python 线程、进程与协程
一、什么是线程?什么是进程?
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。[3]
进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上。 进程的概念
进程的定义
线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。 在单个程序中同时运行多个线程完成不同的工作,称为多线程。
线程定义
协程,是由程序员创造出来的一个不是真实存在的东西;可以看做是一个微线程,对一个线程进程分片,使得线程在代码块之间进行来回切换执行,而不是在逐行执行。
协程定义
注意:
对于python而言,其自己没有进程和线程,在执行的时候需要调用操作系统的进程和线程。
二、应用软件、进程和线程的关系
程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
简单来说:一个应用程序(软件),可以有多个进程(默认只有一个),一个进程中可以创建多个线程(默认一个)。
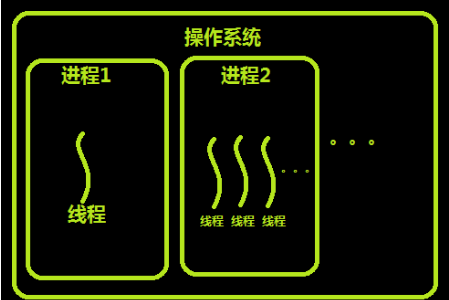
三、进程、线程、协程的区别
进程是资源分配的最小单元,其作用是进行数据隔离,线程是cpu调度的最小单元,其作用主要是执行某个任务,一个应用程序可以有多个进程,一个进程可以有多个线程,在其他语言中几乎很少用进程,都是用多线程,而对于python来说,IO操作主要是用多线程实现,计算密集型操作主要是用多进程实现,主要原因是python中存在GIL锁,GIL锁的作用就是保证一个进程中同一时刻只有一个线程被cpu调度,所以在python中想要利用cpu的多核优势就是开多个进程。在后来程序员级别的人为了让代码更牛逼,创建了一个东西叫协程,这个东西本身不存在,是程序员自己创造出来的,协程可以对代码的执行顺序进行控制,本身这个东西存在没有意义,但是协程要是和IO切换放在一起就了不得了,遇到IO操作就切换,相当于把一个线程分片,所达到的效果是线程一直没有停,一直在工作,这就是进程、线程、协程的本质区别,在python中用协程的时候会有一个模块叫greenlet,协程加IO自动切换的模块叫gevent。
注意:IO密集型操作可以使用多线程;计算密集型可以使用多进程;
*****通过漫画了解进程与线程
四、线程
(一)线程的基本使用
#主程序默认等待子程序执行完毕
import threading
import time
def func(arg):
time.sleep(arg)
print(arg) t1 = threading.Thread(target=func,args=(3,))
t1.start() t2 = threading.Thread(target=func,args=(2,))
t2.start() print(123)
(二)线程的常用方法
1、start 线程准备就绪,等待CPU调度
2、setDaemon(True) 主程序不再等,主程序终止则所有子程序终止
import threading
import time
def func(arg):
time.sleep(2)
print(arg) t1 = threading.Thread(target=func,args=(3,))
t1.setDaemon(True) #设置主程序不在等待子程序执行完毕,主程序终止则子程序终止
t1.start() t2 = threading.Thread(target=func,args=(9,))
t2.setDaemon(True)
t2.start() print(123)
3、join 开发者可以控制主线程等待子线程(最多等待时间)
import threading
import time
def func(arg):
time.sleep(arg)
print(arg) print('创建子线程t1')
t1 = threading.Thread(target=func,args=(3,))
t1.start()
# join()无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。
# join(n)有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走,但最终会等所有子程序执行完毕主程序在终止。
t1.join(6) print('创建子线程t2')
t2 = threading.Thread(target=func,args=(6,))
t2.start()
t2.join(6) print(123)
4、其它方法
import threading
import time
def func(arg):
# 获取当前执行该函数的线程的对象
t = threading.current_thread()
# 根据当前线程对象获取当前线程名称
name = t.getName()
print(name,arg) t1 = threading.Thread(target=func,args=(11,))
t1.setName('线程1') #设置线程名称
t1.start() t2 = threading.Thread(target=func,args=(22,))
t2.setName('线程2') #设置线程名称
t2.start() print(123)
(三)两种方法创建多线程
#多线程方式一(常见):
import threading
def func(arg):
print(arg) for i in range(4):
t = threading.Thread(target=func,args=(i,))
t.start()
#多线程方式二(通过面向对象创建):
import threading
class MyThread(threading.Thread): def run(self):
print(11111,self._args,self._kwargs) t1 = MyThread(args=(11,))
t1.start() t2 = MyThread(args=(22,))
t2.start()
(四)几种常见的线程锁
问题:为什么要加线程锁?
#如果不加锁就可能出现多个线程抢占资源的情况,从而出现脏数据,加上锁之后可以保证在同一时刻只有一个线程在执行。
*****同步锁******
import threading
import time
lock = threading.Lock()
v = []
def task(i):
lock.acquire()
v.append(i)
time.sleep(0.01)
m = v[-1]
print(m,i)
lock.release()
for i in range(10):
t = threading.Thread(target=task,args=(i,))
t.start()
Lock
*****递归锁:可以多次获得锁,多次释放锁******
import threading
import time
lock = threading.RLock()
v = []
def task(i):
lock.acquire()
lock.acquire()
v.append(i)
time.sleep(0.01)
m = v[-1]
print(m,i)
lock.release()
lock.release()
for i in range(10):
t = threading.Thread(target=task,args=(i,))
t.start()
RLock
*****信号锁:可以控制一次最多有n个线程执行代码******
import threading
import time
lock = threading.BoundedSemaphore(5)
def task(i):
lock.acquire()
print(i)
time.sleep(1)
lock.release()
for i in range(10):
t = threading.Thread(target=task,args=(i,))
t.start()
BoundedSemaphore
*****条件锁:简单理解,满足条件时,释放线程,根据输入数量释放相应的线程数量******
import threading
import time
lock = threading.Condition()
def task(i):
print('线程来了',i)
lock.acquire()
lock.wait()
print(i)
time.sleep(1)
lock.release() for i in range(10):
t = threading.Thread(target=task,args=(i,))
t.start()
while 1:
num = int(input('请输入一次要执行的线程数量>>>'))
lock.acquire()
lock.notify(num)
lock.release()
Condition
*****事件锁:一次放所有线程******
import threading
import time
lock = threading.Event()
def task(i):
print('线程来了')
lock.wait() #“Flag”值为False
print(i)
time.sleep(1)
for i in range(10):
t = threading.Thread(target=task,args=(i,))
t.start()
input('>>>')
lock.set() #“Flag”值为True
lock.clear #“Flag”值为False
Event
(五)线程池
from concurrent.futures import ThreadPoolExecutor
import time def task(a1,a2):
time.sleep(2)
print(a1,a2) # 创建了一个线程池(最多5个线程)
pool = ThreadPoolExecutor(5) for i in range(40):
# 去线程池中申请一个线程,让线程执行task函数。
pool.submit(task,i,8)
(六)生产者消费者模型
import time
import queue
import threading
q = queue.Queue() # 线程安全 def producer(id):
"""
生产者
:return:
"""
while True:
time.sleep(2)
q.put('包子')
print('厨师%s 生产了一个包子' %id ) for i in range(1,4):
t = threading.Thread(target=producer,args=(i,))
t.start() def consumer(id):
"""
消费者
:return:
"""
while True:
time.sleep(1)
v1 = q.get()
print('顾客 %s 吃了一个包子' % id) for i in range(1,3):
t = threading.Thread(target=consumer,args=(i,))
t.start()
(七)threadinglocal 原理
作用:为每个线程创建一个独立的空间,使得线程对自己的空间中的数据进行操作(数据隔离)。
import time
import threading
INFO = {}
class Local(object): def __getattr__(self, item):
ident = threading.get_ident()
return INFO[ident][item] def __setattr__(self, key, value):
ident = threading.get_ident()
if ident in INFO:
INFO[ident][key] = value
else:
INFO[ident] = {key:value} obj = Local()
def func(arg):
obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1)
time.sleep(2)
print(obj.phone,arg) for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
易理解版本
import time
import threading class Local(object):
def __init__(self):
object.__setattr__(self,'INFO',{})
def __getattr__(self, item):
ident = threading.get_ident()
return self.INFO[ident][item] def __setattr__(self, key, value):
ident = threading.get_ident()
if ident in self.INFO:
self.INFO[ident][key] = value
else:
self.INFO[ident] = {key:value} obj = Local()
def func(arg):
obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1)
time.sleep(2)
print(obj.phone,arg) for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
改装版
五、进程
(一)进程的常用功能----------------其方法和线程类似
- join
- daemon
- name
- multiprocessing.current_process()
- multiprocessing.current_process().ident/pid
import time
import multiprocessing
def task(arg):
# time.sleep(3)
print(arg)
p = multiprocessing.current_process() #获取当前工作进程
print(p.name) #获取进程名称 if __name__ == '__main__':
p1 = multiprocessing.Process(target=task,args=(1,))
p1.name = 'pp1' #设置进程名称
p1.daemon=True #主进程执行完毕所有子进程不论执行到哪里都关闭
p1.start()
# p1.join(0.5) #加参数主进程最长等待子进程0.5秒就向下执行,但最终都会等子进程执行完毕在关闭 print(1234) p2 = multiprocessing.Process(target=task, args=(2,))
p2.name = 'pp2' #设置进程名称
p2.daemon=True
p2.start()
# p2.join(0.5)
print(2345)
进程常用方法
(二)进程的数据共享问题
进程之间的数据默认不共享,但通过Queue和Manager可以使进程之间的数据共享
import multiprocessing
data_list = []
def task(arg):
data_list.append(arg)
print(data_list) def run():
for i in range(4):
p = multiprocessing.Process(target=task,args=(i,))
p.start() if __name__ == '__main__':
run()
#结果
# [2]
# [0]
# [1]
# [3]
数据不共享
*******进程间的数据共享:multiprocessing.Queue
q = multiprocessing.Queue() def task(arg,q):
q.put(arg) def run():
for i in range(10):
p = multiprocessing.Process(target=task, args=(i, q,))
p.start()
while True:
v = q.get()
print(v)
if __name__ == '__main__':
run()
**********进程间的数据共享:Manager
def task(arg,dic):
time.sleep(2)
dic[arg] = 100 if __name__ == '__main__':
m = multiprocessing.Manager()
dic = m.dict()
process_list = []
for i in range(10):
p = multiprocessing.Process(target=task, args=(i,dic,))
p.start()
process_list.append(p) #处理主进程和子进程数据共享问题,避免主进程结束之后共享的数据消失
while True:
count = 0
for p in process_list:
if not p.is_alive():
count += 1
if count == len(process_list):
break
print(dic)
(三)进程锁
参考线程锁,其使用方法及其类似
*******为什么会有进程锁?
当多个进程共享某个数据时,为了保证数据安全,不出现脏数据,会给进程加锁.
(四)进程池
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def task(arg):
time.sleep(2)
print(arg) if __name__ == '__main__':
pool = ProcessPoolExecutor(5) #进程池里面设置了5个进程
for i in range(10):
pool.submit(task,i)
六、简单爬虫实例--------使用线程池
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor # 模拟浏览器发送请求
# 内部创建 sk = socket.socket()
# 和抽屉进行socket连接 sk.connect(...)
# sk.sendall('...')
# sk.recv(...) def task(url):
r1 = requests.get(
url=url,
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
) # 查看下载下来的文本信息
soup = BeautifulSoup(r1.text,'html.parser')
content_list = soup.find('div',attrs={'id':'content-list'})
for item in content_list.find_all('div',attrs={'class':'item'}):
title = item.find('a').text.strip()
target_url = item.find('a').get('href')
print(title,target_url) def run():
pool = ThreadPoolExecutor(5)
for i in range(1,50):
pool.submit(task,'https://dig.chouti.com/all/hot/recent/%s' %i) if __name__ == '__main__':
run()
七、协程
协程的实现主要应用greenlet模块,可使线程在代码块之间来回切换执行,见代码:
import greenlet
def f1():
print(11)
gr2.switch()
print(22)
gr2.switch() def f2():
print(33)
gr1.switch()
print(44) # 协程 gr1
gr1 = greenlet.greenlet(f1)
# 协程 gr2
gr2 = greenlet.greenlet(f2)
gr1.switch()
除了以上方法之外,也可以手动实现协程,上代码:
def f1():
print(11)
yield
print(22)
yield
print(33) def f2():
print(55)
yield
print(66)
yield
print(77) v1 = f1()
v2 = f2() next(v1)
next(v2)
next(v1)
next(v2)
next(v1)
next(v2)
注意:单纯的协程无用,并不能实现并发操作,但是协程遇到IO就切换就牛逼起来了,可大大缩短执行任务的等待时间,提高代码执行的速度,上代码:
from gevent import monkey
monkey.patch_all() # 以后代码中遇到IO都会自动执行greenlet的switch进行切换
import requests
import gevent def get_page1(url):
ret = requests.get(url)
print(url,ret.content) def get_page2(url):
ret = requests.get(url)
print(url,ret.content) def get_page3(url):
ret = requests.get(url)
print(url,ret.content) gevent.joinall([
gevent.spawn(get_page1, 'https://www.python.org/'), # 协程1
gevent.spawn(get_page2, 'https://www.yahoo.com/'), # 协程2
gevent.spawn(get_page3, 'https://github.com/'), # 协程3
])
八、基于IO多路复用+socket实现并发请求,一个线程100个请求
(一)IO多路复用
作用:可以监听所有的IO请求的状态。
- socket I,input
o,output
操作系统检测socket是否发生变化,有三种模式:
select:最多1024个socket;循环去检测。
poll:不限制监听socket个数;循环去检测(水平触发)。
epoll:不限制监听socket个数;回调方式(边缘触发)。
Python模块:
select.select
select.epoll
注意:windows系统只支持select。
(二)基于IO多路复用+socket实现单线程的并发,上代码:
import socket
import select client1 = socket.socket()
client1.setblocking(False) # 百度创建连接: 非阻塞 try:
client1.connect(('www.baidu.com',80))
except BlockingIOError as e:
pass client2 = socket.socket()
client2.setblocking(False) # 百度搜狗连接: 非阻塞
try:
client2.connect(('www.sogou.com',80))
except BlockingIOError as e:
pass client3 = socket.socket()
client3.setblocking(False) # 创建老男孩连接: 非阻塞
try:
client3.connect(('www.oldboyedu.com',80))
except BlockingIOError as e:
pass socket_list = [client1,client2,client3]
conn_list = [client1,client2,client3] while True:
rlist,wlist,elist = select.select(socket_list,conn_list,[],0.005)
# wlist中表示已经连接成功的socket对象
for sk in wlist:
if sk == client1:
sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n')
elif sk==client2:
sk.sendall(b'GET /web?query=fdf HTTP/1.0\r\nhost:www.sogou.com\r\n\r\n')
else:
sk.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.oldboyedu.com\r\n\r\n')
conn_list.remove(sk)
for sk in rlist:
chunk_list = []
while True:
try:
chunk = sk.recv(8096)
if not chunk:
break
chunk_list.append(chunk)
except BlockingIOError as e:
break
body = b''.join(chunk_list)
# print(body.decode('utf-8'))
print('------------>',body)
sk.close()
socket_list.remove(sk)
if not socket_list:
break
单线程并发
import socket
import select class Req(object):
def __init__(self,sk,func):
self.sock = sk
self.func = func def fileno(self):
return self.sock.fileno() class Nb(object): def __init__(self):
self.conn_list = []
self.socket_list = [] def add(self,url,func):
client = socket.socket()
client.setblocking(False) # 非阻塞
try:
client.connect((url, 80))
except BlockingIOError as e:
pass
obj = Req(client,func)
self.conn_list.append(obj)
self.socket_list.append(obj) def run(self): while True:
rlist,wlist,elist = select.select(self.socket_list,self.conn_list,[],0.005)
# wlist中表示已经连接成功的req对象
for sk in wlist:
# 发生变换的req对象
sk.sock.sendall(b'GET /s?wd=alex HTTP/1.0\r\nhost:www.baidu.com\r\n\r\n')
self.conn_list.remove(sk)
for sk in rlist:
chunk_list = []
while True:
try:
chunk = sk.sock.recv(8096)
if not chunk:
break
chunk_list.append(chunk)
except BlockingIOError as e:
break
body = b''.join(chunk_list)
# print(body.decode('utf-8'))
sk.func(body)
sk.sock.close()
self.socket_list.remove(sk)
if not self.socket_list:
break def baidu_repsonse(body):
print('百度下载结果:',body) def sogou_repsonse(body):
print('搜狗下载结果:', body) def oldboyedu_repsonse(body):
print('老男孩下载结果:', body) t1 = Nb()
t1.add('www.baidu.com',baidu_repsonse)
t1.add('www.sogou.com',sogou_repsonse)
t1.add('www.oldboyedu.com',oldboyedu_repsonse)
t1.run()
单线程并发高级版
(三)总结
1、socket默认是阻塞的,阻塞体现在connect和recv两个阶段
2、如何让socket编程非阻塞?
设置setblocking(False)
3、提高并发方案:
- 多进程
- 多线程
- 异步非阻塞模块(Twisted) scrapy框架(单线程完成并发)
4、 什么是异步非阻塞?
- 非阻塞,不等待。
比如创建socket对某个地址进行connect、获取接收数据recv时默认都会等待(连接成功或接收到数据),才执行后续操作。
如果设置setblocking(False),以上两个过程就不再等待,但是会报BlockingIOError的错误,只要捕获即可。
- 异步,通知,执行完成之后自动执行回调函数或自动执行某些操作(通知)。
比如做爬虫中向某个地址baidu.com发送请求,当请求执行完成之后自执行回调函数。
5、什么是同步阻塞?
- 阻塞:等
- 同步:按照顺序逐步执行
6.什么是并行和并发?
并发 不能利用多核,同一时间段内,有多个任务在一个CPU上
并行 能利用多核,同一时刻有多个任务在CPU上同时执行轮流被执行
python 线程、进程与协程的更多相关文章
- Python 线程&进程与协程
Python 的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承.Py ...
- 多任务-python实现-进程,协程,线程总结(2.1.16)
@ 目录 1.类比 2.总结 关于作者 1.类比 一个生产玩具的工厂: 一个生产线成为一个进程,一个生产线有多个工人,所以工人为线程 单进程-多线程:一条生产线,多个工人 多进程-多线程:多条生产线, ...
- Python之线程、进程和协程
python之线程.进程和协程 目录: 引言 一.线程 1.1 普通的多线程 1.2 自定义线程类 1.3 线程锁 1.3.1 未使用锁 1.3.2 普通锁Lock和RLock 1.3.3 信号量(S ...
- python成长之路 :线程、进程和协程
python线程 进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源的管理和分 ...
- Python之路【第七篇】:线程、进程和协程
Python之路[第七篇]:线程.进程和协程 Python线程 Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元. 1 2 3 4 5 6 7 8 9 10 11 12 1 ...
- python运维开发(十一)----线程、进程、协程
内容目录: 线程 基本使用 线程锁 自定义线程池 进程 基本使用 进程锁 进程数据共享 进程池 协程 线程 线程使用的两种方式,一种为我们直接调用thread模块上的方法,另一种我们自定义方式 方式一 ...
- Python 线程和进程和协程总结
Python 线程和进程和协程总结 线程和进程和协程 进程 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间.内存等)的基本单位: 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其 ...
- python 线程 进程 协程 学习
转载自大神博客:http://www.cnblogs.com/aylin/p/5601969.html 仅供学习使用···· python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件和 ...
- python并发编程之Queue线程、进程、协程通信(五)
单线程.多线程之间.进程之间.协程之间很多时候需要协同完成工作,这个时候它们需要进行通讯.或者说为了解耦,普遍采用Queue,生产消费模式. 系列文章 python并发编程之threading线程(一 ...
- Python菜鸟之路:Python基础-线程、进程、协程
上节内容,简单的介绍了线程和进程,并且介绍了Python中的GIL机制.本节详细介绍线程.进程以及协程的概念及实现. 线程 基本使用 方法1: 创建一个threading.Thread对象,在它的初始 ...
随机推荐
- layui table异步调用数据的时候,数据展示不出来现象解决方案
最近使用layui table进行异步获取数据并填充的时候,控制台打印出数据长度为0,但是其中还有数据,网上找了很多办法,下边是我最后使用的. 一般,render渲染表格是独立的书写格式,但是我在做数 ...
- 基于Python协同过滤算法的认识
Contents 1. 协同过滤的简介 2. 协同过滤的核心 3. 协同过滤的实现 4. 协同过滤的应用 1. 协同过滤的简介 关于协同过滤的一个最经典的例子就是看电影,有时候 ...
- asp.net core 使用Mysql和Dapper
序曲:学习编程最好的方式就是敲代码,没有比这个更好的方法,哪怕你看了上百G的视频,都不如你自己敲几行代码更为有效.还有要记得敲完代码然后写一篇随笔来记录一下你所学所想. 大家都知道,.netcore是 ...
- redis 漏洞造成服务器被入侵-CPU飙升
前言 前几天在自己服务器上搭了redis,准备想着大展身手一番,昨天使用redis-cli命令的时候,10s后,显示进程已杀死.然后又试了几次,都是一样的结果,10s时间,进程被杀死.这个时候我还 ...
- Chrome 浏览器默认样式覆盖自己 CSS 样式的解决
检查 HTML 源代码,DOCTYPE 的声明是否写正确. HTML5 的 DOCTYPE 声明规范: <!DOCTYPE html> 参考链接: css - User agent sty ...
- iOS性能优化-异步绘制
参考地址:https://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/ 很久以前就看过这篇文章,但是也只是看过就过了,没有去整 ...
- WebGL简易教程(十):光照
目录 1. 概述 2. 原理 2.1. 光源类型 2.2. 反射类型 2.2.1. 环境反射(enviroment/ambient reflection) 2.2.2. 漫反射(diffuse ref ...
- Java 2019 生态圈使用报告,这结果你赞同吗?
这是国外一机构调查了 7000 名开发者得出来的 Java 2019 年生态圈工具使用报告,主要调查了 Java 版本.开发框架.web 服务器等使用情况.虽然只有 7000 名开发者参与调查,这数目 ...
- 关于MySQL的经典例题50道
--1.学生表Student(S,Sname,Sage,Ssex) --S 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别--2.课程表 Course(C,Cname,T) - ...
- Spring Boot 二十个注解
Spring Boot 二十个注解 占据无力拥有的东西是一种悲哀. Cold on the outside passionate on the insede. 背景:Spring Boot 注解的强大 ...