mysql索引原理及优化(四)
聚簇索引和非聚簇索引
分析了MySQL的索引结构的实现原理,然后我们来看看具体的存储引擎怎么实现索引结构的,MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇索引。
聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序
非聚簇索引的解释是:索引顺序与数据物理排列顺序无关
(这样说起来并不好理解,让人摸不着头脑,清继续看下文,并在插图下方对上述两句话有解释)
首先要介绍几个概念,在索引的分类中,我们可以按照索引的键是否为主键来分为“主索引”和“辅助索引”,使用主键键值建立的索引称为“主索引”,其它的称为“辅助索引”。因此主索引只能有一个,辅助索引可以有很多个。
MyISAM——非聚簇索引
MyISAM存储引擎采用的是非聚簇索引,非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
非聚簇索引的数据表和索引表是分开存储的。
非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
只有在MyISAM中才能使用FULLTEXT索引。(mysql5.6以后innoDB也支持全文索引)
*最开始我一直不懂既然非聚簇索引的主索引和辅助索引指向相同的内容,为什么还要辅助索引这个东西呢,后来才明白索引不就是用来查询的吗,用在那些地方呢,不就是WHERE和ORDER BY 语句后面吗,那么如果查询的条件不是主键怎么办呢,这个时候就需要辅助索引了。
InnoDB——聚簇索引
聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键的键值。因此主键的值长度越小越好,类型越简单越好。
聚簇索引的数据和主键索引存储在一起。
聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂,严重影响性能。
在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
*使用主索引的时候,更适合使用聚簇索引,因为聚簇索引只需要查找一次,而非聚簇索引在查到数据的地址后,还要进行一次I/O查找数据。
*因为聚簇辅助索引存储的是主键的键值,因此可以在数据行移动或者页分裂的时候降低成本,因为这时不用维护辅助索引。但是由于主索引存储的是数据本身,因此聚簇索引会占用更多的空间。
*聚簇索引在插入新数据的时候比非聚簇索引慢很多,因为插入新数据时需要检测主键是否重复,这需要遍历主索引的所有叶节点,而非聚簇索引的叶节点保存的是数据地址,占用空间少,因此分布集中,查询的时候I/O更少,但聚簇索引的主索引中存储的是数据本身,数据占用空间大,分布范围更大,可能占用好多的扇区,因此需要更多次I/O才能遍历完毕。
下图可以形象的说明聚簇索引和非聚簇索引的区别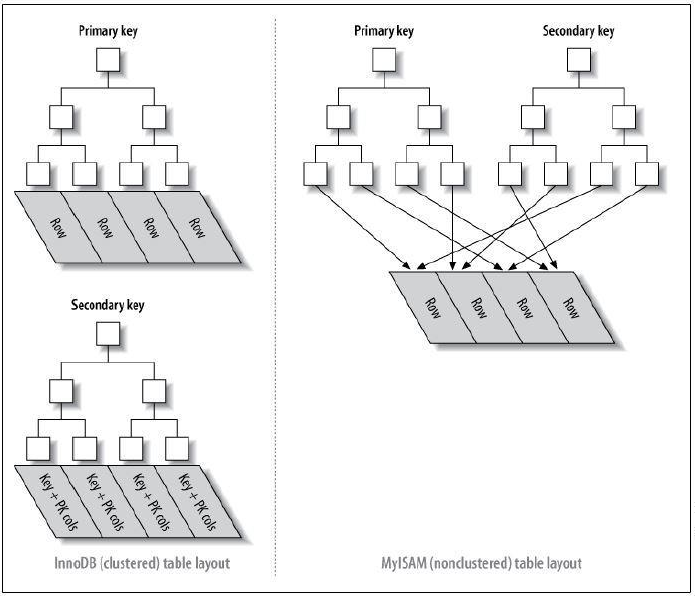
从上图中可以看到聚簇索引的辅助索引的叶子节点的data存储的是主键的值,主索引的叶子节点的data存储的是数据本身,也就是说数据和索引存储在一起,并且索引查询到的地方就是数据(data)本身,那么索引的顺序和数据本身的顺序就是相同的;
而非聚簇索引的主索引和辅助索引的叶子节点的data都是存储的数据的物理地址,也就是说索引和数据并不是存储在一起的,数据的顺序和索引的顺序并没有任何关系,也就是索引顺序与数据物理排列顺序无关。
此外MyISAM和innoDB的区别总结如下:

总结如下:
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
此外,Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
原文链接:https://blog.csdn.net/tongdanping/article/details/79878302
mysql索引原理及优化(四)的更多相关文章
- MySQL索引原理及优化
一.各种数据结构介绍 这一小节结合哈希表.完全平衡二叉树.B树以及B+树的优缺点来介绍为什么选择B+树. 假如有这么一张表(表名:sanguo): (1)Hash索引 对name字段建立哈希索引: 根 ...
- Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- (转)Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- mysql索引原理及优化(二)
索引原理分析:数据结构 索引是最常见的慢查询优化方式其是一种优化查询的数据结构,MySql中的索引是用B+树实现,而B+树就是一种数据结构,可以优化查询速度,可以利用索引快速查找数据,优化查询. 可以 ...
- mysql索引原理及优化(一)
什么是索引 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-tree的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表 ...
- mysql索引原理以及优化
一.常见查找算法: 1.顺序查找: 最基础的查找方法,对比每一个元素进行查找.在数据量很大的时候效率相当的慢. 数据结构:有序或者无需的队列 时间复杂度:O(n) 2.二分查找: 二分查找首先要求数组 ...
- mysql索引原理及优化(三)
B+Tree原理详解 MyISAM中的 B+Tree (非聚簇索引) MYISAM中叶子节点的数据区域存储的是数据记录的地址 主键索引 辅助索引 MyISAM存储引擎在使用索引查询数据时,会先根据索引 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
随机推荐
- 【RAC】 RAC For W2K8R2 安装--结尾篇(十)
[RAC] RAC For W2K8R2 安装--结尾篇(十) 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其 ...
- 摘:Windows系统内存计数器理解解析_备忘录_51Testing软件测试网...
[原创]Windows系统内存计数器理解解析 2008-05-13 11:42:23 / 个人分类:性能测试 说明:本文的计数器以Windows2003为准. 序言;F9n)\%V1a6Z C)?ZV ...
- C# List<T>排序总结
这里有很多种方法对List进行排序,本文总结了三种方法,但有多种实现. 1.对基础类型排序 方法一: 调用sort方法,如果需要降序,进行反转: List<int> list = new ...
- Python +urllib+urllib2 带数据的post请求实例
#coding:utf-8 ''' Created on 2017年11月2日 @author: li.liu ''' import urllib import urllib2 import re f ...
- linux sed 批量替换文件中的字符串或符号
sed -i :直接修改读取的文件内容,而不是输出到终端. sed -i 就是直接对文本文件进行操作的 替换每行第一次出现的字符串 sed -i 's/查找的字符串/替换的字符串/' 文件 ...
- Go——报错总结
前言 前端时间抽时间看完了Go基础的一些内容,后面接着学习,记录一些错误. 错误 cannot refer to unexported name fmt.println 报错信息: # basic . ...
- 题解 UVa11489
题目大意 多组数据,每组数据给定一个整数字串,两个人每次从中抽数,要求每次剩余的数都是 \(3\) 的倍数,请求出谁会获胜. 分析 由于 \(p-1\) 的因数的倍数在 \(p\) 进制下的各位数字之 ...
- 域权限维持:Ptk(Pass The Ticket)
Kerberos协议传送门:https://www.cnblogs.com/zpchcbd/p/11707302.html 1.黄金票据 2.白银票据
- Discrete Cosine Transform
离散余弦变换 由于实信号傅立叶变换的共轭对称性,导致DFT后在频域中有一半的数据冗余.离散余弦变换(DCT)在处理实信号时比离散傅立叶(DFT)变换更具优势.在处理声音信号这类实信号时,DFT得到的结 ...
- LeetCode 1239. Maximum Length of a Concatenated String with Unique Characters
原题链接在这里:https://leetcode.com/problems/maximum-length-of-a-concatenated-string-with-unique-characters ...