(转) Ringbuffer为什么这么快?
原文地址:http://ifeve.com/ringbuffer/
最近,我们开源了LMAX Disruptor,它是我们的交易系统吞吐量快(LMAX是一个新型的交易平台,号称能够单线程每秒处理数百万的订单)的关键原因。为什么我们要将其开源?我们意识到对高性能编程领域的一些传统观点,有点不对劲。我们找到了一种更好、更快地在线程间共享数据的方法,如果不公开于业界共享的话,那未免太自私了。同时开源也让我们觉得看起来更酷。
从这个站点,你可以下载到一篇解释什么是Disruptor及它为什么如此高性能的文档。这篇文档的编写过程,我并没有参与太多,只是简单地插入了一些标点符号和重组了一些我不懂的句子,但是非常高兴的是,我仍然从中提升了自己的写作水平。
我发现要把所有的事情一下子全部解释清楚还是有点困难的,所有我准备一部分一部分地解释它们,以适合我的NADD听众。
首先介绍ringbuffer。我对Disruptor的最初印象就是ringbuffer。但是后来我意识到尽管ringbuffer是整个模式(Disruptor)的核心,但是Disruptor对ringbuffer的访问控制策略才是真正的关键点所在。
ringbuffer到底是什么?
嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
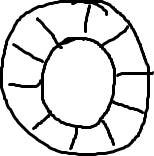
(好吧,这是我通过画图板手画的,我试着画草图,希望我的强迫症不会让我画完美的圆和直线)
基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。(校对注:如下图右边的图片表示序号,这个序号指向数组的索引4的位置。)
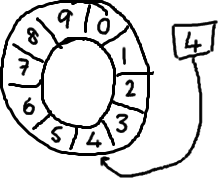
随着你不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。
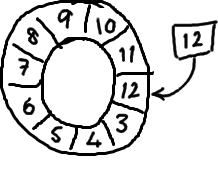
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
(校对注:2的N次方换成二进制就是1000,100,10,1这样的数字, sequence & (array length-1) = array index,比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快。)
那又怎么样?
如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。我们需要将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们。
听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息:

我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分–如果你等不急我写blog来说明它们,那么可以自行检出Disruptor项目)。
它为什么如此优秀?
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
缺少的部分
我并没有在本文中介绍如何避免ringbuffer产生重叠,以及如何对ringbuffer进行读写操作。你可能注意到了我将ringbuffer和链表那样的数据结构进行比较,因为我并认为链表是实际问题的标准答案。
当你将Disruptor和基于 队列之类的实现进行比较时,事情将变得很有趣。队列通常注重维护队列的头尾元素,添加和删除元素等。所有的这些我都没有在ringbuffer里提到,这是因为ringbuffer不负责这些事情,我们把这些操作都移到了数据结构(ringbuffer)的外部
到这个站点阅读文章或者检出代码可以了解更多细节。或者观看Mike 和Martin在去年San Francisco QCon大会上的视频,或者再等我一些时间来思考剩下的东西,然后在接下来的blog中逐一介绍。
原创文章,转载请注明: 转载自并发编程网 – ifeve.com
附:canal EventStore中采用的RingBuffer的设计思想
Memory内存的RingBuffer设计:

借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
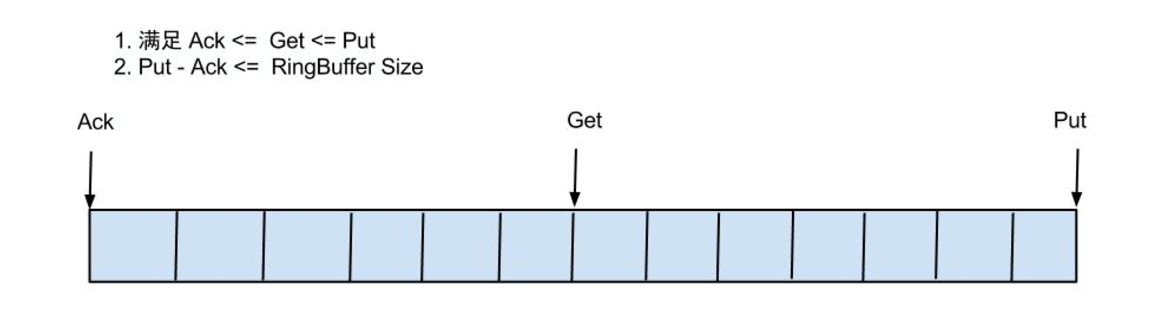
- Put/Get/Ack 用于递增,采用long型存储,这三种方式这里统称为cusor。put的指针要“先”于get。
- buffer的get操作,通过取余或者与操作。(与操作: cusor & (size – 1) , size需要为2的指数,效率比较高)
(转) Ringbuffer为什么这么快?的更多相关文章
- Disruptor 为什么这么快?
为什么Disruptor不使用队列来实现RingBuffer 队列有两个指针,一个指向队头,一个指向队尾.如果有超过一个生产者想要往队列里放东西,尾指针就将成为一个冲突点,因为有多个线程要更新它. ...
- 【Disruptor】之Ringbuffer
一.Ringbuffer的概念 =>是一个环形数据队列的数据结构 =>嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer. =& ...
- Disruptor Ringbuffer
系列译文: http://ifeve.com/disruptor/ 当有多个消费者时,(按Disruptor的设计)每个消费者各自控制自己的指针,依次读取每个Slot(也就是每个消费者都会读取到所有的 ...
- 高性能队列disruptor为什么这么快?
背景 Disruptor是LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级).基于Disruptor开发的系统单线程能支撑每秒600万 ...
- 物联网安全himqtt防火墙数据结构之ringbuffer环形缓冲区
物联网安全himqtt防火墙数据结构之ringbuffer环形缓冲区 随着5G的普及,物联网安全显得特别重要,himqtt是首款完整源码的高性能MQTT物联网防火墙 - MQTT Applicatio ...
- 从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
1.lmax-Disruptor队列介绍 disruptor是英国著名的金融交易所lmax旗下技术团队开发的一款java实现的高性能内存队列框架 其发明disruptor的主要目的是为了改进传统的内存 ...
- .NET平台开源项目速览(14)最快的对象映射组件Tiny Mapper
好久没有写文章,工作甚忙,但每日还是关注.NET领域的开源项目.五一休息,放松了一下之后,今天就给大家介绍一个轻量级的对象映射工具Tiny Mapper:号称是.NET平台最快的对象映射组件.那就一起 ...
- 【NLP】十分钟快览自然语言处理学习总结
十分钟学习自然语言处理概述 作者:白宁超 2016年9月23日00:24:12 摘要:近来自然语言处理行业发展朝气蓬勃,市场应用广泛.笔者学习以来写了不少文章,文章深度层次不一,今天因为某种需要,将文 ...
- java中if和switch哪个效率快
首先要看一个问题,if 语句适用范围比较广,只要是 boolean 表达式都可以用 if 判断:而 switch 只能对基本类型进行数值比较.两者的可比性就仅限在两个基本类型比较的范围内.说到基本类型 ...
随机推荐
- linux下一个启动和监测多个进程的shell脚本程序
#!/bin/sh# Author:tang# Date:2017-09-01 ProcessName=webcrawlerInstanceCount=6RuntimeLog='runtime.log ...
- ORA-03113:通信通道的文件结尾
问题: 用命令startup启动实例时,报错“ORA-03113:通信通道的文件结尾”. 解决: SQL> startup mount ORACLE 例程已经启动. Total System G ...
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- Spring学习之AOP详解
aop使用方式 @Aspect注解 wildcards通配符: * 匹配任意数量的字符 + 匹配指定类及其子类 .. 一般用于匹配任意数的子包或参数 operators运算符 && 与 ...
- Linux 各类设置、配置、使用技巧参考,Linux使用集锦
========== 参考格式 (新增记录时,复制粘贴在下)============= [日期]: <标题> 参考链接ref1: 参考链接ref2: 正文: ========== 参考格式 ...
- 46. linux下解压.tar.gz文件
tar -zxvf jdk-7u55-linux-i586.tar.gz 步骤二:解压jdk-7u55-linux-i586.tar.gz ,执行以下命令: #mkdir /usr/local/jav ...
- JAVA JDBC 各大数据库的连接字符串和连接类
oracle: driverClass:oracle.jdbc.OracleDriver url:jdbc:oracle:thin:@127.0.0.1:1521:dbname mys ...
- node 图片上传功能
node 代码: var http = require("http"); var express = require('express') app = express(), for ...
- sftp(paramiko)
SFTP同样是使用加密传输认证信息和传输的数据,所以,使用SFTP是非常安全的.但是,由于这种传输方式使用了加密/解密技术,所以传输效率比普通的FTP要低得多,如果您对网络安全性要求更高时,可以使用S ...
- 14 MySQL--事务&函数与流程控制
一.事务 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性. 一堆sql语句:要么同时执行成功,要么同时失败 # 事务的原子性 场景: ...