python 皮尔森相关系数
皮尔森理解
皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
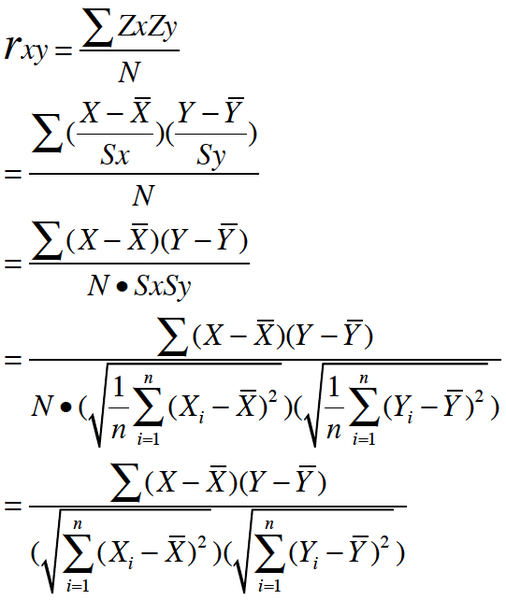
简单的相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。
python 实现
# encoding:utf-8
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
import math
#target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
#rockVMines = pd.read_csv(target_url ,header=None,prefix="V") #prefix前缀
rockVMines = pd.read_csv('../rockdata.txt',header=None,prefix="V") #prefix前缀
row2 = rockVMines.iloc[1,0:60]
row3 = rockVMines.iloc[2,0:60]
n = len(row2)
mean2 = row2.mean()
mean3 = row3.mean()
t2=0 ; t3=0;t1=0
for i in range(n):
t2 += (row2[i] - mean2) * (row2[i] - mean2) / n
t3 += (row3[i] - mean3) * (row3[i] - mean3) / n
r23=0
for i in range(n):
r23 += (row2[i] - mean2)*(row3[i] - mean3)/(n* math.sqrt(t2 * t3))
print r23
corMat = DataFrame(rockVMines.corr()) #corr 求相关系数矩阵
print corMat
plot.pcolor(corMat)
plot.show()
python 皮尔森相关系数的更多相关文章
- Spearman秩相关系数和Pearson皮尔森相关系数
1.Pearson皮尔森相关系数 皮尔森相关系数也叫皮尔森积差相关系数,用来反映两个变量之间相似程度的统计量.或者说用来表示两个向量的相似度. 皮尔森相关系数计算公式如下:
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- spark MLlib 概念 1:相关系数( PPMCC or PCC or Pearson's r皮尔森相关系数) and Spearman's correlation(史匹曼等级相关系数)
皮尔森相关系数定义: 协方差与标准差乘积的商. Pearson's correlation coefficient when applied to a population is commonly r ...
- 相关性系数及其python实现
参考文献: 1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html 2.统计学之三大相关性系数(pearson.spearman.ke ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (二)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- python 推荐算法
每个人都会有这样的经历:当你在电商网站购物时,你会看到天猫给你弹出的“和你买了同样物品的人还买了XXX”的信息:当你在SNS社交网站闲逛时,也会看到弹出的“你可能认识XXX“的信息:你在微博添加关注人 ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (四)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (三)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- Python金融量化
Python股票数据分析 最近在学习基于python的股票数据分析,其中主要用到了tushare和seaborn.tushare是一款财经类数据接口包,国内的股票数据还是比较全的 官网地址:http: ...
随机推荐
- C#项目学习 心得笔记本
CacheDependency 缓存 //创建缓存依赖项 CacheDependency dep = new CacheDependency(fileName); //创建缓存 HttpContext ...
- 利用Metrics+influxdb+grafana构建监控平台(转)
转自http://www.jianshu.com/p/fadcf4d92b0e 这里再配合Influxdb和Grafana可以构建一个非常漂亮的实时监控界面. Grafana监控界面 采集数据(Met ...
- vi 撤销操作
'u' : 撤销上一个编辑操作 'ctrl + r' : 恢复,即回退前一个命令 'U' : 行撤销,撤销所有在前一个编辑行上的操作
- 【CF850E】Random Elections FWT
[CF850E]Random Elections 题意:有n位选民和3位预选者A,B,C,每个选民的投票方案可能是ABC,ACB,BAC...,即一个A,B,C的排列.现在进行三次比较,A-B,B-C ...
- python--利用列表推导式快速生成xml格式数据
在接口自动化测试中,我们经常将要发送的数据放到excel里. json数据放至excel方便,但最近的一个测试,数据是xml格式发送的 如下: 属性 必选/可选 描述 1. Message Eleme ...
- jmeter函数助手之time函数实操
在一个接口测试中,需要提交的请求中要带时间,在看完jmeter帮忙文档,正好总结一下 1.需求 在一个XML请求中请求数据要带有时间,如下 "><ID>/lte/pdeta ...
- xcode vs visual studio
不得不说,VS做的还是不错的,尤其是对C++的debug功能傲视群IDE. 一个VS与XCODE的对比. http://development-software.findthebest.com/com ...
- JDBC改进版
将setObject隐藏,用反射获取model里面的数据 /** * @Date 2016年7月19日 * * @author Administrator */ package com.eshore. ...
- docker swarn集群笔记
.安装Docker 三剑客: curl -L https://github.com/docker/machine/releases/download/v0.10.0/docker-machine-`u ...
- poj3259 Wormholes【最短路-bellman-负环】
While exploring his many farms, Farmer John has discovered a number of amazing wormholes. A wormhole ...