logistic回归 python代码实现
1. 读取数据集
def load_data(filename,dataType):
return np.loadtxt(filename,delimiter=",",dtype = dataType) def read_data():
data = load_data("data2.txt",np.float64)
X = data[:,0:-1]
y = data[:,-1]
return X,y
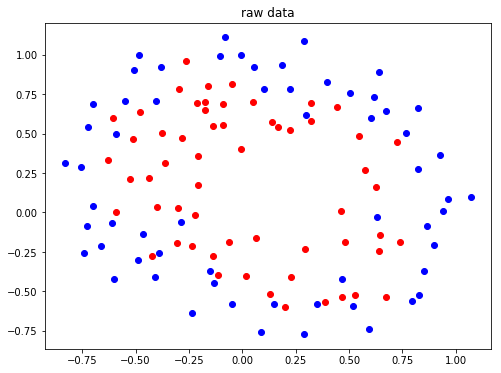
2. 查看原始数据的分布
def plot_data(x,y):
pos = np.where(y==1) # 找到标签为1的位置
neg = np.where(y==0) #找到标签为0的位置 plt.figure(figsize=(8,6))
plt.plot(x[pos,0],x[pos,1],'ro')
plt.plot(x[neg,0],x[neg,1],'bo')
plt.title("raw data")
plt.show() X,y = read_data()
plot_data(X,y)
结果:
3. 将数据映射为多项式
由原图数据分布可知,数据的分布是非线性的,这里将数据变为多项式的形式,使其变得可分类。
映射为二次方的形式: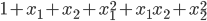
def mapFeature(x1,x2):
degree = 2; #映射的最高次方
out = np.ones((x1.shape[0],1)) # 映射后的结果数组(取代X) for i in np.arange(1,degree+1):
for j in range(i+1):
temp = x1 ** (i-j) * (x2**j)
out = np.hstack((out,temp.reshape(-1,1)))
return out
4. 定义交叉熵损失函数
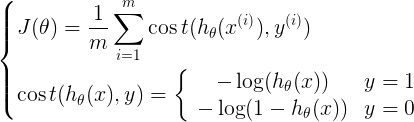
可以综合起来为: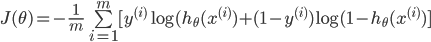
其中: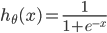
为了防止过拟合,加入正则化技术: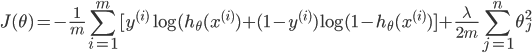
注意j是重1开始的,因为theta(0)为一个常数项,X中最前面一列会加上1列1,所以乘积还是theta(0),feature没有关系,没有必要正则化
def sigmoid(x):
return 1.0 / (1.0+np.exp(-x)) def CrossEntropy_loss(initial_theta,X,y,inital_lambda): #定义交叉熵损失函数
m = len(y)
h = sigmoid(np.dot(X,initial_theta))
theta1 = initial_theta.copy() # 因为正则化j=1从1开始,不包含0,所以复制一份,前theta(0)值为0
theta1[0] = 0 temp = np.dot(np.transpose(theta1),theta1)
loss = (-np.dot(np.transpose(y),np.log(h)) - np.dot(np.transpose(1-y),np.log(1-h)) + temp*inital_lambda/2) / m
return loss
5. 计算梯度
对上述的交叉熵损失函数求偏导:
利用梯度下降法进行优化:
def gradientDescent(initial_theta,X,y,initial_lambda,lr,num_iters):
m = len(y) theta1 = initial_theta.copy()
theta1[0] = 0
J_history = np.zeros((num_iters,1)) for i in range(num_iters):
h = sigmoid(np.dot(X,theta1))
grad = np.dot(np.transpose(X),h-y)/m + initial_lambda * theta1/m
theta1 = theta1 - lr*grad
#print(theta1)
J_history[i] = CrossEntropy_loss(theta1,X,y,initial_lambda)
return theta1,J_history
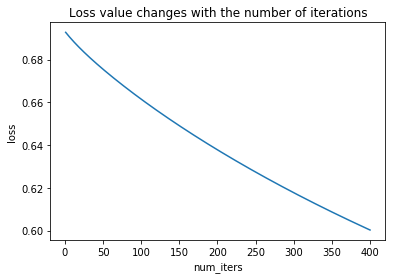
6. 绘制损失值随迭代次数的变化曲线
def plotLoss(J_history,num_iters):
x = np.arange(1,num_iters+1)
plt.plot(x,J_history)
plt.xlabel("num_iters")
plt.ylabel("loss")
plt.title("Loss value changes with the number of iterations")
plt.show()
7. 绘制决策边界
def plotDecisionBoundary(theta,x,y):
pos = np.where(y==1) #找到标签为1的位置
neg = np.where(y==0) #找到标签为2的位置 plt.figure(figsize=(8,6))
plt.plot(x[pos,0],x[pos,1],'ro')
plt.plot(x[neg,0],x[neg,1],'bo')
plt.title("Decision Boundary") #生成和原数据类似的数据
u = np.linspace(-1,1.5,50)
v = np.linspace(-1,1.5,50)
z = np.zeros((len(u),len(v)))
#利用训练好的参数做预测
for i in range(len(u)):
for j in range(len(v)):
z[i,j] = np.dot(mapFeature(u[i].reshape(1,-1),v[j].reshape(1,-1)),theta) z = np.transpose(z)
plt.contour(u,v,z,[0,0.01],linewidth=2.0) # 画等高线,范围在[0,0.01],即近似为决策边界
plt.legend()
plt.show()
8.主函数
if __name__ == "__main__":
#数据的加载
x,y = read_data()
X = mapFeature(x[:,0],x[:,1])
Y = y.reshape((-1,1))
#参数的初始化
num_iters = 400
lr = 0.1
initial_theta = np.zeros((X.shape[1],1)) #初始化参数theta
initial_lambda = 0.1 #初始化正则化系数
#迭代优化
theta,loss = gradientDescent(initial_theta,X,Y,initial_lambda,lr,num_iters)
plotLoss(loss,num_iters)
plotDecisionBoundary(theta,x,y)
9.结果

logistic回归 python代码实现的更多相关文章
- 机器学习实战 logistic回归 python代码
# -*- coding: utf-8 -*- """ Created on Sun Aug 06 15:57:18 2017 @author: mdz "&q ...
- Logistic回归 python实现
Logistic回归 算法优缺点: 1.计算代价不高,易于理解和实现2.容易欠拟合,分类精度可能不高3.适用数据类型:数值型和标称型 算法思想: 其实就我的理解来说,logistic回归实际上就是加了 ...
- Logistic回归python实现
2017-08-12 Logistic 回归,作为分类器: 分别用了梯度上升,牛顿法来最优化损失函数: # -*- coding: utf-8 -*- ''' function: 实现Logistic ...
- Logistic回归python实现小样例
假设现在有一些点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,依次进行分类.Lo ...
- logistic 回归Matlab代码
function a alpha = 0.0001; [m,n] = size(q1x); max_iters = 500; X = [ones(size(q1x,1),1), q1x]; % app ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
- Logistic回归模型和Python实现
回归分析是研究变量之间定量关系的一种统计学方法,具有广泛的应用. Logistic回归模型 线性回归 先从线性回归模型开始,线性回归是最基本的回归模型,它使用线性函数描述两个变量之间的关系,将连续或离 ...
随机推荐
- JavaScript之深入对象(一)
在之前的<JavaScript对象基础>中,我们大概了解了对象的创建和使用,知道对象可以使用构造函数和字面量方式创建.那么今天,我们就一起来深入了解一下JavaScript中的构造函数以及 ...
- 基于SpringBoot实现AOP+jdk/CGlib动态代理详解
动态代理是一种设计模式.在Spring中,有俩种方式可以实现动态代理--JDK动态代理和CGLIB动态代理. JDK动态代理 首先定义一个人的接口: public interface Person { ...
- 读《深入理解Elasticsearch》点滴-对象类型、嵌套文档、父子关系
一.对象类型 1.mapping定义文件 "title":{ "type":"text" }, "edition":{ ...
- Flume初见与实践
Photo by Janke Laskowski on Unsplash 参考书籍:<Flume构建高可用.可扩展的海量日志采集系统> --Hari Shreedharan 著 以下简称& ...
- RocketMQ初入门踩坑记
本文主要是讲在Centos中安装RocketMQ并做简单的示例.如果你按照本文安装100%是可以成功的,如果按照阿里官方的说明,那只能呵呵了~ 安装 官方地址为:https://rocketmq.ap ...
- restapi(7)- 谈谈函数式编程的思维模式和习惯
国庆前,参与了一个c# .net 项目,真正重新体验了一把搬砖感觉:在一个多月时间好像不加任何思考,不断敲键盘加代码.我想,这也许是行业内大部分中小型公司程序猿的真实写照:都是坐在电脑前的搬砖工人.不 ...
- K8s 从懵圈到熟练 – 集群网络详解
作者 | 声东 阿里云售后技术专家 导读:阿里云 K8S 集群网络目前有两种方案:一种是 flannel 方案:另外一种是基于 calico 和弹性网卡 eni 的 terway 方案.Terway ...
- navicat工具 pymysql模块
目录 一 IDE工具介绍(Navicat) 二 pymysql模块 一 IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navi ...
- MongoDB 学习笔记之 查询表达式
查询表达式: db.stu.find().count() db.stu.find({name: 'Sky'}) db.stu.find({age: {$ne: 20}},{name: 1, age: ...
- 安装vant2.2.7版本报错These dependencies were not found: vant/es/goods-action-big-btn in ./src/config/vant.config.js......
一.问题 前天,在使用vant的checkbox复选框的时候,注意到新增加一个全选功能,通过 ref 可以获取到 CheckboxGroup 实例并调用实例方法.于是我就想用这个,但是按照上面的示例写 ...