HashSet源码解读
一:先看其实现了哪些接口和继承了哪些类
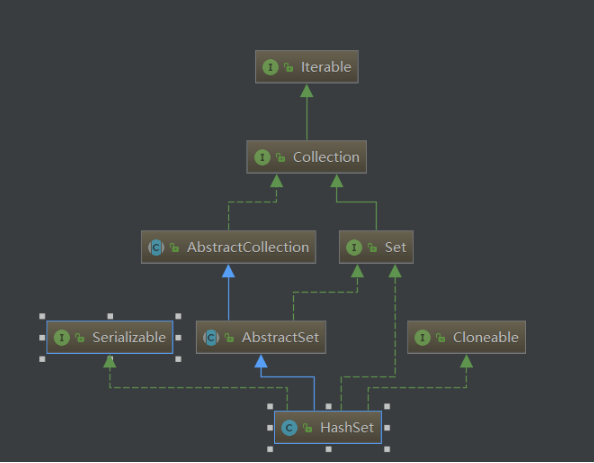
1.实现了Serializable接口,表明它支持序列化。
2.实现了Cloneable接口,表明它支持克隆,可以调用超类的clone()方法进行浅拷贝。
3.继承了AbstractSet抽象类,和ArrayList和LinkedList一样,在他们的抽象父类中,都提供了equals()方法和hashCode()方法。它们自身并不实现这两个方法
4.从JDK源码可以看出,底层并没有使用我们常规认为的利用hashcode()方法求的值进行比较,而是通过调用AbstractCollection的containsAll()方法,如果他们中元素完全相同(与顺序无关),则他们的equals()方法的比较结果就为true。
/**
* Compares the specified object with this set for equality. Returns
* <tt>true</tt> if the given object is also a set, the two sets have
* the same size, and every member of the given set is contained in
* this set. This ensures that the <tt>equals</tt> method works
* properly across different implementations of the <tt>Set</tt>
* interface.<p>
*
* This implementation first checks if the specified object is this
* set; if so it returns <tt>true</tt>. Then, it checks if the
* specified object is a set whose size is identical to the size of
* this set; if not, it returns false. If so, it returns
* <tt>containsAll((Collection) o)</tt>.
*
* @param o object to be compared for equality with this set
* @return <tt>true</tt> if the specified object is equal to this set
*/
public boolean equals(Object o) {
if (o == this)
return true; if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
//保证个数相等
if (c.size() != size())
return false;
try {
//调用了AbstractCollection的方法。
return containsAll(c);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public boolean containsAll(Collection<?> c) {
//只需要逐个判断集合是否包含其中的元素。
for (Object e : c)
if (!contains(e))
return false;
return true;
}
4.实现了Set接口。
二:HashSet概述
1.HashSet是通过HashMap的键来存值,HashMap里面的所有值都为null;
2.学习这个之前先看HashMap;附上网址https://www.cnblogs.com/xhlwjy/p/11246618.html
三:HashSet的属性
private transient HashMap<E,Object> map;//用HashMap的Key来存值
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();//用于填充HashMap的value
四:构造方法
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
//这个是初始化一个HashMap
public HashSet() {
map = new HashMap<>();
} /**
* Constructs a new set containing the elements in the specified
* collection. The <tt>HashMap</tt> is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
//初始化HashMap,把c集合中的所有元素添加到map中
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
} /**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
//初始化HashMap的容量和加载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
} /**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
//初始化HashMap的容量
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
} /**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
//这个初始化使用的是LinkedHashMap
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
五:添加新元素
//底层仍然利用了HashMap键进行了元素的添加。
//在HashMap的put()方法中,该方法的返回值是对应HashMap中键值对中的值,而值总是PRESENT,
//该PRESENT一直都是private static final Object PRESENT = new Object();
//PRESENT只是初始化了,并不能改变,所以PRESENT的值一直为null。
//所以只要插入成功了,put()方法返回的值总是null。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
这段代码就不分析了,与HashMap的插入差不多,可以先去看HashMap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
六:删除一个元素
//该方法底层实现了仍然使用了map的remove()方法。
//map的remove()方法的返回的是被删除键对应的值。(在HashSet的底层HashMap中的所有键值对的值都是PRESENT)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
之后的代码就不粘贴出来了,自己可以去源码里面看
七:清空方法
public void clear() {
map.clear();
}
八:克隆方法
底层仍然使用了Object的clone()方法,得到的Object对象,并把它强制转化为HashSet<E>,然后把它的底层的HashMap也克隆一份(调用的HashMap的clone()方法),并把它赋值给newSet,最后返回newSet即可。
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
九:是否包含某个元素
底层使用了HashMap的containsKey()
public boolean contains(Object o) {
return map.containsKey(o);
}
十:判读是不是空
调用HashMap的方法
public boolean isEmpty() {
return map.isEmpty();
}
十一:统计HashSet中包含元素的个数
public int size() {
return map.size();
}
十二:生成迭代器
public Iterator<E> iterator() {
return map.keySet().iterator();
}
十三:序列化
/**
* Save the state of this <tt>HashSet</tt> instance to a stream (that is,
* serialize it).
*
* @serialData The capacity of the backing <tt>HashMap</tt> instance
* (int), and its load factor (float) are emitted, followed by
* the size of the set (the number of elements it contains)
* (int), followed by all of its elements (each an Object) in
* no particular order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject(); // Write out HashMap capacity and load factor
//容量写入流
s.writeInt(map.capacity());
//加载因子写入流
s.writeFloat(map.loadFactor()); // Write out size
//存放的数量写入流
s.writeInt(map.size()); // Write out all elements in the proper order.
//把每个元素写入流
for (E e : map.keySet())
s.writeObject(e);
}
十四:反序列化
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject(); // Read capacity and verify non-negative.
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
} // Read load factor and verify positive and non NaN.
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
} // Read size and verify non-negative.
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY); //HashMap中构建哈希桶数组是在第一个元素被添加的时候才构建,所以在构建之前检查它,
// 调用HashMap.tableSizeFor来计算实际分配的大小,
// 检查Map.Entry []类,因为它是最接近的公共类型实际创建的内容。 SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class,HashMap.tableSizeFor(capacity)); //创建HashMap。
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor)); // 按写入流中的顺序再把元素依次读取出来放到map中。
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
HashSet源码解读的更多相关文章
- JDK容器类List,Set,Queue源码解读
List,Set,Queue都是继承Collection接口的单列集合接口.List常用的实现主要有ArrayList,LinkedList,List中的数据是有序可重复的.Set常用的实现主要是Ha ...
- jdk1.8.0_45源码解读——HashSet的实现
jdk1.8.0_45源码解读——HashSet的实现 一.HashSet概述 HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.主要具有以下的特点: 不保证set的迭代顺 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- HttpClient 4.3连接池参数配置及源码解读
目前所在公司使用HttpClient 4.3.3版本发送Rest请求,调用接口.最近出现了调用查询接口服务慢的生产问题,在排查整个调用链可能存在的问题时(从客户端发起Http请求->ESB-&g ...
- ThreadPoolExecutor源码解读
1. 背景与简介 在Java中异步任务的处理,我们通常会使用Executor框架,而ThreadPoolExecutor是JUC为我们提供的线程池实现. 线程池的优点在于规避线程的频繁创建,对线程资源 ...
- jdk1.8.0_45源码解读——Set接口和AbstractSet抽象类的实现
jdk1.8.0_45源码解读——Set接口和AbstractSet抽象类的实现 一. Set架构 如上图: (01) Set 是继承于Collection的接口.它是一个不允许有重复元素的集合.(0 ...
- MyBatis源码解读之延迟加载
1. 目的 本文主要解读MyBatis 延迟加载实现原理 2. 延迟加载如何使用 Setting 参数配置 设置参数 描述 有效值 默认值 lazyLoadingEnabled 延迟加载的全局开关.当 ...
- HttpClient4.3 连接池参数配置及源码解读
目前所在公司使用HttpClient 4.3.3版本发送Rest请求,调用接口.最近出现了调用查询接口服务慢的生产问题,在排查整个调用链可能存在的问题时(从客户端发起Http请求->ESB-&g ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
随机推荐
- UITableViewStyleGrouped 设置表头出现section不为0的问题
UITableViewStyleGrouped 设置表头出现section不为0的问题 1.如果使用UITableViewStylePlain样式的表格,那么header是会在表格滑动的时候在顶部悬浮 ...
- PHP调用语音合成接口
百度TTS 语音合成 //百度文件转换成语音 private function toSpeech($text) { define('DEMO_CURL_VERBOSE', false); $obj=[ ...
- 条款10:令operator= 返回一个reference to *this
关于赋值,可以写成连锁形式: int x, y, z; x = y = z = 15; //赋值连锁形式 赋值采用右结合律,故上述赋值被解析为: x = (y = (z = 15)); 为了实现连锁赋 ...
- Tuxera NTFS 2018 for Mac中文破解版 U盘读写软件-让你的Mac支持NTFS
下载链接(复制到浏览器下载):http://h5ip.cn/TLMc 软件介绍 给大家带来一款苹果Mac上如何使用U盘读写的软件,Tuxera NTFS 2018 for Mac中文破解版,Mac O ...
- Redis 学习笔记(篇一):字符串和链表
本次学习除了基本内容之外主要思考三个问题:why(为什么).what(原理是什么).which(同类中还有哪些类似的东西,相比有什么区别). 由于我对 java 比较熟悉,并且 java 中也有字符串 ...
- 使用事件注册器进行swoole代码封装
在使用swoole的时候,事件回调很难维护与编写,写起来很乱.特别在封装一些代码的时候,使用这种注册,先注册用户自己定义的,然后注册些默认的事件函数. Server.php class Server ...
- maven的下载与安装,卸载替换eclipse自带的maven
首先呢,博主在这里给大家一个建议,最好不要用eclipse自带的maven.因为这家伙总会出现一些这样那样的错误,比如常见的jar包下载不全或者是install打包报错等等. 博主用了一段时间,还是觉 ...
- Matplotlib快速入门
Matplotlib 可能还有小伙伴不知道Matplotlib是什么,下面是维基百科的介绍. Matplotlib 是Python编程语言的一个绘图库及其数值数学扩展 NumPy.它为利用通用的图形用 ...
- python多线程爬取图片实例
今天试着把前面那个爬取图片的爬虫改成了多线程爬取,虽然最后可以爬取存储图片了,但仍存在一些问题.网址还是那个网址https://www.quanjing.com/category/1286521/1. ...
- SQL中的LIKE语句的用法
SQL中的LIKE语句的用法 内容 在SQL结构化查询语言中,LIKE语句有着至关重要的作用.LIKE语句的语法格式是:select * from 表名 where 字段名 like 对应值(子串), ...