Learning Discriminative Features with Class Encoder
近来论文看了许多,但没多少时间总结下来。今天暂时记录一篇比较旧的论文,选择理由是 Discriminative features。
做图像说白了就是希望有足够有判别性的特征,这样在分类或者匹配、检索的时候才能有较好的精度。
一. 综述
这篇论文思想很简单。如何称之为有判别性的特征?作者利用编码器的思想,对于同一ID的图形的特征,如果编码后仍可以较好的解码为同一ID的特征,那么我们就说这个特征有判别力。这里有个点值得注意:编码器是针对图像特征,非图像本身。好的特征表示大概有2个衡量标准:可以很好的重构出输入数据、对输入数据一定程度下的扰动具有不变性。普通的autoencoder、sparse autoencoder、stacked autoencoder则主要符合第一个标准,而deniose autoencoder和contractive autoencoder则主要体现在第二个。在一些分类任务中,第二个标准显得更加重要。
二. 摘要
编码器一般用在非监督领域,这里将编码器加在监督学习里,为了学得的特征有好的判别性。这里利用编解码器来重建同一label的个体的特征。这样做是为了最小化类内方差。
三. 介绍
有许多重建模型算法:DAE(denoising auto-encoder)、CAE(contractive auto-encoder)。但这些算法都是在非监督领域,为了获得更有判别性的特征还得是监督学习。所以作者将编码器思想与监督学习(softmax传统监督分类)结合到了一起。此外作者指出AE对于图像变换不够鲁棒。传统AE限于小图、对齐的简单图像。作者提出class-encoder作为softmax classifier的一个限制项(辅助),从而优于纯softmax。
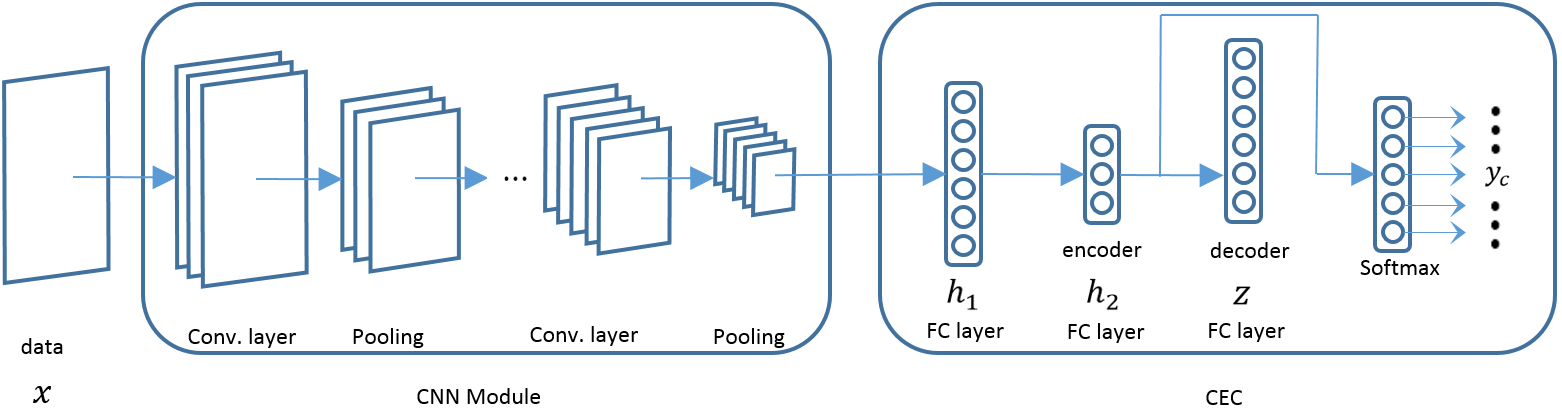
结构如下:
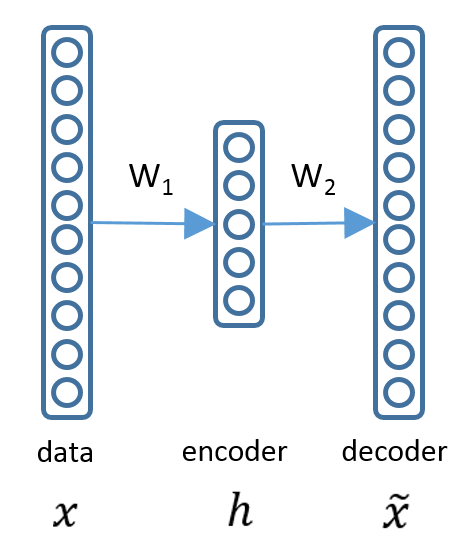
x为输入数据(特征),h为隐层,xhat为重构(同一label的特征)。那么最小化重构损失即可:
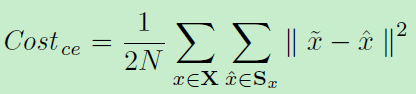
所以整体模型即为两支路:利用编码器优化特征、利用softmax分类:
同样,作者验证隐层一层就够好,但是隐层神经元数目不同结果也不同:
最终实验验证了加上编码器的softmax要优于纯softmax。有个点是:作者采取了一层卷积和两层局部连接层 two locally-connected layers,类似于卷积,但是层间不共享参数。因此它适用于提取一组有规律的图像:例如人脸。
四. 结论
该模型只用到了类内的对,也就是正样本对,没有用到任何不匹配对。而其他算法(DeepID2)同时利用了正负对,这说明负对的贡献在训练中是比较小的。类内重建是有助于学习鲁棒、有判别性的特征。在特征层面上的策略很好解决了FC net的上的尺寸以及变换问题。
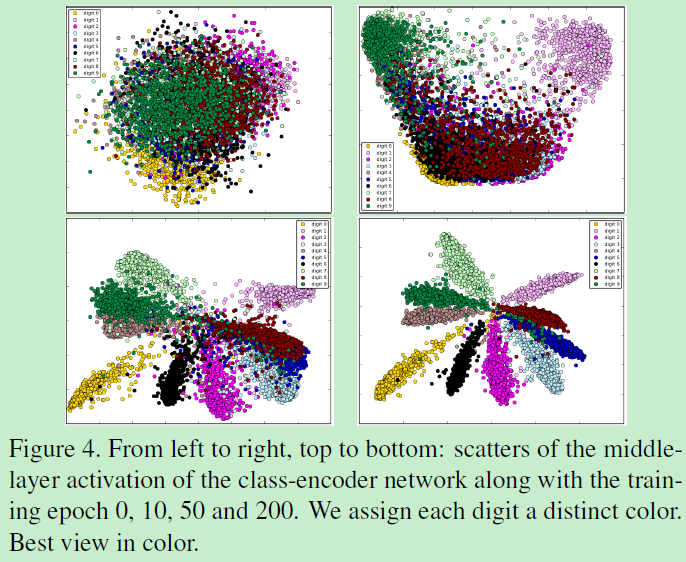
附:特征向量feature embedding:每列为同一ID:

Learning Discriminative Features with Class Encoder的更多相关文章
- Paper-[arXiv 1710.03144]Island Loss for Learning Discriminative Features in Facial Expression
[arXiv 1710.03144]Island Loss for Learning Discriminative Features in Facial Expression ABSTRACT 作者在 ...
- Machine Learning : Pre-processing features
from:http://analyticsbot.ml/2016/10/machine-learning-pre-processing-features/ Machine Learning : Pre ...
- 【DeepLearning】Exercise:Learning color features with Sparse Autoencoders
Exercise:Learning color features with Sparse Autoencoders 习题链接:Exercise:Learning color features with ...
- 【Discriminative Localization】Learning Deep Features for Discriminative Localization 论文解析(转)
文章翻译: 翻译 以下文章来源: 链接
- Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition
承接上上篇博客,在其基础上,加入了Wasserstein distance和correlation prior .其他相关工作.网络细节(maxout operator).训练方式和数据处理等基本和前 ...
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
1.主要完成的任务是能够将英文转译为法文,使用了一个encoder-decoder模型,在encoder的RNN模型中是将序列转化为一个向量.在decoder中是将向量转化为输出序列,使用encode ...
- 论文笔记:Learning Region Features for Object Detection
中心思想 继Relation Network实现可学习的nms之后,MSRA的大佬们觉得目标检测器依然不够fully learnable,这篇文章类似之前的Deformable ROI Pooling ...
- Learning Rich Features from RGB-D Images for Object Detection and Segmentation论文笔记
相关工作: 将R-CNN推广到RGB-D图像,引入一种新的编码方式来捕获图像中像素的地心姿态,并且这种新的编码方式比单纯使用深度通道有了明显的改进. 我们建议在每个像素上用三个通道编码深度图像:水平视 ...
- Learning Discriminative and Transformation Covariant Local Feature Detectors实验环境搭建详细过程
依赖项: Python 3.4.3 tensorflow>1.0.0, tqdm, cv2, exifread, skimage, glob 1.安装tensorflow:https://www ...
随机推荐
- js 各种事件 如:点击事件、失去焦点、键盘事件等
事件驱动: 我们点击按钮 按钮去掉用相应的方法. demo: <input type="button" v ...
- go logs
安装导入 go get github.com/astaxie/beego/logs import "github.com/astaxie/beego/logs" 使用 packag ...
- git ssh https 踩坑记 ---- 域账号密码更新
前几天突然通知要更新公司的域账号密码,然后git pull就一直报 fatal: Authentication failed for 'https://git ... 很奇怪的是,有一个项目git p ...
- jdk7 并行计算框架Fork/Join
故名思义,拆分fork+合并join.jdk1.7整合Fork/Join,性能上有大大提升. 思想:充分利用多核CPU把计算拆分成多个子任务,并行计算,提高CPU利用率大大减少运算时间.有点像,Map ...
- springcloud 服务调用的两种方式
spring-cloud调用服务有两种方式,一种是Ribbon+RestTemplate, 另外一种是Feign.Ribbon是一个基于HTTP和TCP客户端的负载均衡器,其实feign也使用了rib ...
- hdu 6385
题意是在一个矩形中任给N个点,求这N个点到矩形某边的最短距离和. 一开始想到直接贪心,求出每个点到矩形一边的最短距离,但题中说到线段间不能交叉,这里好像是比较麻烦,但题目中同时说了点与点之间的横纵坐标 ...
- string类型用法大全
使用标准C++中string类,要包含头文件< string > string类的构造函数 //string(const char *s); 用字符串s初始化 string s1(&quo ...
- CentOS7 安装 Tomcat8
安装 Java8准备更新软件yum update 如果提示没有 wget 命令,那么必须先安装 wget 如下:yum install wget 安装Tomcat8这里采用离线解压tar.gz的方式安 ...
- mongoDB与mongoose
mongodb是一个基于分布式文件存储的文档型数据库 MongoDB 是一个介于关系数据库和非关系数据库之间的产品 MongoDB 最大的特点是他支持的查询语言非常强大,而且还支持对数据建立索引 官方 ...
- [Android] Android 使用 Greendao 操作 db sqlite
Android 使用 Greendao 操作 db sqlite GreenDAO是一个开源的安卓ORM框架,能够使SQLite数据库的开发再次变得有趣.它减轻开发人员处理低级数据库需求,同时节省开发 ...