elasticsearch系列五:搜索详解(查询建议介绍、Suggester 介绍)
一、查询建议介绍
1. 查询建议是什么?
查询建议,为用户提供良好的使用体验。主要包括: 拼写检查; 自动建议查询词(自动补全)
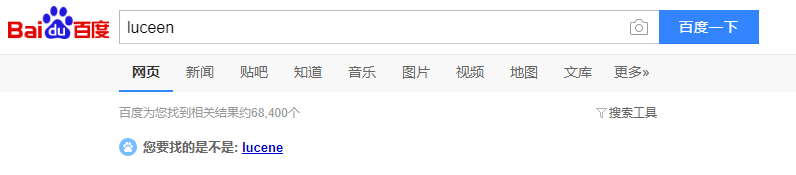
拼写检查如图:
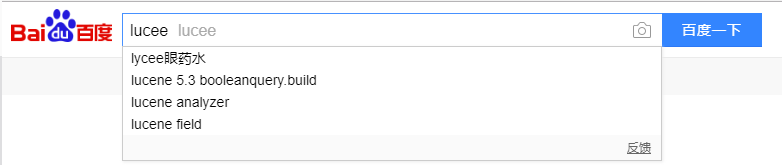
自动建议查询词(自动补全):
2. ES中查询建议的API
查询建议也是使用_search端点地址。在DSL中suggest节点来定义需要的建议查询
示例1:定义单个建议查询词
POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : { <!-- 定义建议查询 -->
"my-suggestion" : { <!-- 一个建议查询名 -->
"text" : "tring out Elasticsearch", <!-- 查询文本 -->
"term" : { <!-- 使用词项建议器 -->
"field" : "message" <!-- 指定在哪个字段上获取建议词 -->
}
}
}
}
示例2:定义多个建议查询词
POST _search
{
"suggest": {
"my-suggest-1" : {
"text" : "tring out Elasticsearch",
"term" : {
"field" : "message"
}
},
"my-suggest-2" : {
"text" : "kmichy",
"term" : {
"field" : "user"
}
}
}
}
示例3:多个建议查询可以使用全局的查询文本
POST _search
{
"suggest": {
"text" : "tring out Elasticsearch",
"my-suggest-1" : {
"term" : {
"field" : "message"
}
},
"my-suggest-2" : {
"term" : {
"field" : "user"
}
}
}
}
二、Suggester 介绍
1. Term suggester
term 词项建议器,对给入的文本进行分词,为每个词进行模糊查询提供词项建议。对于在索引中存在词默认不提供建议词,不存在的词则根据模糊查询结果进行排序后取一定数量的建议词。
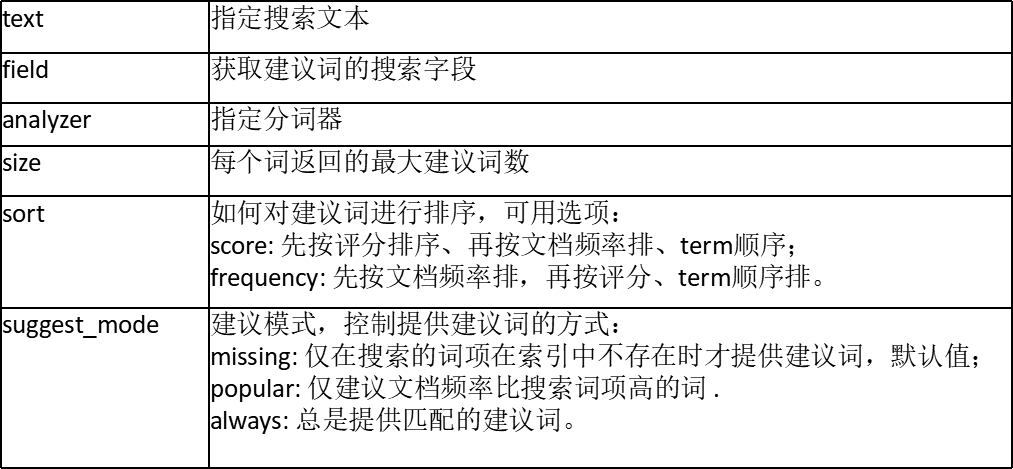
常用的建议选项:
示例1:
POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : { <!-- 定义建议查询 -->
"my-suggestion" : { <!-- 一个建议查询名 -->
"text" : "tring out Elasticsearch", <!-- 查询文本 -->
"term" : { <!-- 使用词项建议器 -->
"field" : "message" <!-- 指定在哪个字段上获取建议词 -->
}
}
}
}
2. phrase suggester
phrase 短语建议,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等
示例1:
POST /ftq/_search
{
"query": {
"match_all": {}
}, "suggest" : {
"myss":{
"text": "java sprin boot",
"phrase": {
"field": "title"
}
}
}
}
结果1:
{
"took": 177,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 1,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
},
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
},
"suggest": {
"myss": [
{
"text": "java sprin boot",
"offset": 0,
"length": 15,
"options": [
{
"text": "java spring boot",
"score": 0.20745796
}
]
}
]
}
}
3. Completion suggester 自动补全
针对自动补全场景而设计的建议器。此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-completion.html
为了使用自动补全,索引中用来提供补全建议的字段需特殊设计,字段类型为 completion。
PUT music
{
"mappings": {
"_doc" : {
"properties" : {
"suggest" : { <!-- 用于自动补全的字段 -->
"type" : "completion"
},
"title" : {
"type": "keyword"
}
}
}
}
}
Input 指定输入词 Weight 指定排序值(可选)
PUT music/_doc/1?refresh
{
"suggest" : {
"input": [ "Nevermind", "Nirvana" ],
"weight" : 34
}
}
指定不同的排序值:
PUT music/_doc/1?refresh
{
"suggest" : [
{
"input": "Nevermind",
"weight" : 10
},
{
"input": "Nirvana",
"weight" : 3
}
]}
放入一条重复数据
PUT music/_doc/2?refresh
{
"suggest" : {
"input": [ "Nevermind", "Nirvana" ],
"weight" : 20
}
}
示例1:查询建议根据前缀查询:
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest"
}
}
}
}
结果1:
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "nir",
"offset": 0,
"length": 3,
"options": [
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "2",
"_score": 20,
"_source": {
"suggest": {
"input": [
"Nevermind",
"Nirvana"
],
"weight": 20
}
}
},
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"suggest": [
"Nevermind",
"Nirvana"
]
}
}
]
}
]
}
}
示例2:对建议查询结果去重
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest",
"skip_duplicates": true
}
} }}
结果2:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "nir",
"offset": 0,
"length": 3,
"options": [
{
"text": "Nirvana",
"_index": "music",
"_type": "_doc",
"_id": "2",
"_score": 20,
"_source": {
"suggest": {
"input": [
"Nevermind",
"Nirvana"
],
"weight": 20
}
}
}
]
}
]
}
}
示例3:查询建议文档存储短语
PUT music/_doc/3?refresh
{
"suggest" : {
"input": [ "lucene solr", "lucene so cool","lucene elasticsearch" ],
"weight" : 20
}
} PUT music/_doc/4?refresh
{
"suggest" : {
"input": ["lucene solr cool","lucene elasticsearch" ],
"weight" : 10
}
}
查询3:
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "lucene s",
"completion" : {
"field" : "suggest" ,
"skip_duplicates": true
}
}
}
}
结果3:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"song-suggest": [
{
"text": "lucene s",
"offset": 0,
"length": 8,
"options": [
{
"text": "lucene so cool",
"_index": "music",
"_type": "_doc",
"_id": "3",
"_score": 20,
"_source": {
"suggest": {
"input": [
"lucene solr",
"lucene so cool",
"lucene elasticsearch"
],
"weight": 20
}
}
},
{
"text": "lucene solr cool",
"_index": "music",
"_type": "_doc",
"_id": "4",
"_score": 10,
"_source": {
"suggest": {
"input": [
"lucene solr cool",
"lucene elasticsearch"
],
"weight": 10
}
}
}
]
}
]
}
}
elasticsearch系列五:搜索详解(查询建议介绍、Suggester 介绍)的更多相关文章
- Elastic Stack 笔记(六)Elasticsearch5.6 搜索详解
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 主要包含索引过程和搜索过程. 索引过程:一条文档被索引到 Elasticsearch 之后,默认情况下 ES ...
- nginx高性能WEB服务器系列之四配置文件详解
nginx系列友情链接:nginx高性能WEB服务器系列之一简介及安装https://www.cnblogs.com/maxtgood/p/9597596.htmlnginx高性能WEB服务器系列之二 ...
- Hexo系列(二) 配置文件详解
Hexo 是一款优秀的博客框架,在使用 Hexo 搭建一个属于自己的博客网站后,我们还需要对其进行配置,使得 Hexo 更能满足自己的需求 这里所说的配置文件,是位于站点根目录下的 _config.y ...
- Ubuntu14.04下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentO ...
- Ubuntu14.04下Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)(在线或离线)
第一步: Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一) 第二步: Cloudera Manager安装之时间服务器和时间客户端(Ub ...
- Elasticsearch shield权限管理详解
Elasticsearch shield权限管理详解 学习了:https://blog.csdn.net/napoay/article/details/52201558 现在(20180424)改名为 ...
- mongo 3.4分片集群系列之六:详解配置数据库
这个系列大致想跟大家分享以下篇章: 1.mongo 3.4分片集群系列之一:浅谈分片集群 2.mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3.mongo 3.4分片集群系列之三:搭建 ...
- mongo 3.4分片集群系列之五:详解平衡器
这个系列大致想跟大家分享以下篇章: 1.mongo 3.4分片集群系列之一:浅谈分片集群 2.mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3.mongo 3.4分片集群系列之三:搭建 ...
- css3系列之transform详解translate
translate translate这个参数的,是transform 身上的,那么它有什么用呢? 其实他的作用很简单,就是平移,参考自己的位置来平移 translate() translateX() ...
- ThreeJS系列1_CinematicCameraJS插件详解
ThreeJS系列1_CinematicCameraJS插件详解 接着上篇 ThreeJS系列1_CinematicCameraJS插件介绍 看属性的来龙去脉 看方法作用 通过调整属性查看效果 总结 ...
随机推荐
- 使用flume将kafka数据sink到HBase【转】
1. hbase sink介绍 1.1 HbaseSink 1.2 AsyncHbaseSink 2. 配置flume 3. 运行测试flume 4. 使用RegexHbaseEventSeriali ...
- SolrCloud基本过程
转:http://www.data321.com/yunjisuan/20160514880/SolrZhiJieDuQuZKZhongDePeiZhiXin SolrCloud之分布式索引及与Zoo ...
- 【驱动】MTD子系统分析
MTD介绍 MTD,Memory Technology Device即内存技术设备 字符设备和块设备的区别在于前者只能被顺序读写,后者可以随机访问:同时,两者读写数据的基本单元不同. 字符设备,以字节 ...
- 【Java】Java复习笔记-第一部分
配置java环境变量 JAVA_HOME:配置JDK的目录 CLASSPATH:指定到哪里去找运行时需要用到的类代码(字节码) PATH:指定可执行程序的位置 LINUX系统 (在" .ba ...
- PostgreSQL建表SQL语句写法
DROP TABLE IF EXISTS bus; CREATE TABLE bus( id SERIAL PRIMARY KEY, mac ) NOT NULL UNIQUE, route int ...
- js实现文本框文本域光标处插入图片文本的插件(并且光标在插入内容的内容后显示)
js: /******************************************* * * 插入光标处的插件 * @authors Du xin li * @update 2015 ...
- Python 调用datetime或者time获取时间的时候以及时间转换,最好设置一下时区 否则会出现相差8个小时的情况
在使用调用datetime或者time获取时间的时候以及时间转换,最好设置一下时区, 因为不同机器设置的时区不同,获取的时间可能就不对,正好我们使用的这两个服务器使用的都是东八区,所以没有问题,设置方 ...
- 用eclipse调试scala工程代码
1,在scala工程下面执行命令:sbt -jvm-debug 9999 2,然后执行命令:run,程序就跑起来了 3,然后用eclipse工具导入scala工程. 4,最后配置调试信息,端口号跟上面 ...
- java基础篇---正则表达式
正则表达式在许多语言,例如Perl.PHP.Python.JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能. 正则表达式是一种可以 ...
- PHPUnit 在phpstrom中composer项目的应用配置
在phpstorm的composer搭建的项目调试时出现这种错误时:是其配置的错误 'Cannot create phar '/data/AppStorm/DesignPatternsPHP/vend ...