 常数eb. 导数c. 梯度d. Taylore. gini系数f. 信息熵与组合数 ...
- 细菌多位点序列分型(Multilocus sequence typing,MLST)的原理及分型方法
摘 要: 多位点序列分型(MLST)是一种基于核酸序列测定的细菌分型方法,通过PCR扩增多个管家基因内部片段,测定其序列,分析菌株的变异,从而进行分型.MLST被广泛应用于病原菌.环境菌和真核生物中. ...
随机推荐
- 【故障处理】队列等待之TX - allocate ITL entry引起的死锁处理
[故障处理]队列等待之TX - allocate ITL entry引起的死锁处理 1 BLOG文档结构图 2 前言部分 2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌 ...
- Python,for循环小例子--99乘法表
一.99乘法表 for i in range(1, 10): for j in range(1, i + 1): print('%sx%s=%s ' % (j, i, j * i), end='') ...
- 嵌入式开发之移植OpenCv可执行程序到arm平台
0. 序言 PC操作系统:Ubuntu 16.04 OpenCv版本:4.0 交叉工具链:arm-linux-gnueabihf,gcc version 5.4.0 目标平台:arm 编译时间:201 ...
- 2013.6.29 - OpenNER第九天
上午看计算机网络,下午做计算机实验.晚上写计算机实验报告,还有OpenStack的实验报告. 写完之后跟师兄讨论了一下OpenNER的事情,觉得OpenNE很像是化学物质,里面很多都可以构成原子团,原 ...
- X509IncludeOption 枚举
X509IncludeOption 枚举 指定 X.509 数据应包括 X.509 证书链的哪些内容. EndCertOnly 2 X.509 链信息中仅包括最终证书. ExcludeRoot 1 包 ...
- hexo博客微博图床失效解决办法
最近在v2ex上看到有人说微博图床开始限制外链了.当时我看了看我的博客,图片还好.第二天再去看的时候就挂了.评论里有人说改一个no-ferrer能解决. 记录一下操作方法. N:\blog\theme ...
- eclipse正常启动,debug无法启动,解决办法
- adb命令过滤w级别日志命令
adb logcat *:W 过滤某关键字日志 adb logcat *:W | find "woyihome" 过滤某关键字日志,生成txt文档 adb logcat *:W | ...
- 树莓派3 有线网卡静态IP设置
步骤: 1.使用SSH登陆树莓派,第一连接可使用鼠标+键盘+显示器直接进入树莓派界面设置无线连接. 2.更新软件: sudo apt-get update 3.安装vim:系统自带的vi非常不好用,使 ...
- LOJ P10011 愤怒的牛 题解
每日一题 day36 打卡 Analysis 非常水的二分模板,就直接二分答案,用贪心策略check就好了 #include<iostream> #include<cstdio> ...