识别手写数字增强版100% - pytorch从入门到入道(一)
手写数字识别,神经网络领域的“hello world”例子,通过pytorch一步步构建,通过训练与调整,达到“100%”准确率
1、快速开始
1.1 定义神经网络类,继承torch.nn.Module,文件名为digit_recog.py
import torch.nn as nn class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(1, 6, 5, 1, 2)
, nn.ReLU()
, nn.MaxPool2d(2, 2))
self.conv2 = nn.Sequential(nn.Conv2d(6, 16, 5)
, nn.ReLU()
, nn.MaxPool2d(2, 2))
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
# nn.Dropout2d(),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.Dropout2d(),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10) # 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# 线性层的输入输出都是一维数据,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
上面的类定义了一个3层的网络结构,根据问题类型,最后一层是确定的

1.2 开始训练:
import torch
import torchvision as tv
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import os
import copy
import time
from digit_recog import Net
from digit_recog_mydataset import MyDataset # 读取已保存的模型
def getmodel(pth, net):
state_filepath = pth
if os.path.exists(state_filepath):
# 加载参数
nn_state = torch.load(state_filepath)
# 加载模型
net.load_state_dict(nn_state)
# 拷贝一份
return copy.deepcopy(nn_state)
else:
return net.state_dict() # 构建数据集
def getdataset(batch_size):
# 定义数据预处理方式
transform = transforms.ToTensor() # 定义训练数据集
trainset = tv.datasets.MNIST(
root='./data/',
train=True,
download=True,
transform=transform) # 去掉注释,加入自己的数据集
# trainset += MyDataset(os.path.abspath("./data/myimages/"), 'train.txt', transform=transform) # 定义训练批处理数据
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
) # 定义测试数据集
testset = tv.datasets.MNIST(
root='./data/',
train=False,
download=True,
transform=transform) # 去掉注释,加入自己的数据集
# testset += MyDataset(os.path.abspath("./data/myimages/"), 'test.txt', transform=transform) # 定义测试批处理数据
testloader = torch.utils.data.DataLoader(
testset,
batch_size=batch_size,
shuffle=False,
) return trainloader, testloader # 训练
def training(device, net, model, dataset_loader, epochs, criterion, optimizer, save_model_path):
trainloader, testloader = dataset_loader
# 最佳模型
best_model_wts = model
# 最好分数
best_acc = 0.0
# 计时
since = time.time()
for epoch in range(epochs):
sum_loss = 0.0
# 训练数据集
for i, data in enumerate(trainloader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 梯度清零,避免带入下一轮累加
optimizer.zero_grad()
# 神经网络运算
outputs = net(inputs)
# 损失值
loss = criterion(outputs, labels)
# 损失值反向传播
loss.backward()
# 执行优化
optimizer.step()
# 损失值汇总
sum_loss += loss.item()
# 每训练完100条数据就显示一下损失值
if i % 100 == 99:
print('[%d, %d] loss: %.03f'
% (epoch + 1, i + 1, sum_loss / 100))
sum_loss = 0.0
# 每训练完一轮测试一下准确率
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的
_, predicted = torch.max(outputs.data, 1)
# print(labels)
# print(torch.nn.Softmax(dim=1)(outputs.data).detach().numpy()[0])
# print(torch.nn.functional.normalize(outputs.data).detach().numpy()[0])
total += labels.size(0)
correct += (predicted == labels).sum() print('测试结果:{}/{}'.format(correct, total))
epoch_acc = correct.double() / total
print('当前分数:{} 最高分数:{}'.format(epoch_acc, best_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(net.state_dict())
print('第%d轮的识别准确率为:%d%%' % (epoch + 1, (100 * correct / total))) time_elapsed = time.time() - since
print('训练完成于 {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('最高分数: {:4f}'.format(best_acc))
# 保存训练模型
if save_model_path is not None:
save_state_path = os.path.join('model/', 'net.pth')
torch.save(best_model_wts, save_state_path) # 基于cpu还是gpu
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
NET = Net().to(DEVICE)
# 超参数设置
EPOCHS = 8# 训练多少轮
BATCH_SIZE = 64 # 数据集批处理数量 64
LR = 0.001 # 学习率 # 交叉熵损失函数,通常用于多分类问题上
CRITERION = nn.CrossEntropyLoss()
# 优化器
# OPTIMIZER = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
OPTIMIZER = optim.Adam(NET.parameters(), lr=LR)
MODEL = getmodel(os.path.join('model/', 'net.pth'), NET)
training(DEVICE, NET, MODEL, getdataset(BATCH_SIZE), 1, CRITERION, OPTIMIZER, os.path.join('model/', 'net.pth'))
利用标准的mnist数据集跑出来的识别率能达到99%
2、参与进来
目的是为了识别自己的图片,增加参与感
2.1 打开windows附件中的画图工具,用鼠标画几个数字,然后用截图工具保存下来

2.2 实现自己的数据集:
digit_recog_mydataset.py
from PIL import Image
import torch
import os # 实现自己的数据集
class MyDataset(torch.utils.data.Dataset):
def __init__(self, root, datafile, transform=None, target_transform=None):
super(MyDataset, self).__init__()
fh = open(os.path.join(root, datafile), 'r')
datas = []
for line in fh:
# 删除本行末尾的字符
line = line.rstrip()
# 通过指定分隔符对字符串进行拆分,默认为所有的空字符,包括空格、换行、制表符等
words = line.split()
# words[0]是图片信息,words[1]是标签
datas.append((words[0], int(words[1]))) self.datas = datas
self.transform = transform
self.target_transform = target_transform
self.root = root # 必须实现的方法,用于按照索引读取每个元素的具体内容
def __getitem__(self, index):
# 获取图片及标签,即上面每行中word[0]和word[1]的信息
img, label = self.datas[index]
# 打开图片,重设尺寸,转换为灰度图
img = Image.open(os.path.join(self.root, img)).resize((28, 28)).convert('L') # 数据预处理
if self.transform is not None:
img = self.transform(img)
return img, label # 必须实现的方法,返回数据集的长度
def __len__(self):
return len(self.datas)
2.3 在图片文件夹中新建两个文件,train.txt和test.txt,分别写上训练与测试集的数据,格式如下

训练与测试的数据要严格区分开,否则训练出来的模型会有问题
2.4 加入训练、测试数据集
反注释训练方法中的这两行
# trainset += MyDataset(os.path.abspath("./data/myimages/"), 'train.txt', transform=transform)
# testset += MyDataset(os.path.abspath("./data/myimages/"), 'test.txt', transform=transform)
继续执行训练,这里我训练出来的最高识别率是98%
2.5 测试模型
# -*- coding: utf-8 -*-
# encoding:utf-8 import torch
import numpy as np
from PIL import Image
import os
import matplotlib
import matplotlib.pyplot as plt
import glob
from digit_recog import Net device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = Net().to(device)
# 加载参数
nn_state = torch.load(os.path.join('model/', 'net.pth'))
# 参数加载到指定模型
net.load_state_dict(nn_state) # 指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family'] = 'sans-serif'
# 解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False # 要识别的图片
file_list = glob.glob(os.path.join('data/test_image/', '*'))
grid_rows = len(file_list) / 5 + 1 for i, file in enumerate(file_list):
# 读取图片并重设尺寸
image = Image.open(file).resize((28, 28))
# 灰度图
gray_image = image.convert('L')
# 图片数据处理
im_data = np.array(gray_image)
im_data = torch.from_numpy(im_data).float()
im_data = im_data.view(1, 1, 28, 28)
# 神经网络运算
outputs = net(im_data)
# 取最大预测值
_, pred = torch.max(outputs, 1)
# print(torch.nn.Softmax(dim=1)(outputs).detach().numpy()[0])
# print(torch.nn.functional.normalize(outputs).detach().numpy()[0])
# 显示图片
plt.subplot(grid_rows, 5, i + 1)
plt.imshow(gray_image)
plt.title(u"你是{}?".format(pred.item()), fontsize=8)
plt.axis('off') print('[{}]预测数字为: [{}]'.format(file, pred.item())) plt.show()
可视化结果
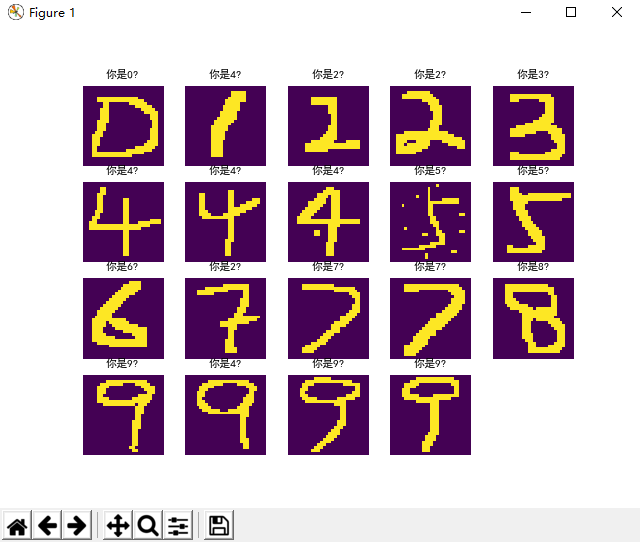
这批图片是经过图片增强后识别的结果,准确率有待提高
3、优化
3.1 更多样本:
收集难度大
3.2 数据增强:
简单地处理一下自己手写的数字图片
# -*- coding: utf-8 -*-
# encoding:utf-8 import torch
import numpy as np
from PIL import Image
import os
import matplotlib
import matplotlib.pyplot as plt
import glob
from scipy.ndimage import filters class ImageProcceed:
def __init__(self, image_folder):
self.image_folder = image_folder def save(self, rotate, filter=None, to_gray=True):
file_list = glob.glob(os.path.join(self.image_folder, '*.png'))
print(len(file_list))
for i, file in enumerate(file_list):
# 读取图片数据
image = Image.open(file) # .resize((28, 28))
# 灰度图
if to_gray == True:
image = image.convert('L')
# 旋转
image = image.rotate(rotate)
if filter is not None:
image = filters.gaussian_filter(image, 0.5)
image = Image.fromarray(image)
filename = os.path.basename(file)
fileext = os.path.splitext(filename)[1]
savefile = filename.replace(fileext, '-rt{}{}'.format(rotate, fileext))
print(savefile)
image.save(os.path.join(self.image_folder, savefile)) ip = ImageProcceed('data/myimages/')
ip.save(20, filter=0.5)
3.3 改变网络大小:
比如把上面的Net类中的3层改为2层
3.4 调参:
改变学习率,训练更多次数等
后面我调整了Net类中的两个地方,准确率终于达到100%,这只是在我小批量测试集上的表现而已,而现实中预测是不可能达到100%的,每台机器可能有差异,每次运行的结果会有不同,再次帖出代码
import torch.nn as nn class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积: 1通道输入,6通道输出,卷积核5*5,步长1,前后补2个0
# 激活函数一般用ReLU,后面改良的有LeakyReLU/PReLU
# MaxPool2d池化,一般是2
self.conv1 = nn.Sequential(nn.Conv2d(1, 6, 5, 1, 2)
, nn.PReLU()
, nn.MaxPool2d(2, 2))
self.conv2 = nn.Sequential(nn.Conv2d(6, 16, 5)
, nn.PReLU()
, nn.MaxPool2d(2, 2))
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120), # 卷积输出16,乘以卷积核5*5
# nn.Dropout2d(), # Dropout接收来自linear的数据,Dropout2d接收来自conv2d的数据
nn.PReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.Dropout(p=0.2),
nn.PReLU()
)
self.fc3 = nn.Linear(84, 10) # 输出层节点为10,代表数字0-9 # 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# 线性层的输入输出都是一维数据,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
上面改了两个地方,一个是激活函数ReLU改成了PReLU,正则化Dropout用0.2作为参数,下面是再次运行测试后的结果

识别手写数字增强版100% - pytorch从入门到入道(一)的更多相关文章
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- 学习笔记TF024:TensorFlow实现Softmax Regression(回归)识别手写数字
TensorFlow实现Softmax Regression(回归)识别手写数字.MNIST(Mixed National Institute of Standards and Technology ...
- TensorFlow实战之Softmax Regression识别手写数字
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2018年02月21日 23:10:04所撰写内容(http://blog.c ...
- 一文全解:利用谷歌深度学习框架Tensorflow识别手写数字图片(初学者篇)
笔记整理者:王小草 笔记整理时间2017年2月24日 原文地址 http://blog.csdn.net/sinat_33761963/article/details/56837466?fps=1&a ...
- 3 TensorFlow入门之识别手写数字
------------------------------------ 写在开头:此文参照莫烦python教程(墙裂推荐!!!) ---------------------------------- ...
- python手写神经网络实现识别手写数字
写在开头:这个实验和matlab手写神经网络实现识别手写数字一样. 实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手 ...
- 用BP人工神经网络识别手写数字
http://wenku.baidu.com/link?url=HQ-5tZCXBQ3uwPZQECHkMCtursKIpglboBHq416N-q2WZupkNNH3Gv4vtEHyPULezDb5 ...
- python机器学习使用PCA降维识别手写数字
PCA降维识别手写数字 关注公众号"轻松学编程"了解更多. PCA 用于数据降维,减少运算时间,避免过拟合. PCA(n_components=150,whiten=True) n ...
- KNN 算法-实战篇-如何识别手写数字
公号:码农充电站pro 主页:https://codeshellme.github.io 上篇文章介绍了KNN 算法的原理,今天来介绍如何使用KNN 算法识别手写数字? 1,手写数字数据集 手写数字数 ...
随机推荐
- 同步与互斥_percpu变量
percpu变量的关键就是:要求根据CPU的个数,在内存中生成多份拷贝,并且能够根据变量名和CPU编号,正确的对各个CPU的变量进行寻址. 采用per-cpu变量有下列好处:所需数据很可能存在于处理器 ...
- Java中NIO及基础实现
NIO:同步非阻塞IO 来源:BIO是同步阻塞IO操作,当线程在处理任务时,另一方会阻塞着等待该线程的执行完毕,为了提高效率,,JDK1.4后,引入NIO来提升数据的通讯性能 NIO中采用Reacto ...
- 本人亲测-SSM环境搭建(使用eclipse作为示例,过程挺全的,可作为参考)
本人亲测-SSM环境搭建(使用eclipse作为示例,过程挺全的,可作为参考) 本人亲测-SSM环境搭建(使用eclipse作为示例,过程挺全的,可作为参考) 本人亲测-SSM环境搭建(使用eclip ...
- Django实现WebSSH操作Kubernetes Pod
优秀的系统都是根据反馈逐渐完善出来的 上篇文章介绍了我们为了应对安全和多分支频繁测试的问题而开发了一套Alodi系统,Alodi可以通过一个按钮快速构建一套测试环境,生成一个临时访问地址,详细信息可以 ...
- drf框架中jwt认证,以及自定义jwt认证
0909自我总结 drf框架中jwt 一.模块的安装 官方:http://getblimp.github.io/django-rest-framework-jwt/ 他是个第三方的开源项目 安装:pi ...
- opencv::绘制-基本几何
画线 cv::line(LINE_4\LINE_8\LINE_AA) 画椭圆 cv::ellipse 画矩形 cv::rectangle 画圆 cv::circle 画填充 cv::fillPoly ...
- Javascript字符串常用方法详解
字符串 字符串就是一个或多个排列在一起的字符,放在单引号或双引号之中. 'abc'"abc" length属性 js里的字符串类似于数组,都是一个一个字符拼凑在一起组成的,因此可以 ...
- python2与3实际中遇到的区别
1.type(1/2) python2是向下取整,0,为int:python3是正常除法,0.5,为float 2.
- docker-compose 的使用
1.安装docker-compose,参考官方教程:https://docs.docker.com/compose/install/ [chenjl@ipha-dev71- ~]$ sudo curl ...
- OpenvSwitch系列之ovs-ofctl命令使用
Open vSwitch系列之一 Open vSwitch诞生 Open vSwitch系列之二 安装指定版本ovs Open vSwitch系列之三 ovs-vsctl 命令使用 OpenvSwit ...