大型情感剧集Selenium:3_元素定位 #华为云·寻找黑马程序员#
关于昨天的文章
今天有朋友反馈,代码运行的时候,selenium提示警告
DeprecationWarning: use options instead of chrome_options
driver = webdriver.Chrome(chrome_options=options)
本来以为是我的selenium版本太低了,可以上官网看到3.141.0是最新版本啊,最后把python从3.6.8升级到3.7.3才复现了此问题。虽然这个告警不影响使用,但既然官方提示了修改就看看呗,其实很简单:
# 将原本的chrome_options
driver = webdriver.Chrome(chrome_options=options)
# 改为options 即可
driver = webdriver.Chrome(options=options)
# 另外,针对以下引用
from selenium.webdriver.chrome.options import Options
options = Options()
# 可以简写为:
options = webdriver.ChromeOptions()
今天说什么
今天肯定说元素定位啊,再不说都要取关了…可应该怎么说呢?
话说,selenium1.0起初它使用了基于Javascript的自动化引擎,而浏览器对 Javascript 又有很多安全限制,之后后通过webdrvier进行了各浏览器的协议封装。那么说到底,我们通过selenium变相的完成了js的的相关操作,比如:
再来看看js的dom对象:
selenium将JavaScript的HTML DOM进行了封装处理,最终提供给我们进行使用。引申出三点:
开发转测试,真的是有优势的
作为一个合格的测试,抽时间学学html css 和js 也是对自己能力的提升
爬虫熟识的html解析库Beautifulsoup4,元素的定位上用法也类似以上两者,一通百通!
selenium元素定位
WebDriver提供了一系列的定位符以便使用元素定位方法。常见的定位符有以下几种:
id
class name
name
tag
link text
partial link text
xpath
css selector
而针对元素定位,selenium又分为find_element_by和find_elements_by。即找到一个元素和找到所有元素。
针对find_elements_by,我们又可以针对找到的元素,我们又可以像python操作list一样进行切片,筛选等操作。
我们以百度为例,介绍以上方法:
下来我们用代码针对百度进行演示
# -*- coding: utf-8 -*-
# @Author : 王翔
# @JianShu : 清风Python
# @Date : 2019/6/19 21:40
# @Software : PyCharm
# @version :Python 3.7.3
# @File : Day_3.1_chrome_option_warning.py
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('window-size=800,600')
options.add_argument('disable-infobars')
driver = webdriver.Chrome(options=options)
driver.get("http://www.baidu.com")
# link_text 定位
driver.find_element_by_link_text('新闻').click()
time.sleep(1)
driver.back()
# id 定位
driver.find_element_by_id("kw").send_keys("id 定位|")
time.sleep(1)
# class name 定位
driver.find_element_by_class_name("s_ipt").send_keys("class name 定位|")
time.sleep(1)
# name 定位
driver.find_element_by_name("wd").send_keys("name 定位|")
time.sleep(1)
# css 定位
driver.find_element_by_css_selector("#kw").send_keys("css 定位|")
time.sleep(1)
# xpath 定位
driver.find_element_by_xpath("//input[@id='kw']").send_keys(" xpath 定位|")
time.sleep(1)
driver.quit()
效果如下: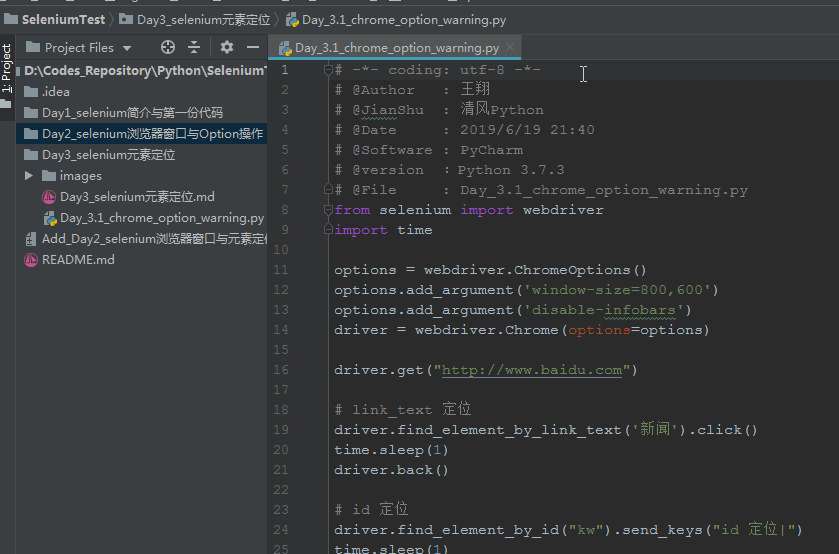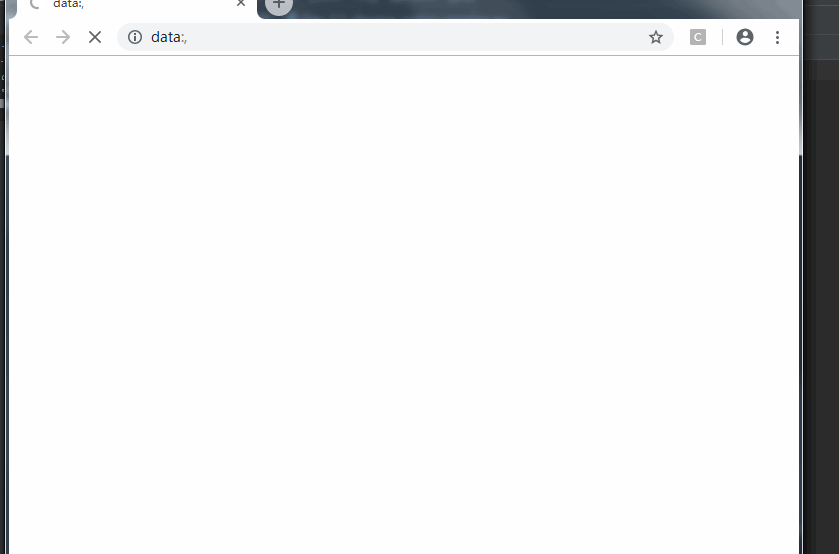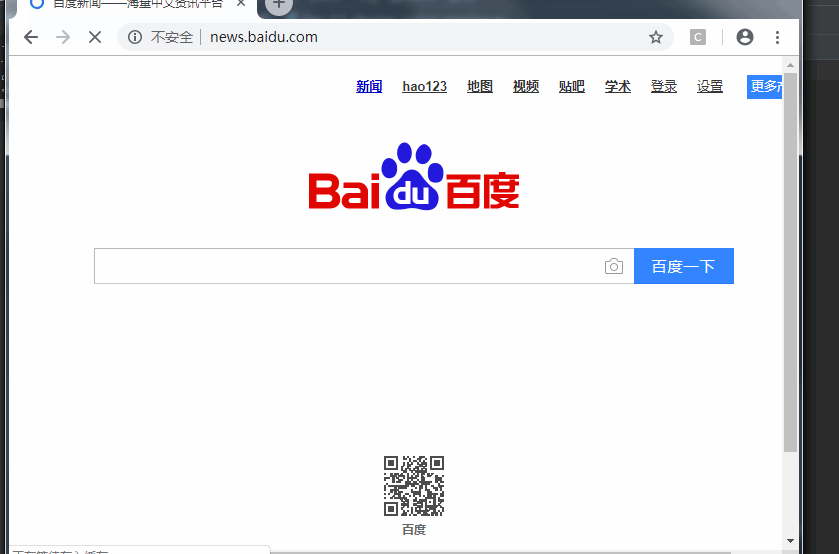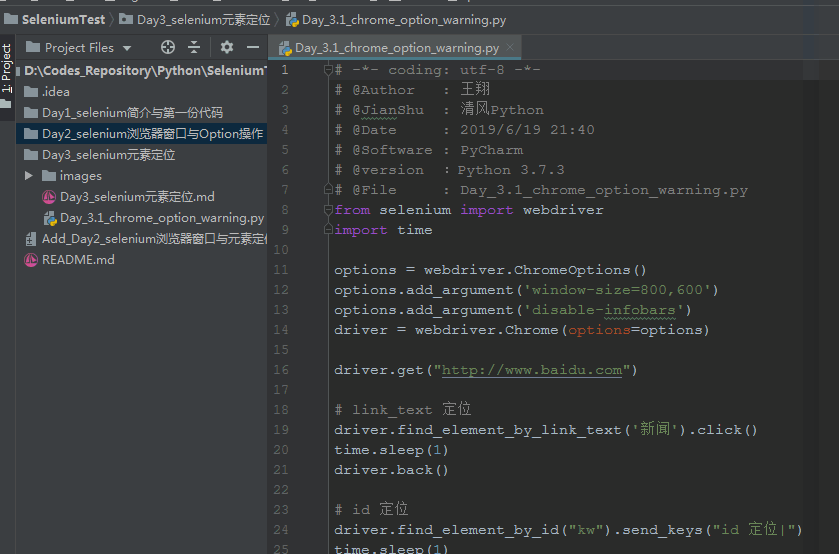
To Be Continue
今天的内容就到这里,如果觉得有帮助,欢迎将文章或者我的公众号【清风Python】分享给更多喜欢python的人
来源:华为云社区征文 作者:清风Python
大型情感剧集Selenium:3_元素定位 #华为云·寻找黑马程序员#的更多相关文章
- 大型情感剧集Selenium:2_options设置 #华为云·寻找黑马程序员#
上集回顾 昨天说简单介绍了什么是selenium,它能干what,和发展史与梗概.当的是python如何通过pip安装selenium,并下载对应浏览器的webdriver. 最后简单通过一个Demo ...
- 大型情感剧集Selenium:1_介绍 #华为云·寻找黑马程序员#
学习selenium能做什么? 很多书籍.文章中是这么定义selenium的: Selenium 是开源的自动化测试工具,它主要是用于Web 应用程序的自动化测试,不只局限于此,同时支持所有基于web ...
- 大型情感剧集Selenium:4_老中医教你(单/多/下拉框)选项定位 #华为云·寻找黑马程序员#
今天讲什么 讲什么标题说了,讲selenium的单选.多选.下拉框选项定位.但其实这东西,没什么太多说的,又比较枯燥,那该怎么让这一集selenium的课程变得有趣呢?有请老中医,哈哈- 怎么样,这个 ...
- 大型情感剧集Selenium:6_selenium中的免密登陆与cookie操作 #华为云·寻找黑马程序员#
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字"加群",加入华为云线上技术讨论群:输入关键字"最新活动",获取华 ...
- 大型情感剧集Selenium:9_selenium配合Pillow完成浏览器局部截图
网页截图 上次提到了selenium的四种截图方法,最终截图了整张网页.但很多时候,我们仅仅需要截图部分的内容.比如截取某个关键信息,或者现在已经不常见的截图验证码(现在都是各种按规则点击-).那么我 ...
- 大型情感剧集Selenium:8_selenium网页截图的四种方法
有时候,有时候,你会相信一切有尽头-当你的代码走到了尽头,那么保留最后一刻的状态尤为重要,此时你该如何操作?记录日志-没有将浏览器当前的状态进行截图来的直观! 那么,selenium截取截屏,有哪些方 ...
- 大型情感剧集Selenium:6_selenium中的免密登陆与cookie操作
网站登录 现在各大平台在反爬虫功能上,可谓花样繁多.总结下来按照破解成功率排名,最高的是滑动解锁.其次是验证码数字.之后是一次点击对应的汉字,最后是想12306之前那种反人类的让你说那些是奶糖吧,哈哈 ...
- 大型情感剧集Selenium:6_selenium中的免密登陆与cookie操作【华为云技术分享】
网站登录 现在各大平台在反爬虫功能上,可谓花样繁多.总结下来按照破解成功率排名,最高的是滑动解锁.其次是验证码数字.之后是一次点击对应的汉字,最后是想12306之前那种反人类的让你说那些是奶糖吧,哈哈 ...
- 【基础】selenium中元素定位的常用方法(三)
一.Selenium中元素定位共有八种 id name className tagName linkText partialLinkText xpath cssSelector 其中前六种都比较简单, ...
随机推荐
- [考试反思]1019csp-s模拟测试80(a):天遣
A组题,所以把榜粘全了. 第6名,被卡在刚好正中间. 我最近干什么伤天害理的事了?(例如说没有在skyh去上厕所的时候捶他) 上来看T1,非常贴心出题人直接把递推式子给你了,然后就和斐波数的递推一样了 ...
- python分支和循环结构
本文收录在Python从入门到精通系列文章系列 1. 分支结构 1.1 应用场景 迄今为止,我们写的Python代码都是一条一条语句顺序执行,这种代码结构通常称之为顺序结构.然而仅有顺序结构并不能解决 ...
- java应用性能调优之详解System的gc垃圾回收方法
一.什么是System.gc()? System.gc()是用Java,C#和许多其他流行的高级编程语言提供的API.当它被调用时,它将尽最大努力从内存中清除垃圾(即未被引用的对象).名词解释:GC, ...
- git 设置不用每次都输入 账号密码
执行命令 git config --global credential.helper store 然后,下次再输入一次 账号密码 就可以了.
- beacon帧字段结构最全总结(三)——VHT字段总结
VHT Capabilities 802.11ac作为IEEE 无线技术的新标准,它借鉴了802.11n的各种优点并进一步优化,除了最明显的高吞吐特点外,不仅可以很好地兼容802.11a/n的设备,同 ...
- mysql批量更新写法
mysql批量更新写法<pre> $namedmp=filter($_POST['namedmp']); $namedsp=filter($_POST['namedsp']); $name ...
- php sublime常用插件
php sublime常用插件 1 Sublime Text的默认设置是不开启显示编码的,如果想开启,可通过菜单Perference → Settings – User,在打开的配置文件里 ,在大括号 ...
- nyoj 257 郁闷的C小加(一)(栈、队列)
郁闷的C小加(一) 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 我们熟悉的表达式如a+b.a+b*(c+d)等都属于中缀表达式.中缀表达式就是(对于双目运算符来说 ...
- 【并发编程】synchronized的使用场景和原理简介
1. synchronized使用 1.1 synchronized介绍 在多线程并发编程中synchronized一直是元老级角色,很多人都会称呼它为重量级锁.但是,随着Java SE 1.6对sy ...
- 力扣(LeetCode)三个数的最大乘积 个人题解
给定一个整型数组,在数组中找出由三个数组成的最大乘积,并输出这个乘积. 示例 1: 输入: [1,2,3] 输出: 6 示例 2: 输入: [1,2,3,4] 输出: 24 注意: 给定的整型数组长度 ...