DEXSeq
1)Introduction
DEXSeq是一种在多个比较RNA-seq实验中,检验差异外显子使用情况的方法。 通过差异外显子使用(DEU),我们指的是由实验条件引起的外显子相对使用的变化。 外显子的相对使用定义为:
number of transcripts from the gene that contain this exon / number of all transcripts from the gene
大致思想:. For each exon (or part of an exon) and each sample, we count how many reads map to this exon and how many reads map to any of the other exons of the same gene. We consider the ratio of these two counts, and how it changes across conditions, to infer changes in the relative exon usage
2)安装
if("DEXSeq" %in% rownames(installed.packages()) == FALSE) {source("http://bioconductor.org/biocLite.R");biocLite("DEXSeq")}
suppressMessages(library(DEXSeq))
ls('package:DEXSeq')
pythonScriptsDir = system.file( "python_scripts", package="DEXSeq" )
list.files(pythonScriptsDir)
## [1] "dexseq_count.py" "dexseq_prepare_annotation.py" #查看是否含有这两个脚本
python dexseq_prepare_annotation.py Drosophila_melanogaster.BDGP5.72.gtf Dmel.BDGP5.25.62.DEXSeq.chr.gff #GTF转化为GFF with collapsed exon counting bins.
python dexseq_count.py Dmel.BDGP5.25.62.DEXSeq.chr.gff untreated1.sam untreated1fb.txt #count
3) 用自带实验数据集(数据预处理)
suppressMessages(library(pasilla))
inDir = system.file("extdata", package="pasilla")
countFiles = list.files(inDir, pattern="fb.txt$", full.names=TRUE) #countfile(如果不是自带数据集,可以由dexseq_count.py脚本生成)
basename(countFiles)
flattenedFile = list.files(inDir, pattern="gff$", full.names=TRUE)
basename(flattenedFile) #gff文件(如果不是自带数据集,可以由dexseq_prepare_annotation.py脚本生成)
########构造数据框sampleTable,包含sample名字,实验,文库类型等信息#######################
sampleTable = data.frame(
row.names = c( "treated1", "treated2", "treated3",
"untreated1", "untreated2", "untreated3", "untreated4" ),
condition = c("knockdown", "knockdown", "knockdown",
"control", "control", "control", "control" ),
libType = c( "single-end", "paired-end", "paired-end",
"single-end", "single-end", "paired-end", "paired-end" ) )
sampleTable ##############构建 DEXSeqDataSet object#############################
dxd = DEXSeqDataSetFromHTSeq(
countFiles,
sampleData=sampleTable,
design= ~ sample + exon + condition:exon,
flattenedfile=flattenedFile ) #四个参数
4)Standard analysis work-flow
########以下是简单的实验设计#####
genesForSubset = read.table(file.path(inDir, "geneIDsinsubset.txt"),stringsAsFactors=FALSE)[[1]] #基因子集ID
dxd = dxd[geneIDs( dxd ) %in% genesForSubset,] #取子集,减少运行量
head(colData(dxd))
head( counts(dxd), 5 )
split( seq_len(ncol(dxd)), colData(dxd)$exon )
sampleAnnotation( dxd )
############# dispersion estimates and the size factors#############
dxd = estimateSizeFactors( dxd ) ##Normalisation
dxd = estimateDispersions( dxd )
plotDispEsts( dxd ) #图1 #################Testing for differential exon usage############
dxd = testForDEU( dxd )
dxd = estimateExonFoldChanges( dxd, fitExpToVar="condition")
dxr1 = DEXSeqResults( dxd )
dxr1
mcols(dxr1)$description
table ( dxr1$padj < 0.1 )
table ( tapply( dxr1$padj < 0.1, dxr1$groupID, any ) )
plotMA( dxr1, cex=0.8 ) #图2

To see how the power to detect differential exon usage depends on the number of reads that map to an exon, a so-called MA plot is useful, which plots the logarithm of fold change versus average normalized count per exon and marks by red colour the exons which are considered significant; here, the exons with an adjusted p values of less than 0.1

############以下是更复杂的实验设计##################
formulaFullModel = ~ sample + exon + libType:exon + condition:exon
formulaReducedModel = ~ sample + exon + libType:exon
dxd = estimateDispersions( dxd, formula = formulaFullModel )
dxd = testForDEU( dxd,
reducedModel = formulaReducedModel,
fullModel = formulaFullModel )
dxr2 = DEXSeqResults( dxd )
table( dxr2$padj < 0.1 )
table( before = dxr1$padj < 0.1, now = dxr2$padj < 0.1 )##和简单的实验设计比较
5)Visualization
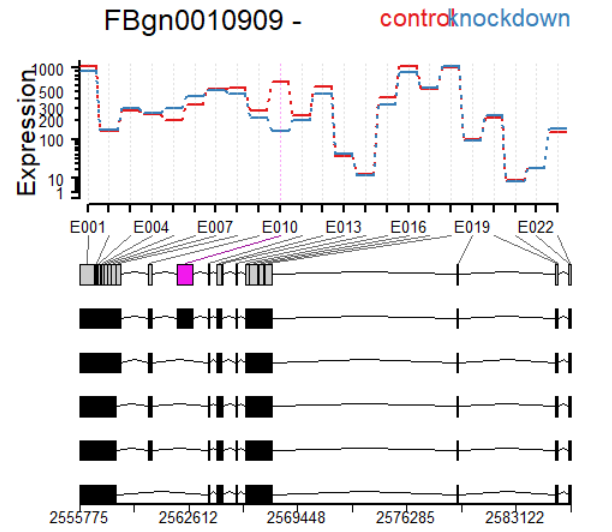
plotDEXSeq( dxr2, "FBgn0010909", legend=TRUE, cex.axis=1.2, cex=1.3,
lwd=2 )
plotDEXSeq( dxr2, "FBgn0010909", displayTranscripts=TRUE, legend=TRUE,
cex.axis=1.2, cex=1.3, lwd=2 )
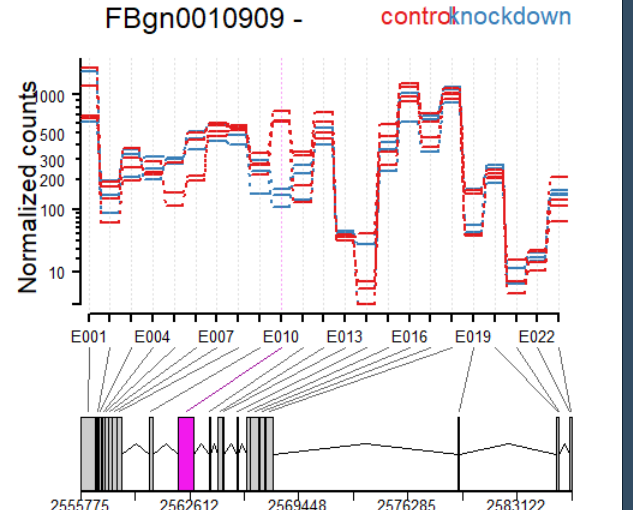
plotDEXSeq( dxr2, "FBgn0010909", expression=FALSE, norCounts=TRUE,
legend=TRUE, cex.axis=1.2, cex=1.3, lwd=2 )
plotDEXSeq( dxr2, "FBgn0010909", expression=FALSE, splicing=TRUE,
legend=TRUE, cex.axis=1.2, cex=1.3, lwd=2 )
DEXSeqHTML( dxr2, FDR=0.1, color=c("#FF000080", "#0000FF80") )


DEXSeq的更多相关文章
- 【转录组入门】6:reads计数
作业要求: 实现这个功能的软件也很多,还是烦请大家先自己搜索几个教程,入门请统一用htseq-count,对每个样本都会输出一个表达量文件. 需要用脚本合并所有的样本为表达矩阵.参考:生信编程直播第四 ...
- Bulk RNA-Seq转录组学习
与之对应的是single cell RNA-Seq,后面也会有类似文章. 参考:https://github.com/xuzhougeng/Learn-Bioinformatics/ 作业:RNA-s ...
- Bioconductor应用领域之基因芯片
引用自https://mp.weixin.qq.com/s?__biz=MzU4NjU4ODQ2MQ==&mid=2247484662&idx=1&sn=194668553f9 ...
随机推荐
- utmp
How to monitor user login history on CentOS with utmpdump Last updated on September 22, 2014 Authore ...
- bzoj2765 铁人双项比赛
Description 铁人双项比赛是吉林教育学院的一项传统体育项目.该项目比赛由长跑和骑自行车组成,参赛选手必须先完成k公里的长跑,然后完成r公里的骑车,才能到达终点.每个参赛选手所擅长的项目不同, ...
- [转][Java] Date 格式化
import org.springframework.context.ApplicationContext; import org.springframework.context.support.Cl ...
- [转]下拉按钮 C#_Winform 自定义控件
[https://workspaces.codeproject.com/elia-sarti/splitbutton-an-xp-style-dropdown-split-button] using ...
- json串反转义(消除反斜杠)-- 转载
JSon串在被串行化后保存在文件中,读取字符串时,是不能直接拿来用JSON.parse()解析为JSON 对象的.因为它是一个字符串,不是一个合法的JSON对象格式.例如下面的JSON串保存在文件中 ...
- linux上安装vsftpd
介绍:在前几篇博客中博主介绍了,怎么用java语言搭建一个简单的网站.如果有些小伙伴想把自己做的网站发布到服务器上让别人访问的话,不妨可以关注博主的博客,博客会在接下来的几篇博客中介绍怎么把一个网站发 ...
- Java内存原型分析:基本知识
转载: Java内存原型分析:基本知识 java虚拟机内存原型 寄存器:我们在程序中无法控制 栈:存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中 堆:存放用new产生的数据 静 ...
- Python 中一个逗号引发的悲剧
遇到一个 Python 字符串的坑,记录一下.看看下面这些代码 >>> a = [ ... 'foo' ... 'bar', ... 'tree' ... ] >>> ...
- 修改IP
查看系统版本 [root@host ~]# cat /etc/issueCentOS release 6.5 (Final)Kernel \r on an \m [root@host ~]# cat ...
- jap 事务总结
参考: JPA事务总结 2010年4月13日 - 从表11-2中可以看出,对于不同的EntityManager类型与所运行的环境,所支持的事务类型是不一样的. 其中两种情况下最为简单,一种是容器托管的 ...