关于git使用的几点理解
1.git为分布式的版本控制系统,有远程仓库和本地仓库,远程仓库和本地仓库之间建立关联关系后,可将本地仓库的更新push(相当于是内容同步)到远程仓库进行保存,远程仓库的作用相当于一个最终代码备份的地方;
2.git之所以称作分布式的版本控制系统,就是因为git本地仓库的作用,无需连接远程仓库,开发人员即可直接使用本地仓库完成代码在本地仓库中的提交和版本控制,就相当于在本地有一个完全独立的属于自己的版本控制系统。最后只需要在合适的时候,将本地仓库的相应分支推送到远程仓库进行更新同步即可;
3.创建本地仓库的主要方式:
1).从远程仓库克隆,使用git clone 命令将远程仓库克隆到本地的一个文件夹后,即会建立一个和远程仓库有关联的本地仓库,并且默认也会在本地仓库中创建master分支,也会将本地的master分支和远程仓库的master分支进行关联(即建立追踪关系);
2)直接从本地使用git init命令进行创建,即在一个文件夹下使用git init命令后,在该文件夹下将生成一个名为.git的隐藏文件夹(该文件夹为git的版本库),有.git文件夹的目录及其子目录中的所有文件将会被git进行跟踪管理(git能够跟踪管理的是文本文件的修改,删除),存在.git隐藏文件夹的文件夹即为本地仓库;
本地仓库建好后,使用 git remote add origin git@gitlab.com:XXX/XXX.git 命令添加一个远程仓库(即和一个远程仓库建立关联关系后将代码push到远程),如果该远程仓库已经存在,则直接建立联系,如果不存在则会在远程创建一个名字为XXX.git的仓库(添加远程仓库,最后git push后就会创建);
4.git仓库的结构
由工作区和版本库构成,如下图:
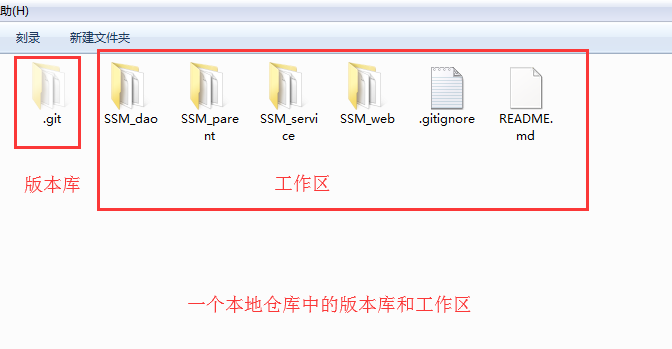
工作区:就是电脑里能看到的目录,比如上图中的除了.git文件夹之外的所有文件夹及其子目录就属于工作区,这里是开发中存储并修改文件的区域,只要工作区的内容一更新,git就能跟踪到变化。工作区的内容和版本库中的内容是保持同步的,就是通过比较工作区和版本库中的内容来确定工作区中是否有更改内容。
版本库:工作区中有一个隐藏目录.git,就是Git的版本库,这个目录是Git来跟踪管理版本的,版本库里存放了已提交的版本,另外其中比较重要的还有state(或者叫index)的暂存区, 还有Git为我们自动创建的第一个分支master(我们在仓库中的工作空间,可以看做是仓库的最小单元,我们所有的操作都是在一个分支上进行的,分支和分支之间是独立的),以及指向master的一个指针叫HEAD。

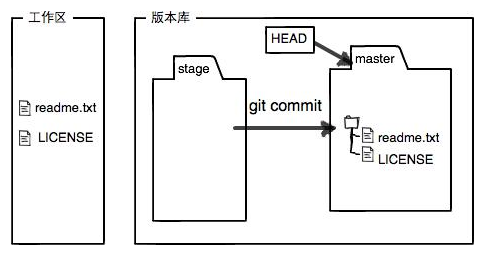
暂存区(stage):在commit之前暂时存放修改文件的地方。所有需要commit的文件首先都需要加入到暂存区中后才能进行commit.
将文件提交到版本库中需分两步执行:
第一步:使用git add命令将工作区中的修改了的文件添加到暂存区;

第二步:使用git commit命令将暂存区的所有修改文件提交到当前分支(注意提交是提交到某个分支),没有在处在暂存区的修改将不会被提交;
5.git是通过每次commit作为节点进行版本记录。每次commit后都会记录commit时的时间,还会生成一个commit id ,通过id可进行版本的还原。
6.分支:是仓库中的构成单元,仓库中会存在很多分支,我们都是在某一个分支上进行工作(我们工作时都是先进入到仓库的某一个分支后,然后在该分支上执行各种git命令),分支可以理解为不同的工作区(或工作场景),每个分支都对应有自己的工作区文件内容, 切换分支后,工作区中的文件内容也会对应做改变。在某个分支下新建一个分支其实就是基于该分支的当前节点拷贝了一个新的工作区。 有了分支的概念后,我们所使用的git commit, git pull,git push 等命令都是相对于分支来讲的。
7.git 的几个命令的理解:
git commit 将所有暂存区中的修改内容提交到当前分支版本库保存
git push 远程主机名 本地分支 :远程分支 将本地仓库中的某一个分支内容推送到一个远程分支下,如 git push origin test : dev,将本地的test分支内容推送到远程的dev分支下,test分支的内容作为dev分支下的内容。如果远程分支dev不存在,将会在远程创建一个名为dev的分支。一般本地分支名称和远程分支名称是相同的,所以这里一般可以不写远程分支名称,即直接写成:git push origin test ,会将test分支的更新内容自动推送到远程的test分支下,如果不存在,则在远程会创建一个名为 test的分支。如果本地和远程分支的名称不一样,则需要按照前面的写法进行分支名称的对应。git push时是将commit后的更改内容push到远程分支中,并不是所有。git push命令随时可以使用,不受是否存在未commit 或 未add的文件影响。
git pull 远程主机名 远程分支:本地分支 将远程的某一分支内容获取到后和本地指定的分支进行合并。如 git pull origin test:dev,获取远程的test分支和本地的dev分支进行合并,如果本地的指定的dev分支不存在,则默认会创建一个dev分支。
上面 “本地分支 :远程分支 ”这种就是在push或pull时建立了本地分支和远程分支之间的对应关系。也就是说我们要push或pull的时候,要搞清楚从哪里来,到哪里去。我们在初学时要建立本地远程库和库之间对应,分支和分支对应这样的概念。这样使用push 或 pull 之类的命令时就感觉很清晰。
以上只是个人初学git时的一些浅薄的理解,是对自己学习过程的一个记录。详细可参考以下大神的一些总结文章:
Git使用总结(包含Git Bash和Git GUI的使用)
Git Bash使用详细教程
关于git使用的几点理解的更多相关文章
- 【原创】关于Git暂存区的理解
关于Git暂存区的理解 暂存区可以说是Git的三大重要的区域之一,另外两个分别是工作目录和Git仓库,所以说对暂存区的深入理解可以帮助我们理解很多Git命令背后隐藏的工作原理.今天,本文将以 ...
- 关于git提交的自己的理解
包子不才,对于码云上的git的使用,自己的理解是 这个命令用于查看,哪些文件被修改了,以及修改了哪些地方, 这个命令用于增加你新添的文件,如果该文件已经存在,那么这一步则可以省略,随后就是commit ...
- git 4种对象的理解
git中有四种基本对象类型,可以说Git的所有操作都是通过这四种对象完成的.下图是<Git版本控制管理>中文第二版的原话,顺便吐槽一下,这本书真的翻译的一般.. 下面说下我的理解吧,首先b ...
- 【Git 学习三】深入理解git reset 命令
重置命令(git reset)是Git 最常用的命令之一,也是最危险最容易误用的命令.来看看git reset命令用法. --------------------------------------- ...
- 我对git的快速使用和理解
收藏较好的,分享给大家 https://mp.weixin.qq.com/s/k4tU8snvssyKJ2WkvkFrZA
- git plumbing 更加底层命令解析-深入理解GIT
原文: http://rypress.com/tutorials/git/plumbing 本文详细介绍GIT Plumbing--更加底层的git命令,你将会对git在内部是如何管理和呈现一个项目r ...
- 理解 Git
Git 如何保存文件 其它版本管理系统通常会保存所有文件及其历次提交的差异(diff / revision),通过 merge 原始文件与各阶段的差异就能获取任何版本的状态 而 Git 保存的是每一次 ...
- 版本控制Git(1)——理解暂存区
一.svn和Git的比较 我们都知道传统的源代码管理都是以服务器为中心的,每个开发者都直接连在中间服务器上, 本地修改,然后commit到svn服务器上.这种做法看似完美,但是有致命的缺陷. 1. 开 ...
- git的使用理解(分支合并的使用理解,多人编程的解决方案)
本文主要记录了对git日常使用的一些理解,主要是对git分支的一些感悟. git强大的版本控制系统,之前也使用过SVN,感觉上git对于多人开发的版本控制更加强大,特别是最近对git分支的使用,更是深 ...
随机推荐
- 理解MySQL(一)--MySQL介绍
一.Mysql逻辑架构: 1. 第一层:服务器层的服务,连接\线程处理. 2. 第二层:查询执行引擎,MySQL的核心服务功能,包括查询解析.分析.优化和缓存,所有跨存储引擎的功能都在这一层实现. 3 ...
- PDF.js 详情解说
pdf.js资源下载 点我下载 自定义默认加载的pdf资源 在web/view.js中我们可以通过DEFAULT_URL设置默认加载的pdf.通过上面代码我们也可以看出来可以通过后缀名来指定加载的pd ...
- Unity进阶之ET网络游戏开发框架 08-深入登录成功消息
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- Python爬虫运用正则表达式
我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东 ...
- int string类型互转
int -> String int i=12345;String s="";第一种方法:s=i+"";第二种方法:s=String.valueOf(i); ...
- sql server中的cte
从SQL Server 2005开始,提供了CTE(Common Table Expression,公用表表达式)的语法支持. CTE是定义在SELECT.INSERT.UPDATE或DELETE语句 ...
- Java基础部分-面试题
1.java中的数据类型有哪些? 数据类型主要分为基本数据类型和引用数据类型. 基本数据类型主要包括: 整数类型: byte.short.int.long 浮点数:float.double 布尔类型: ...
- HillCrest Sensor HAL
1. 抽象定义 Google为Sensor提供了统一的HAL接口,不同的硬件厂商需要根据该接口来实现并完成具体的硬件抽象层,Android中Sensor的HAL接口定义在:hardware/libha ...
- Hadoop RPC机制详解
网络通信模块是分布式系统中最底层的模块,他直接支撑了上层分布式环境下复杂的进程间通信逻辑,是所有分布式系统的基础.远程过程调用(RPC)是一种常用的分布式网络通信协议,他允许运行于一台计算机的程序调用 ...
- python 27 异常处理
目录 异常处理 1. 错误分类 2. 异常 3. 异常处理 4. 异常处理的两种方法 5. try的结构 5.1 结构一:单分支结构 5.2 结构二:多分支结构 5.3 结构三:万能异常 5.4 结构 ...