Spark学习笔记6:Spark调优与调试
1、使用Sparkconf配置Spark
对Spark进行性能调优,通常就是修改Spark应用的运行时配置选项。
Spark中最主要的配置机制通过SparkConf类对Spark进行配置,当创建出一个SparkContext时,就需要创建出一个SparkConf实例。
Sparkconf实例包含用户要重载的配置选项的键值对。调用set()方法来添加配置项的设置,然后把这个对象传给SparkContext的构造方法。
调用setAppName()和setMaster()来分别设置spark.app.name和spark.master的值。
例如:
//创建一个conf对象
val conf = new SparkConf()
conf.set("spark.app.name","My Spark App")
conf.set("spark.master","local[4]")
conf.set("spark.ui.port","36000") //使用这个配置对象创建一个SparkContext
val sc = new SparkContext(conf)
Spark运行通过spark-submit工具动态设置配置项。当应用被spark-submit脚本启动时,脚本会把这些配置项设置到运行环境中。
例如:
$ bin/spark-submit \
--class com.example.MyAPP \
--master local[4] \
--name "My Spark App"
--conf spark.ui.port=36000 \
myApp.jar
Spark有特定的优先级顺序来选择实际配置,优先级最高的是在用户代码中显示调用set()方法设置的选项,其次是通过spark-submit传递的参数,再次是写在配置文件中的值,最后是系统的默认值。
2、Spark执行的组成部分:作业、任务和步骤
通过Spark示例展示Spark执行的各个阶段,以了解用户代码如何被编译为下层的执行计划。
val input = sc.textFile("input.txt")
val tokenized = input.map(line => line.split(" ")).filter(words => words.size > 0)
val counts = tokenized.map(words => (words(0),1)).reduceByKey{(a,b) => a+b}
以上示例执行了三次转化操作,最终生成一个叫做counts的RDD。程序定义了一个RDD对象的有向无环图,每个RDD维护了其指向一个或多个父节点的引用,以及表示其与父节点之间关系的信息。
这里counts的谱系图如下:
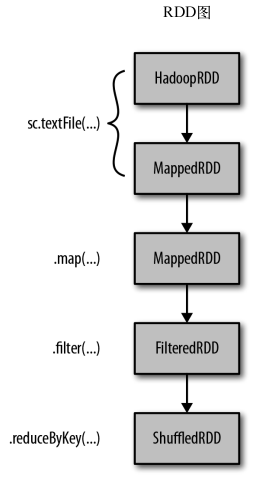
在调用行动操作之前,RDD都只是存储着可以让我们计算出具体数据的描述信息。要触发实际计算,需要对counts调用一个行动操作,比如使用collect()将数据收集到驱动器程序。
counts.collect()
Spark调度器会创建出用于计算行动操作的RDD物理执行计划。Spark调度器从最终需要被调用行动操作的RDD出发,向上回溯所有必须计算的RDD。调度器会访问RDD的父节点,父节点的父节点,以此类推,递归向上生成计算所有必要的祖先RDD的物理计划。如下:
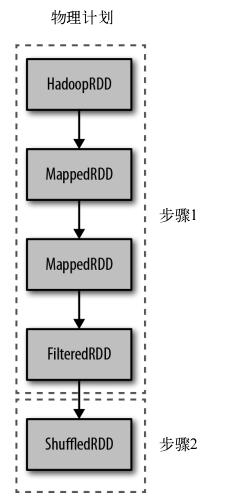
流水线执行:当RDD不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行。在物理执行时,执行计划输出的缩进等级与父节点相同的RDD会与父节点在同一个步骤中进行流水线执行。
除了流水线执行的优化,当一个RDD已经缓存在集群内存或磁盘上时,Spark的内部调度器也会自动截短RDD谱系图。这种情况下,Spark会短路求值,直接基于缓存下来的RDD进行计算。
特定的行动操作所生成的步骤的集合被称为一个作业。
一个物理步骤会启动很多任务,每个任务都是在不同的数据分区上做同样的事情。任务内部的流程是一样的,包括:(1)从数据存储或已有RDD或数据混洗的输出中获取输入数据。(2)执行必要的操作来计算出这些操作所代表的RDD。(3)把输出写到一个数据混洗文件中,写入外部存储或者是发回驱动器程序。
3、Spark优化的关键性能
- 并行度
RDD的逻辑表示其实是一个对象集合。在物理执行期间,RDD会被分为一系列的分区,每个分区都是整个数据的子集。当Spark调度并运行任务时,Spark会为每个分区中的数据创建出一个任务。输入RDD一般会根据其底层的存储系统选择并行度。
并行度会从两方面影响程序的性能:当并行度过低时,Spark集群会出现资源闲置的情况,而当并行度过高时,每个分区产生的间接开销累计起来就会更大。
Spark有两种方法来对操作的并行度进行调优:一种是在数据混洗操作时,使用参数的方式为混洗后的RDD指定并行度。第二种方法是对于任何已有的RDD,可以进行重新分区来获取更多或者更少的分区数。可以使用repartition()实现重新分区操作,该操作会把RDD随机打乱并分成设定的分区数目。使用coalesce()操作没有打乱数据,比repartition()更为高效。
- 序列化格式
当Spark需要通过网络传输数据,或者将数据溢写到磁盘上时,Spark需要把数据序列化为二进制格式。序列化会在数据进行混洗操作时发生,此时有可能需要通过网络传输大量数据。
Spark默认会使用Java内建的序列化库。Spark也支持第三方序列化库Kryo,可以提供比Java的序列化工具更短的序列化时间和更高压缩比的二进制表示。
使用Kryo序列化工具示例如下:
val conf = new SparkConf().setMaster("local").setAppName("partitions")
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
//严格要求注册类 获得最佳性能
conf.set("spark.kryo.registrationRequired","true")
conf.registerKryoClasses(Array(classOf[MyClass],classOf[MyotherClass]))
- 内存管理
Spark内存有以下用途:
- RDD存储,默认占60% 当调用RDD的persist()或cache()方法时,这个RDD的分区会被存储到缓存区中。
- 数据混洗与聚合的缓存区,默认占20% 当进行数据混洗操作时,Spark会创建出一些中间缓存区来存储数据混洗的输出数据。这些缓存区用来存储聚合操作的中间结果以及数据混洗操作中直接输出的部分缓存数据。
- 用户代码,默认占20% Spark可以执行任意的用户代码,用户自行申请大量的内存。
可以通过调整调整内存各区域比例得到更好的性能表现。
其它优化:
Spark默认的cache()操作会以MEMORY_ONLY的存储等级持久化数据,当缓存新的RDD时分区空间不够,旧的分区会被删除。当用到这些分取数据时,在进行重算。使用persist()方法以MEMORY_AND_DISK存储等级存储,内存中放不下的分区会被写入磁盘,需要时再从磁盘读取回来。这种方式会有更好的性能。
还有一种是缓存序列化后的对象而非直接缓存。通过MEMORY_ONLY_SER 或者 MEMORY_AND_DISK_SER的存储等级实现。
- 硬件供给
提供给Spark的硬件资源会显著影响应用的完成时间,影响集群规模的主要参数包括:分配给没各执行器节点的内存大小,每个执行器节点占用的核心数,执行器节点总数,以及用来存储临时数据的本地磁盘数量。
Spark学习笔记6:Spark调优与调试的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
- Spark学习笔记之-Spark远程调试
Spark远程调试 本例子介绍简单介绍spark一种远程调试方法,使用的IDE是IntelliJ IDEA. 1.了解jvm一些参数属性 -X ...
- 学习笔记——JVM性能调优之 jmap
jmap jmap(JVM Memory Map)命令可生成head dump文件,还可查询finalize执行队列.Java堆和永久代的详细信息. 通过配置启动参数:-XX:+HeapDumpOnO ...
- 【Spark深入学习 -14】Spark应用经验与程序调优
----本节内容------- 1.遗留问题解答 2.Spark调优初体验 2.1 利用WebUI分析程序瓶颈 2.2 设置合适的资源 2.3 调整任务的并发度 2.4 修改存储格式 3.Spark调 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark 学习笔记大纲
Spark 内核 第28课:Spark天堂之门解密 (点击进入博客)从 SparkContext 创建3大核心对象开始到注册给 Master 这个过程中的源码鉴赏 第29课:Master HA彻底解密 ...
随机推荐
- get_class
<?phpclass foo { function foo() { // implements some logic } function name() { ...
- Python_常用的正则表达式处理函数
正则表达式就是用查找字符串的,它能查找规则比较复杂的字符串反斜杠:正则表达式里面用"\"作为转义字符. s='<a class="h3" href=&qu ...
- Ajax请求数据的两种方式
ajax 请求数据的两种方法,有需要的朋友可以参考下. 实现ajax 异步访问网络的方法有两个.第一个是原始的方法,第二个是利用jquery包的 原始的方法不用引入jquery包,只需在html中编写 ...
- pycharm中tensorflow代码不能自动补全或import红线问题解决
正确安装并配置好pycharm+tensorflow环境之后,可能在pycharm中导入tensorflow会有以下问题: 1. " import tensorflow as tf &quo ...
- 20155229 2016-2017-2 《Java程序设计》第八周学习总结
20155229 2016-2017-2 <Java程序设计>第八周学习总结 教材学习内容总结 第十四章 NIO使用频道(Channel)来衔接数据节点,在处理数据时,NIO可以设定缓冲区 ...
- BZOJ4897: [Thu Summer Camp2016]成绩单【DP of DP】
Description 期末考试结束了,班主任L老师要将成绩单分发到每位同学手中.L老师共有n份成绩单,按照编号从1到n的顺序叠 放在桌子上,其中编号为i的成绩单分数为w_i.成绩单是按照批次发放的. ...
- CSU 1112: 机器人的指令
1112: 机器人的指令 Submit Page Description 数轴原点有一个机器人.该机器人将执行一系列指令,你的任务是预测所有指令执行完毕之后它的位置. ·LEFT:往 ...
- 对象Date的方法
Date()对象是js提供给我们的日期对象,可以利用它获取关于时间的量. var myDate = new Date() //首先构造一个时间对象,然后用对象的方法获取时间: 1.获取年份: var ...
- NSObject之二
前面一章我们整理了NSObject类,这一章我们来看看NSObject协议的内容. NSObject协议提供了一组方法作为Objective-C对象的基础.其实我们对照一个NSObject类和NSOb ...
- CTF之LSB信息隐藏术
LSB也就是最低有效位,原理是图片中的像素一般是由三种颜色构成,即三原色(绿红蓝),由这三种颜色可以组成其它各种颜色. 例如在PNG图片的储存中,每个颜色会有8bit,LSB隐写就是修改了像素中的最低 ...