Hadoop入门学习笔记---part2
在《Hadoop入门学习笔记---part1》中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱。不够系统化,不够简洁。经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建hadoop环境时,需要在linux机器上做一些设置,在搭建Hadoop集群环境前,需要在本地机器上做以下设置:
- 修改ip地址;
- 关闭防火墙;
- Hostname的修改;
- Ssh自动登陆的设置(也即:免密码登录);
**关于以上操作的详细命令可以查看上一篇博客《Hadoop入门学习笔记---part1》 。 作者:itRed 邮箱:it_red@sina.com 博客:http://itred.cnblogs.com
然后是安装过程,分为两步:
- 安装jdk;
- 安装hadoop;
Part2的重点就是安装和配置hadoop:在myeclipse中查看Hadoop的源码。
在安装之前,说一说hadoop的版本:
- Apache :官方版;
- Cloudera: 使用下载最多的版本,稳定,有商业支持,在Apache基础上打上了patch。应该说是比较推荐的一种;
- Yahoo :内部使用的版本,发布过两次,已有的版本放到Apache上,后续的还在继续发布,并且是集中在Apache的版本上。
本人使用的Hadoop版本是1.1.2,使用的软件为Hadoop-1.1.2.tar.gz
在以上的设置工作完之后,正式进入安装和配置阶段:
- 将该软件放到linux系统中,解压,为了方便,修改一下文件名和权限;
- 设置环境变量;
#vi /etc/profile
加上一行:export HADOOP_HOME=/usr/local/Hadoop
在PATH后添加:$HADOOP_HOME/bin:
然后执行这个命令让其立即生效:
#source /etc/profile
3. 修改hadoop的配置文件,用以实现伪分布,这里主要修改4个配置文件:
(1) Hadoop-env.sh
主要是修改jdk的路径:
在该文件的第9行,修改JAVA_HOME的路径,根据自己的实际情况就行。
(2) Core-site.xml
在configuration里面加入一下配置代码,需要注意自己的主机名,即最开始修改的hostname:
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/usr/local/Hadoop/tmp</value>
</property>
(3) Hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
<property>
<property>
<name>dfs.permission</name>
<value>true</value>
<property>
(4) Mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>Hadoop:9001</value>
</property>
4. 待配置完成后,需要对hadoop进行格式化,很多哦人开始不理解。这样想就行了,因为HDFS是一个文件系统,专门用来存储的。想想U盘什么的都需要格式化。
格式化的命令为:#hadoop namenode –format
(总结:如果启动后发现有进程没有启动,需要重新格式化,那么首先得把已经启动了的进程停止掉,才能进行操作。#stop-all.sh)
5. 启动Hadoop:
命令:#start-all.sh (注意:中间没有空格)
很自然能想到关闭停止的命令:#stop-all.sh
可以进行单个启动和关闭。
启动完成后,需要验证是否正确,用命令jps来验证,注意不是jsp:
#jps
这时会出现5个java进程(一共6个,其中包含一个jps),分别为:
SecondaryNameNode DataNode TaskTracker NameNode JobTracker Jps
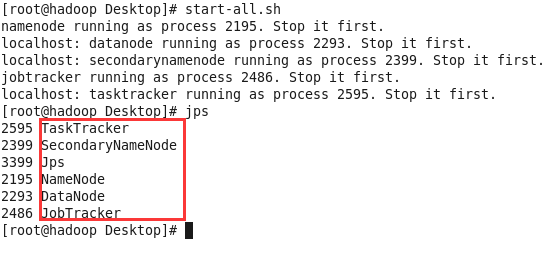
这样就算安装成功了!如果还不甘心,希望在浏览器中查看,不慌。这就说来。
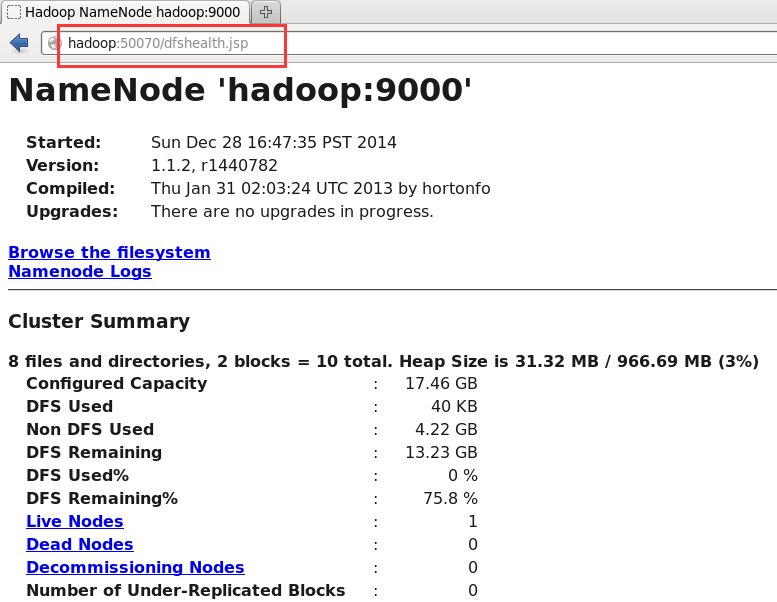
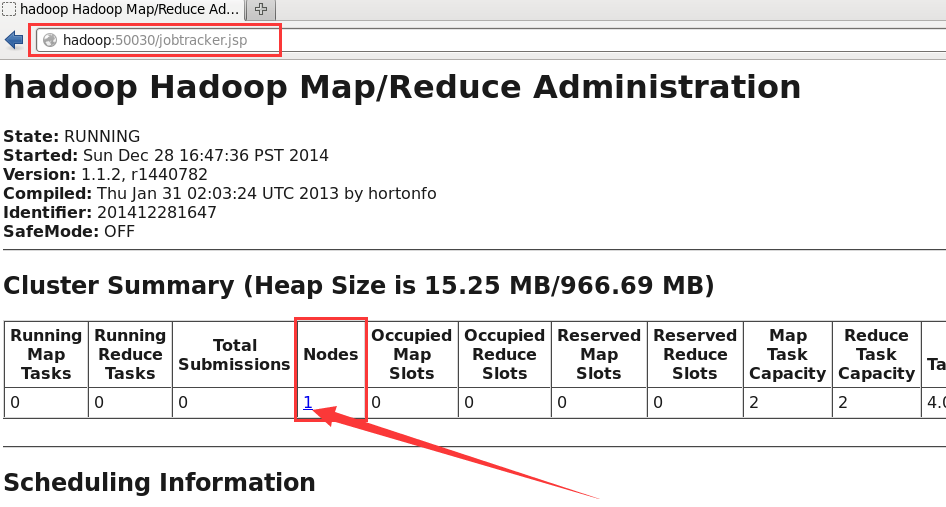
如果你的操作界面时命令行模式,首先#startx 进入操作系统的界面模式,然后打开浏览器,在浏览器中输入hadoop:50070或输入 Hadoop:50030就可以看到如下界面:
hadoop:50070页面:
hadoop:50030页面:
关于某进程没有启动的常见解决办法:
HDFS在安装后没有格式化;
4个配置文件修改可能存在问题;
Hostname与ip没有绑定;
Ssh的免密码登录没有配置成功。
如果确保没有任何操作失误,或者在多次格式化后,还是不能启动某个进程,那么去删除/usr/local/Hadoop/目录下的tmp文件夹,然后再重新格式化。应该就没有什么问题了。
那么如何在myeclipse中查看Hadoop的源码呢?
首先解压hadoop软件。我使用的版本是:hadoop-1.1.2.tar.gz
解压后的文件目录结构如下:
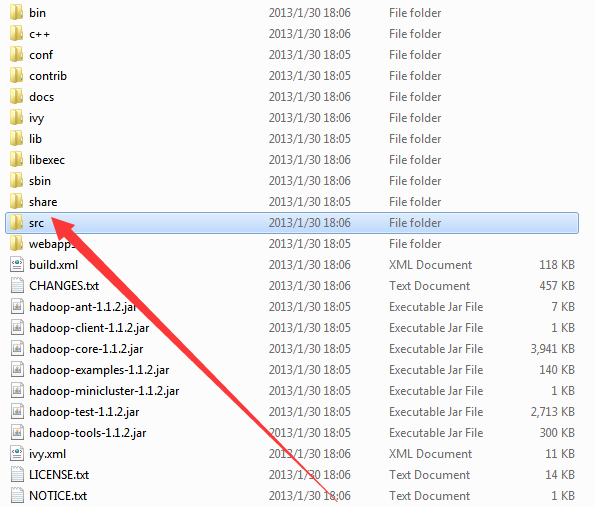
然后打开myeclipse,新建一个java工程,把src目录下的core文件夹,hdfs文件夹,mapred文件夹拷贝到src目录下。然后选择你的jdk,然后把那个src包调一下,就可以打开看到Hadoop的源码了。
作者:itRed
邮箱:it_red@sina.com
博客:http://www.cnblogs.com/itred
***版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。
Hadoop入门学习笔记---part2的更多相关文章
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记(一)
Week2 学习笔记 Hadoop核心组件 Hadoop HDFS(分布式文件存储系统):解决海量数据存储 Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度 Hadoop Map ...
- Hadoop入门学习笔记总结系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop入门学习笔记之一
http://hadoop.apache.org/docs/r1.2.1/api/index.html 适当的利用 null 在map中可以实现对文件的简单处理,如排序,和分集合输出等. 需要关心的内 ...
- Hadoop入门学习笔记(二)
Yarn学习 YARN简介 YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 YARN功能说明 资源管理系统:集群的硬件资源,和程序运行相关,比如内存.CPU等. 调度平 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
随机推荐
- 【noip 2005】 采药
题目描述 辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师.为此,他想拜附近最有威望的医师为师.医师为了判断他的资质,给他出了一个难题.医师把他带到一个到处都是草药的山洞里对他说:" ...
- markdown预览-快速入门
最近要写文档,领导指定用markdown. 这个两三年前用过两次的神器工具,都忘的差不多了. 为了熟练一点这个技能,决定好好的重新学一次. 于是乎:看快速入门文档 ...30分钟...看完文档发现要来 ...
- IntelliJ IDEA 15 激活码 正版 可离线激活
43B4A73YYJ-eyJsaWNlbnNlSWQiOiI0M0I0QTczWVlKIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiI ...
- 封装自己的DB类(PHP)
封装一个DB类,用来专门操作数据库,以后凡是对数据库的操作,都由DB类的对象来实现.这样有了自己的DB类,写项目时简单的sql语句就不用每次写了,直接调用就行,很方便! 1.封装一个DB类.一个类文件 ...
- AndroidStudio错误总结及解决(待续)
AndroidStudio错误总结及解决 一. 当安装好AndroidStudio开启的时候出现如下错误: 百度的解决方法: 1)进入刚安装的Android Studio目录下的bin目录.找到ide ...
- SDOI 2016 排列计数
题目大意:一个数列A,n个元素,其中m个元素不动,其他元素均不在相应位置,问有多少种排列 保证m个元素不动,组合数学直接计算,剩余元素错位排列一下即可 #include<bits/stdc++. ...
- Azure Redis Cache
将于 2014 年 9 月 1 日停止Azure Shared Cache服务,因此你需要在该日期前迁移到 Azure Redis Cache.Azure Redis Cache包含以下两个层级的产品 ...
- [PDO绑定参数]使用PHP的PDO扩展进行批量更新操作
最近有一个批量更新数据库表中某几个字段的需求,在做这个需求的时候,使用了PDO做参数绑定,其中遇到了一个坑. 方案选择 笔者已知的做批量更新有以下几种方案: 1.逐条更新 这种是最简单的方案,但无疑也 ...
- 【译】PHP的变量实现(给PHP开发者的PHP源码-第三部分)
文章来自:http://www.aintnot.com/2016/02/12/phps-source-code-for-php-developers-part3-variables-ch 原文:htt ...
- Lesson 7 Too late
Text The plane was late and detectives were waiting at the airport all morning. They were expecting ...