Python3正则表达式
- 正则表达式是一个特殊的字符序列,他能帮助你方便的检查一个字符串是否与某种模式匹配。
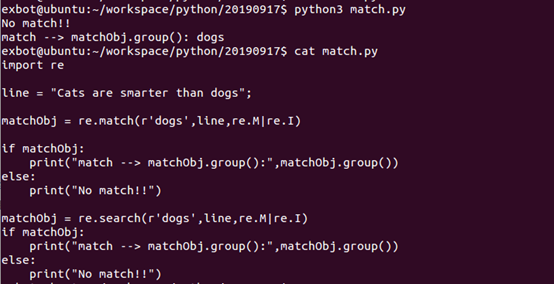
re.match函数
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回一个none。
函数语法:
re.match(pattern,string,flags=0)
函数参数说明:
|
参数 |
描述 |
|
pattern |
匹配的正则表达式 |
|
string |
要匹配的字符串 |
|
flags |
标志位,用于控制正则表达式的匹配方式 |
匹配成功re.search方法返回一个匹配的对象,否则返回None
我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式。
|
匹配对象方法 |
描述 |
|
group(num=0) |
匹配整个表达式的字符串,group()可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应的元组 |
|
groups() |
返回一个包含所有小组字符串的元组,从1到所含小组号。 |


re.match和re.search的区别
re.match只匹配字符串的开始,如果字符串开始就不符合正则表达式,则匹配失败,函数返回None,而re.search匹配整个字符串,直到找到一个匹配。
检索和替换
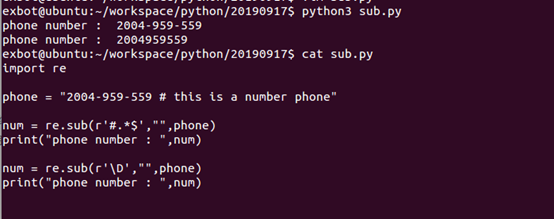
Python的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern,repl,string,count=0,flags=0)
参数:
- l pattern: 正则中的模块字符串。
- l repl: 替换的字符串,也可为一个函数
- l string: 要被查找替换的原始字符串
- l count: 模式匹配后替换的最大次数 默认0表示替换所有匹配
- l flags: 编译时用的匹配模块,数字形式
前三个为必选项,后两个为可选参数。
repl参数是一个函数
将字符串中匹配的数字乘以2

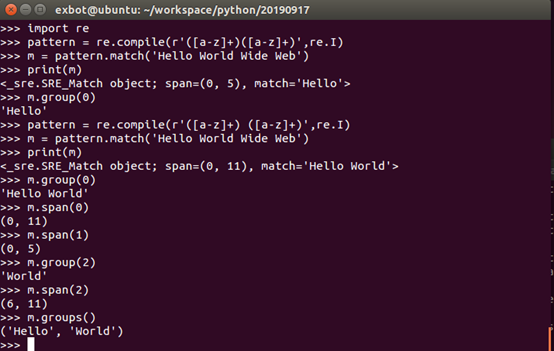
compile函数:
compile函数用于编译正则表达式,生成一个正则表达式(Pattern对象),供match()和search()这两个函数使用。
语法格式如下:
re.compile(pattern[,flags])
参数:
- l pattern: 一个字符串的正则表达式
- l flags: 可选,表示匹配模式,比如忽略大小写,多行模式等。
- l re.l: 忽略大小写
- l re.L: 表示特殊字符集, \w,\W,\b,\B,\s,\S
- l re.M 多行模式
- l re.S 即为 ‘ . ’并且包括换行符在内的任意字符(‘ . ’ 不包括换行符)
- l re.U 即为特殊字符集,\w,\W,\b,\B,\d,\D,\s,\S以来于Unicode字符属性数据库
- l re.X 为了增加可读性,忽略空格和’#’后面的注释
##compile.py
import re
pattern = re.compile(r'\d+') #用于匹配至少一个数字
m = pattern.match('one12twothree34four') #查找头部,没有匹配
print (m) m = pattern.match('one12twothree34four',2,10) #从’e’位置开始查找,没有匹配
print (m) m = pattern.match('one12twothree34four',3,10) #从‘1’位置开始查找,正好匹配
print(m) #返回一个Match对象 print(m.group(0)) #可省略0,以下相同
print(m.start(0))
print(m.end(0))
print(m.span(0))
运行结果:
exbot@ubuntu:~/workspace/python/20190917$ vim compile.py
exbot@ubuntu:~/workspace/python/20190917$ python3 compile.py
None
None
<_sre.SRE_Match object; span=(3, 5), match='12'>
12
3
5
(3, 5)
上述代码中当匹配成功时返回一个Match对象,其中:
- group([group1,…])方法用于获取一个或多个分组匹配的字符串,当要获取整个匹配的字串时,可直接使用group()或group(0)
- start([group])方法用于获取分组匹配的字串在整个字符串的起始位置(子串第一个字符索引),默认参数为0。
- end([group])方法用于获取分组匹配的子串在整个字符串的结束位置(子串最后一个字符的索引+1),默认参数为0
- span([group])方法返回(start(group),end(group))
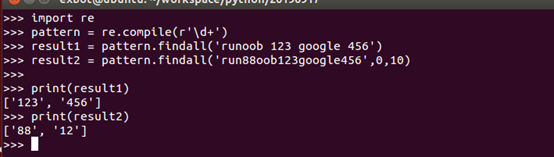
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回一个空表
注意:match和search时匹配一次,findall时匹配所有。
语法格式:
re.findall(string[, pos[, endpos]])
参数:
- l string 带匹配的字符串
- l pos 可选参数,指定字符串的起始位置,默认0
- l endpos 可选参数,指定字符串结束位置,默认为字符串长度
查找字符串中所有数字:
re.finditer
和findall类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern,string,flags=0)
参数:
- pattern: 匹配的正则表达式
- string: 要匹配的字符串
- flags : 标志位,用于控制正则表达式的匹配方式

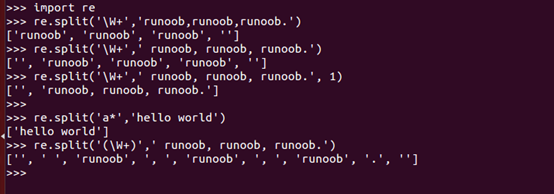
re.spilt
spilt方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern,string[, maxsplit = 0,flags = 0])
参数:
- pattern: 要匹配的正则表达式
- string: 要匹配的字符串
- maxsplit: 分割次数,maxsplit=1分隔一次,默认为0,不限制次数
- flags: 标志位,用于控制正则表达式的匹配方式
正则表达式对象:
re.RegexObject
re.compile()返回RegexObject对象
re.MatchObject
l group()返回被RE匹配的字符串
l start(): 返回匹配的开始的位置
l end(): 返回匹配结束的位置
l span(): 返回一个元组包含匹配的位置
正则表达式修饰符-可选标识
正则表达式可以包含一些可选修饰符来控制匹配的模式修饰符被指定为一个可选的标识,多个标志可以通过按位OR(|)它们来指定。
|
修饰符 |
描述 |
|
re.I |
使匹配对大小写不敏感 |
|
re.L |
做本地化识别匹配 |
|
re.M |
多行匹配,影响^和$ |
|
re.S |
使 . 匹配包括换行符在内的所有字符 |
|
re.U |
根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
|
re.X |
该标识通过给予你更灵活的格式以便你将正则表达式写的更易于理解 |
正则表达式模板:
模式字符串使用特殊的语法来标识一个正则表达式:
字母和数字标识他们本身,一个正则表达式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则他们标识特殊的含义。
反斜杠本身需要反斜杠转义。
由于正则表达式通常都包含反斜杠,所以最后使用原有字符串来标识他们。模式元素如(r’\t’,等价于\\t)匹配相应的特殊字符。
下标列出了正则表达式模式语法中的特殊元素。如果你使用了模式的同时,提供了可选标志参数,某些模式元素的含义会改变。
|
^ |
匹配字符串开头 |
|
$ |
匹配字符串结尾 |
|
. |
匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符在内的任意字符 |
|
[...] |
用来标识一组字符,单独列出:[amk]匹配‘a’,’m’或’k’ |
|
[^...] |
不在[]中的字符:[^abc]匹配除了a,b,c之外的字符 |
|
re* |
匹配0个或多个表达式 |
|
re+ |
匹配1个或多个表达式 |
|
re? |
匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
|
re{ n} |
匹配n个前面表达式。例如:”o{2}”不能匹配“Bob”中的“o”,但是可以匹配“food”中的两个“o” |
|
re{ n,} |
精确匹配n个前面的表达式。例如”o{2,}”不能匹配“Bob“中的”o“,但能匹配”fooood“中的所有”o“。”o{1,}“等价于”o+“。”o{0,}“则等价”o*“ |
|
re{ n,m} |
匹配n到m次由前面的正则表达式定义的片段,贪婪方式 |
|
a| b |
匹配a或b |
|
(re) |
匹配括号内的表达式,也表示一个组 |
|
(?imx) |
正则表达式包含三种可选项,i,m,x。只影响括号中的区域 |
|
(?-imx) |
正则表达式关闭i,m,x的可选标志,只影响括号中的区域。 |
|
(?:re) |
类似(...),但是不表示一个组 |
|
(?imx:re) |
在括号李使用i,m,x可选标示 |
|
(?-imx:re) |
在括号中不使用i,m,x的可选标志 |
|
(?#...) |
注释 |
|
(?=re) |
前向肯定界定符。如果所含正则表达式,以...表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边 |
|
(?!re) |
前向否定界定符。与肯定的界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
|
(?>re) |
匹配的独立模式,省去回溯 |
|
\w |
匹配数字字母下划线 |
|
\W |
匹配非数字字母下划线 |
|
\s |
匹配任意空白字符,等价[\t\n\r\f] |
|
\S |
匹配任意非空字符 |
|
\d |
匹配任意数字,等价于[0-9] |
|
\D |
匹配任意非数字 |
|
\A |
匹配字符串开始 |
|
\Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
|
\z |
匹配字符串结束 |
|
\G |
匹配最后匹配完成的位置 |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置例如,‘er\b’可以匹配”never”中的’er’,不能匹配“verb“中的’er’ |
|
\B |
匹配非单词边界。‘er\B’能匹配“verb“中的‘er’,但不能匹配”never“中的‘er’ |
|
\n,\t等 |
匹配一个换行符,匹配一个制表符等 |
|
\1...\9 |
匹配第n个分组 |
|
\10 |
匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式 |
正则表达式实例:
字符匹配
|
python |
匹配“python“ |
字符类
|
实例 |
描述 |
|
[Pp]ython |
匹配“Python“或“python” |
|
rub[ye] |
匹配“ruby“或”rube” |
|
[aeiou] |
匹配括号里任意一个字母 |
|
[0-9] |
匹配任何数字 |
|
[a-z] |
匹配任何小写字母 |
|
[A-Z] |
匹配任何大写字母 |
|
[a-zA-Z0-9] |
匹配任何字母和数字 |
|
[^aeiou] |
除了aeiou字母以外的所有字符 |
|
[^0-9] |
匹配除了数字以外的字符 |
特殊字符类
|
实例 |
描述 |
|
. |
匹配除“\n”之外的任何单个字符,要匹配包括’\n’在内的任何字符,情使用像‘[.\n]’的模式 |
|
\d |
匹配一个数字字符,等价[0-9] |
|
\D |
匹配一个非数字字符,等价[^0-9] |
|
\s |
匹配任何空白字符,包括空格、制符表、换页符等等。等价于[\f\n\t\r] |
|
\S |
匹配任何非空白字符。等价[^\f\n\t\r] |
|
\w |
匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9]’ |
|
\W |
匹配任何非单词字符,等价于’[^A-Za-z0-9]’ |
Python3正则表达式的更多相关文章
- 详解 Python3 正则表达式(五)
上一篇:详解 Python3 正则表达式(四) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些注明和修改 ^_^ 非捕获组和命名 ...
- 详解 Python3 正则表达式(四)
上一篇:详解 Python3 正则表达式(三) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些注明和修改 ^_^ 更多强大的功能 ...
- 详解 Python3 正则表达式(三)
上一篇:详解 Python3 正则表达式(二) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 模块级别的函数 ...
- 详解 Python3 正则表达式(二)
上一篇:详解 Python3 正则表达式(一) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 使用正则表达式 ...
- 详解 Python3 正则表达式(一)
本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 正则表达式介绍 正则表达式(Regular expressio ...
- python025 Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. ...
- python3 正则表达式学习笔记
re.match函数 re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none. ~匹配成功re.match方法返回一个匹配的对象,否则返回No ...
- python3正则表达式总结
转自csdn,去这里看更多吧: https://blog.csdn.net/weixin_40136018/article/details/81183504 还有一个废话很多的详细系列,在这里:htt ...
- 【转】Python3 正则表达式特殊符号及用法(详细列表)
转载自鱼c论坛:https://fishc.com.cn/forum.php?mod=viewthread&tid=57691&extra=page%3D1%26filter%3Dty ...
随机推荐
- 转:Java接口和抽象类
转:http://www.cnblogs.com/dolphin0520/p/3811437.html 一.抽象类 在了解抽象类之前,先来了解一下抽象方法.抽象方法是一种特殊的方法:它只有声明,而没有 ...
- Python之TensorFlow的变量收集、自定义命令参数、矩阵运算、梯度下降-4
一.TensorFlow为什么要存在变量收集的过程,主要目的就是把训练过程中的数据,比如loss.权重.偏置等数据通过图形展示的方式呈现在开发者的眼前. 自定义参数:自定义参数,主要是通过Python ...
- java之struts2的数据处理
这里的数据处理,指的是页面上的数据与Action中的数据的处理. struts2中有3种方式来接收请求提交的数据.分别是:属性驱动方式.对象驱动方式.模型驱动方式 1. 属性驱动方式 要求页面中的表单 ...
- Mybatis基于xml的动态sql实现
动态sql可以很方便的拼接sql语句,主要用于复合条件查询: 主要通过这几个标签实现: if 标签: where 标签 choose标签: foreach标签: if 标签: <select i ...
- 【洛谷 P3224】 [HNOI2012]永无乡(Splay,启发式合并)
题目链接 启发式合并就是暴力合并把小的合并到大的里,一个一个插进去. 并查集维护连通性,同时保证并查集的根就是所在Splay的根,这样能省去很多操作. #include <cstdio> ...
- kubernetes第八章--NFS PersistentVolume
- webapp之登录页面当input获得焦点时,顶部版权文本被顶上去 的解决方法
如上图,顶部版权是用绝对定位写的,被顶上去了,解决方法是判断屏幕大小,改变footer的定位方式: <script> var oHeight = $(document).height(); ...
- JavaScript之获取标签
(1)html <p id="txt">这是P标签</p> <h1 id="txt" style="color: red ...
- mysql 的使用
1. 安装 https://dev.mysql.com/downloads/mysql/ 2. 配置 $ vim ~/.bash_profile $ export PATH=$PATH:/usr/lo ...
- 如何使用API的方式消费SAP Commerce Cloud的订单服务
最近Jerry在做一个微信和SAP Commerce Cloud集成的项目,需要在微信里调用后者的Restful API进行订单创建和读取.以前Jerry对SAP Commerce Cloud知之甚少 ...