jimdb压测踩坑记
本文记录在jimdb压测过程中遇到的各种小坑,望能够抛砖引玉。
1.压测流量起来后,过了5分钟左右,发现ops突降,大概降了三分之一,然后稳定了下来
大概原因:此种情况,jimdb极有可能某个分片的连接数打满,从而导致分片的cpu达到100%。
调优方案:首先,默认分片连接数为1w,此时可以根据自己的需求,如果自己的docker数量很少,可以调整成2w,反之则3w。
然后,看程序中的操作,是不是有pipeline或者mget等操作,如果有,且程序日志中输出了大量的can't get jedis connection from jedis pool,则调整如下线程池,直至找到比较合适的值:
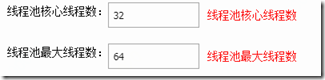
如果程序中普通的redis命令操作比较多,则可以调整如下参数,注意maxIdelPerKey不要超过64,否则无效,MaxTotalPerKey太大会造成连接数过多,太少会造成频繁连接,需要根据具体压测情况设置合适的值:
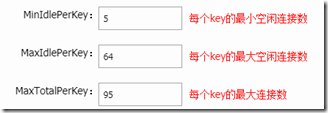
另外,连接的超时时间等不可设置过长,建议设置如下:

上面参数的调整,需要压测十几次甚至几十次,才能慢慢的调整出jimdb合理的参数值,合理的表现就是:
比如说第一波压测,jimdb参数优化前,慢慢起量,并发到5000的时候,jimdb因为某个分片连接数和cpu过高,挂了。那么参数的调优,就可以以5000并发为基础慢慢调整,直至调整出5000并发不会将jimdb分片打挂的情况。则视为当前jimdb调整参数合理。更加理想的情况就是,jimdb参数调整完毕后,你加500甚至1000并发上去,jimdb还能扛得住,这种情况,则说明jimdb参数调整非常合理。
切忌遇到jimdb分片挂了后,以为是性能问题,然后更换分片操作,由于新分片追加上来后,连接数都被清理光了,再起压测,因为压力反而不会很大,所以反而显得正常,但是此种情况下是及其不正常的,极有可能重启docker集群后再压测,依然会挂。
一旦jimdb分片打挂后,重新进行下一波压得的时候,记得将docker集群的所有机器重启一下,以便于清理掉连接数,否则的话,直接进行压测,会频频的导致分片数挂掉的情况。
调整参数后,效果不明显的话,也建议重启下docker集群。
如果不想重启jimdb集群的话,jimdb中清理集群命令也可以达到释放连接数的目的。
2. 压测流量起来过程中,有一个点,整体ops为0
分为几种情况
情况1,需要检查程序中是否有jmq生产,然后监控下jmq生产性能,如果压测过程中在某个点踩中了jmq生产的tp max点(一般会是2002ms,4002ms左右),会造成当前点ops为0;
情况2,需要检查程序中是否有fullgc产生或者频繁的younggc(一分钟超过三四十次),且youggc耗时普遍超过40ms以上
情况3,jvm老年代不释放,比如本地缓存写成了static,满了后又没有过期策略等(参见tomact中session保持)
其他情况。。。。。
3. 压测过程中,感觉没什么jimdb瓶颈,加docker后方法ops死活上不去或者上去的一点儿不明显
如果你程序中有jmq生产,在jmq生产性能这块,如果数据允许丢失,可以让jmq运维给你换成异步刷盘,同时加一些broker,则ops将会有明显提升
其他情况。。。。
4. 方法整体tp999很差
情况1, jmq生产性能或者消费性能
情况2, jimdb参数设置,可以参考第一条,通过压测获取合理值
情况3, 垃圾收集器设置,实践证明,G1垃圾收集器不仅可以用于大于4G的堆内内存上,也可以用于小于4G的堆内内存上
情况4, jvm堆内内存设置
情况5, 其他耗费性能的地方,比如多余的操作,无意义的操作等等
jimdb压测踩坑记的更多相关文章
- iOS自动化打包上传的踩坑记
http://www.cocoachina.com/ios/20160624/16811.html 很久以前就看了很多关于iOS自动打包ipa的文章, 看着感觉很简单, 但是因为一直没有AppleDe ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- 【踩坑记】从HybridApp到ReactNative
前言 随着移动互联网的兴起,Webapp开始大行其道.大概在15年下半年的时候我接触到了HybridApp.因为当时还没毕业嘛,所以并不清楚自己未来的方向,所以就投入了HybridApp的怀抱. Hy ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- djangorestframework+vue-cli+axios,为axios添加token作为headers踩坑记
情况是这样的,项目用的restful规范,后端用的django+djangorestframework,前端用的vue-cli框架+webpack,前端与后端交互用的axios,然后再用户登录之后,a ...
- HttpWebRequest 改为 HttpClient 踩坑记-请求头设置
HttpWebRequest 改为 HttpClient 踩坑记-请求头设置 Intro 这两天改了一个项目,原来的项目是.net framework 项目,里面处理 HTTP 请求使用的是 WebR ...
- vue踩坑记
vue踩坑记 易错点 语法好难啊qwq 不要把'data'写成'date' 在v-html/v-bind中使用vue变量时不需要加变量名 在非vue事件中使用vue中变量时需要加变量名 正确 < ...
随机推荐
- Jeewx-Boot 1.1 版本发布,基于SpringBoot的开源微信管家系统
项目介绍 JeewxBoot是一款基于SpringBoot的开源微信管家系统,采用SpringBoot2.1.3 + Mybatis + Velocity 框架技术.支持微信公众号.微信第三方平台(扫 ...
- 【Android - 自定义View】之View的工作过程简介
View的工作过程分为三个过程: View的measure过程: View的layout过程: View的draw过程. 我们知道,一个Activity就是一个窗口,这个窗口中包含一个Window.一 ...
- telnet指令研究—以网络聊天程序为例
一.telnet指令 Telnet取名自Telecommunications和Networks的联合缩写,是早期个人计算机上连接到服务器主机的一个网络指令,由于存在安全问题,现在已经很少被使用.在wi ...
- ASI的其他使用方法
ASI 除了设置代理监听以外还可以设置block进行监听 如果同时设置block和实现了代理方法 请求过程中 block和代理方法都会调用 一般 代理方法 优先block方法调用 第3种方式调用
- Too many open files的四种解决办法
[摘要] Too many open files有四种可能:一 单个进程打开文件句柄数过多,二 操作系统打开的文件句柄数过多,三 systemd对该进程进行了限制,四 inotify达到上限. 领导见 ...
- Hadoop 维护总结
1. 启动 history ./sbin/mrjobhistorydaemon.sh start historyserver ./sbin/yarn-daemon.sh start proxyserv ...
- 使用 nginx 实现虚拟主机
当多个系统需要部署的时候,有系统访问很小,为了节省成本,就需要将多个系统部署到同一台服务器上,怎么在同一台服务器上,完成不同系统的部署和访问,就需要使用虚拟主机实现. 使用端口实现虚拟主机 配置 ng ...
- Sring+mybatis模拟银行转账
实体类: package com.bjsxt.pojo; import java.io.Serializable; public class Account implements Serializab ...
- 在Linux中配置jdk,Tomcat,MySQL
解压缩: tar 命令 : 使用方式 tar [参数] source [target] source - 压缩文件 target - 解压缩后的目标位置, 默认解压到当前目录 常用写法 : 解压缩 : ...
- 数据库Oracle的子查询练习
1.写一个查询显示与 Zlotkey 的 在同一部门的雇员的 last name和 hire date,结果中不包括 Zlotkey --1.写一个查询显示与 Zlotkey 的 在同一部门的雇员的 ...