spark内存分配
问题描述
在测试spark on yarn时,发现一些内存分配上的问题,具体如下。
在$SPARK_HOME/conf/spark-env.sh中配置如下参数:
SPARK_EXECUTOR_INSTANCES=4 在yarn集群中启动的executor进程数
SPARK_EXECUTOR_MEMORY=2G 为每个executor进程分配的内存大小
SPARK_DRIVER_MEMORY=1G 为spark-driver进程分配的内存大小
执行$SPARK_HOME/bin/spark-sql –master yarn,按yarn-client模式启动spark-sql交互命令行(即driver程序运行在本地,而非yarn的container中),日志显示的关于AppMaster和Executor的内存信息如下:

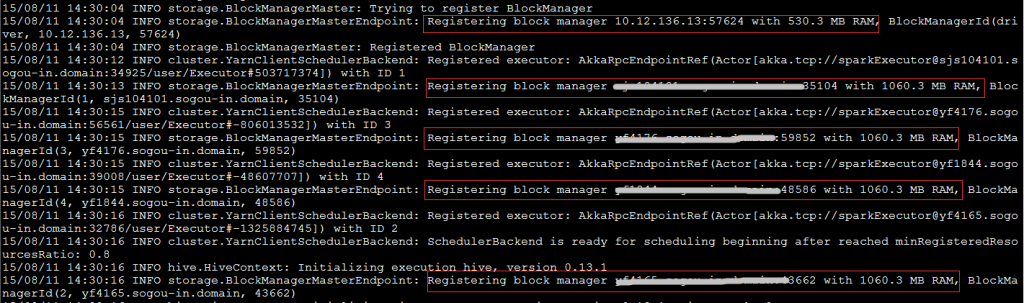
日志显示,AppMaster的内存是896MB,其中包含了384MB的memoryOverhead;启动了5个executor,第一个的可用内存是530.3MB,其余每个Executor的可用内存是1060.3MB。
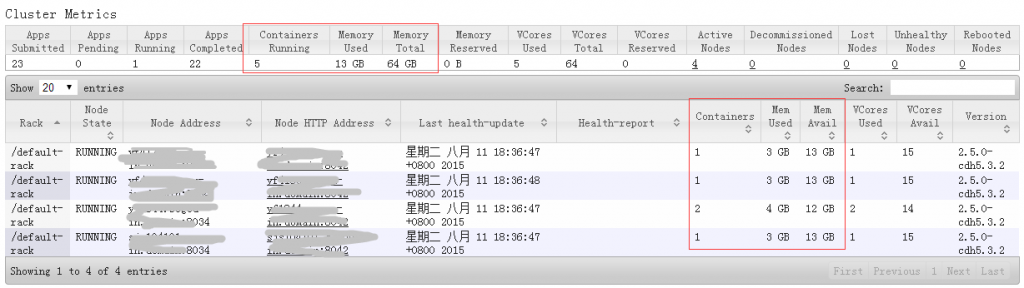
到yarnUI看下资源使用情况,共启动了5个container,占用内存13G,其中一台NodeManager启动了2个container,占用内存4G(1个AppMaster占1G、另一个占3G),另外3台各启了1个container,每个占用3G内存。
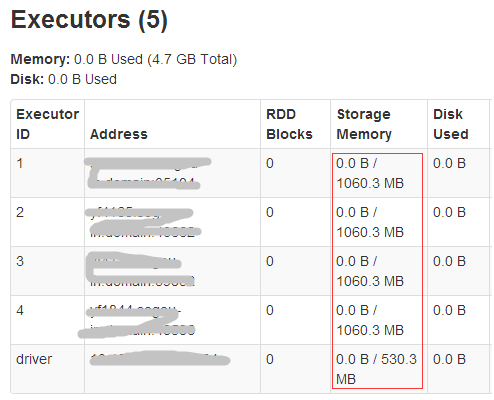
再到sparkUI看下executors的情况,这里有5个executor,其中driver是运行在执行spark-sql命令的本地服务器上,另外4个是运行在yarn集群中。Driver的可用storage
memory为530.3MB,另外4个都是1060.3MB(与日志信息一致)。
那么问题来了:
Yarn为container分配的最小内存由yarn.scheduler.minimum-allocation-mb参数决定,默认是1G,从yarnUI中看确实如此,可为何spark的日志里显示AppMaster的实际内存是896-384=512MB呢?384MB是怎么算出来的?
spark配置文件里指定了每个executor的内存为2G,为何日志和sparkUI上显示的是1060.3MB?
driver的内存配置为1G,为何sparkUI里显示的是530.3MB呢?
为何yarn中每个container分配的内存是3G,而不是executor需要的2G呢?
问题解析
进过一番调研,发现这里有些概念容易混淆,整理如下,序号对应上面的问题:
- spark的yarn-client向ResourceManager申请提交作业/启动AppMaster时,会判断是否是集群模式,如果是集群模式,则AppMaster的内存大小与driver内存大小一致,否则由spark.yarn.am.memory决定,这个参数的默认值是512MB。我们使用的是yarn-client模式,所以实际内存是512MB。
384MB是spark-client为appMaster额外申请的内存,计算方法如下:

即,默认从参数读取(集群模式从spark.yarn.driver.memoryOverhead参数读,否则从spark.yarn.am.memoryOverhead参数读),若没配此参数,则从AppMaster的内存*一定系数和默认最小overhead中取较大值。
在spark-1.4.1版本中,MEMORY_OVERHEAD_FACTOR的默认值为0.10(之前是0.07),MEMORY_OVERHEAD_MIN默认为384,我们没有指定spark.yarn.driver.memoryOverhead和spark.yarn.am.memoryOverhead,而amMemory=512M(由spark.yarn.am.memory决定),因此memoryOverhead为max(512*0.10,
384)=384MB。
Executor的memoryOverhead计算方法与此一样,只是不区分是否集群模式,都默认由spark.yarn.executor.memoryOverhead配置。
- 日志和sparkUI上显示的是executor内部用于缓存计算结果的内存空间,并不是executor所拥有的全部内存。这部分内存是由以下公式计算:

Runtime.getRuntime.maxMemory按2048MB算,storage memory大小为1105.92MB,sparkUI显示的略小于此值,是正常的。
与上述第2点一样,storage memory的大小略小于1024*0.9*0.6=552.96MB
前面提到spark会为container额外申请一部分内存(memoryOverhead),因此,实际为container提交申请的内存大小是2048
+ max(2048*0.10, 384) =
2432MB,而yarn在做资源分配时会做资源规整化,即应用程序申请的资源量一定是最小可申请资源量的整数倍(向上取整),最小可申请内存量由yarn.scheduler.minimum-allocation-mb指定,因此,会为container分配3G内存。
———————————————————
验证
为了验证上述规则,继续修改配置参数:
SPARK_EXECUTOR_INSTANCES=4 在yarn集群中启动的executor进程数
SPARK_EXECUTOR_MEMORY=4G 为每个executor进程分配的内存大小
SPARK_DRIVER_MEMORY=3G 为spark-driver进程分配的内存大小
并在启动spark-sql时指定spark.yarn.am.memory参数:
bin/spark-sql –master yarn –conf spark.yarn.am.memory=1024m
再看日志信息:

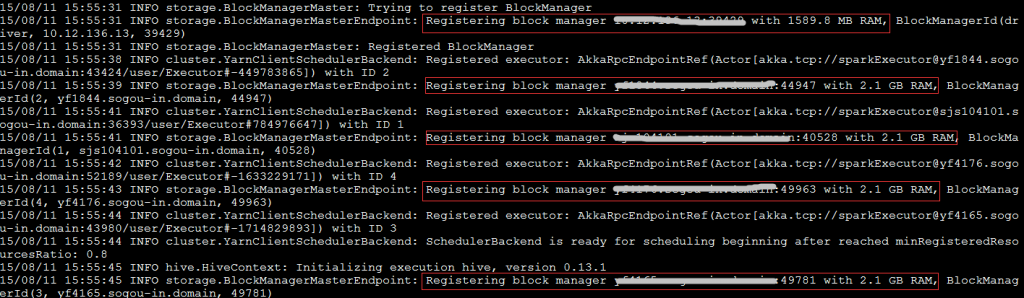
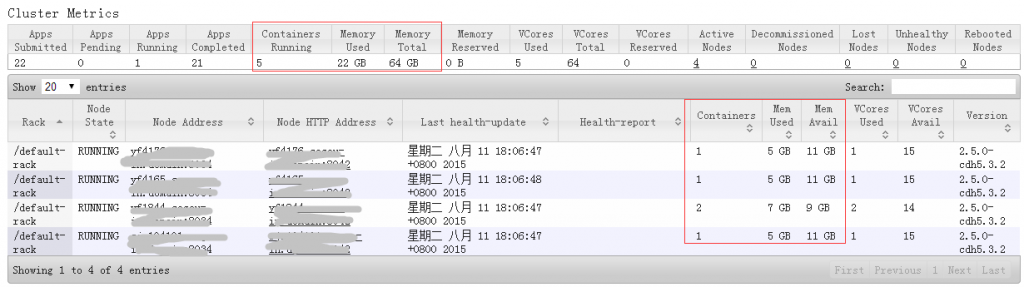
yarnUI状态:
sparkUI的executors信息:
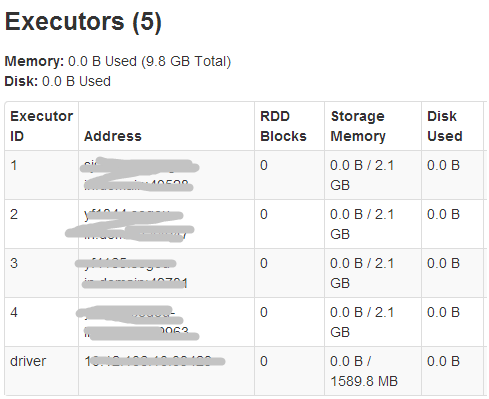
可见,AppMaster的实际内存为1024M(1408-384),而其在yarn中的container内存大小为2G(1408大于1G,yarn按资源规整化原则为其分配2G)。
同理,driver的storage memory空间为3G*0.9*0.6=1.62G,executor的storage
memory空间为4G*0.9*0.6=2.16G,executor所在container占用5G内存(4096+max(4096*0.10,384)=
4505.6,大于4G, yarn按资源规整化原则为其分配5G)。
Yarn集群的内存总占用空间为2+5*4=22G。
实际遇到的真实问题,解决方法:
1.调整虚拟内存率yarn.nodemanager.vmem-pmem-ratio (这个hadoop默认是2.1)
2.调整map与reduce的在AM中的大小大于yarn里RM可分配的最小值yarn.scheduler.minimum-allocation-mb 大小因为在Container中计算使用的虚拟内存来自
map虚拟内大小=max(yarn.scheduler.minimum-allocation-mb,mapreduce.map.memory.mb) * yarn.nodemanager.vmem-pmem-ratio,同理reduce虚拟内存大小也是这样计算...
具体说明相关参数含义[文章参考:http://blog.chinaunix.net/uid-25691489-id-5587957.html与https://blog.csdn.net/u012042963/article/details/53099638]:
ResourceManager配置:
RM的内存资源配置,主要是通过下面的两个参数进行的(这两个值是Yarn平台特性,应在yarn-site.xml中配置好):
yarn.scheduler.minimum-allocation-mb
yarn.scheduler.maximum-allocation-mb
说明:单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,小于最小值则分配最小值,从这个角度看,最小值有点想操作系统中的页;
最小值还有另外一种用途,计算一个节点的最大container数目。注!!:这两个值一经设定不能动态改变(此处所说的动态改变是指应用运行时)。
NodeManager配置:
NM的内存资源配置,主要是通过下面两个参数进行的(这两个值是Yarn平台特性,应在yarn-sit.xml中配置) :
yarn.nodemanager.resource.memory-mb ===>每个节点可用的最大内存
yarn.nodemanager.vmem-pmem-ratio ===>虚拟内存率
说明:每个节点可用的最大内存:
RM中的两个值(yarn.scheduler.minimum-allocation-mb与yarn.scheduler.maximum-allocation-mb)不应该超过此值,
此数值可以用于计算container最大数目,即:用此值除以RM中的最小容器内存;
虚拟内存率:
是占task所用内存的百分比,默认值为2.1倍,
注意!!:第一个参数是不可修改的,一旦设置,整个运行过程中不可动态修改,且该值的默认大小是8G,即使计算机内存不足8G也会按着8G内存来使用。
ApplicationMaster配置:
AM内存配置相关参数,此处以MapReduce为例进行说明(这两个值是AM特性,应在mapred-site.xml中配置),如下:
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
说明:这两个参数指定用于MapReduce的两个任务(Map
and Reduce
task)的内存大小,其值应该在RM中的最大(yarn.scheduler.maximum-allocation-mb)最小(yarn.scheduler.minimum-allocation-mb)container之间,如果没有配置则通过如下简单公式获得:
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
一般的reduce应该是map的2倍。
注!!:这两个值可以在应用启动时通过参数改变
AM中JVM相关设置:
AM中其它与内存相关的参数,还有JVM相关的参数,这些参数可以通过如下选项配置:
mapreduce.map.java.opts
mapreduce.reduce.java.opts
说明:这两个参主要是为需要运行JVM程序(java、scala等)准备的,通过这两个设置可以向JVM中传递参数的,与内存有关的是,-Xmx,-Xms等选项;此数值大小,应该在AM中的mapreduce.map.memory.mb和mapreduce.reduce.memory.mb之间。
实际案例:
Container
[pid=108284,containerID=container_e19_1533108188813_12125_01_000002] is
running beyond virtual memory limits. Current usage: 653.1 MB of 2 GB
physical memory used; 5.4 GB of 4.2 GB virtual memory used. Killing
container.

<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
<source>yarn-default.xml</source>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
<source>yarn-default.xml</source>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
<source>yarn-default.xml</source>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
<source>yarn-default.xml</source>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<source>mapred-default.xml</source>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<source>mapred-default.xml</source>
</property>
通过配置我们看到,容器的最小内存和最大内存分别为:1024m和8192m,而reduce设置的默认值为1024m,map也是默认值,所以两个值都为1024m,所以两个值和为2G即是log中" 653.1 MB of 2 GB physical memory used" 这个2G。而由于使用了默认虚拟内存率(也就是2.1倍),所以对于Map Task和Reduce Task总的虚拟内存为都为2*2.1=4.2G,这个4.2也是log中的"5.4 GB of 4.2 GB virtual memory used" 计算的这个虚拟内存。而应用的虚拟内存超过了这个数值,故报错 。解决办法:在启动Yarn是调节虚拟内存率或者应用运行时调节内存大小
另外一个案例:
Container[pid=41884,containerID=container_1405950053048_0016_01_000284] is running beyond virtual memory limits. Current usage: 314.6 MB of 2.9 GB physical memory used; 8.7 GB of 6.2 GB virtual memory used. Killing container.
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>100000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>3000</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2000</value>
</property>
通过配置我们看到,容器的最小内存和最大内存分别为:3000m和10000m,而reduce设置的默认值小于2000m,map没有设置,所以两个值均为3000m,也就是log中的“2.9 GB physical
memory used”。而由于使用了默认虚拟内存率(也就是2.1倍),所以对于Map Task和Reduce Task总的虚拟内存为都为3000*2.1=6.2G。而应用的虚拟内存超过了这个数值,故报错 。解决办
法:在启动Yarn是调节虚拟内存率或者应用运行时调节内存大小。
这个调整对应用非常有用!!!
spark内存分配的更多相关文章
- Spark内存分配诊断
1.JVM自带众多内存诊断的工具,例如:JMap,JConsole等,第三方IBM JVM Profile Tools等. 2.日志!在开发.测试.生产环境中最合适的就是日志,特别是Driver产生的 ...
- Spark Tungsten揭秘 Day3 内存分配和管理内幕
Spark Tungsten揭秘 Day3 内存分配和管理内幕 恭喜Spark2.0发布,今天会看一下2.0的源码. 今天会讲下Tungsten内存分配和管理的内幕.Tungsten想要工作,要有数据 ...
- Spark On YARN内存分配
本文转自:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 此文解决了Spark ...
- spark on yarn 内存分配
Spark On YARN内存分配 本文主要了解Spark On YARN部署模式下的内存分配情况,因为没有深入研究Spark的源代码,所以只能根据日志去看相关的源代码,从而了解“为什么会这样,为什么 ...
- Spark记录-Spark On YARN内存分配(转载)
Spark On YARN内存分配(转载) 说明 按照Spark应用程序中的driver分布方式不同,Spark on YARN有两种模式: yarn-client模式.yarn-cluster模式. ...
- Spark在Executor上的内存分配
spark.serializer (default org.apache.spark.serializer.JavaSerializer ) 建议设置为 org.apache.spark.ser ...
- spark的内存分配管理
SPARK的内存管理器 StaticMemoryManager,UnifiedMemoryManager 1.6以后默认是UnifiedMemoryManager. 这个内存管理器在sparkCont ...
- Spark内存管理-UnifiedMemoryManager和StaticMemoryManager
在Spark-1.6.0中,引入了一个新的参数spark.memory.userLegacyMode(默认值为false),表示不使用Spark-1.6.0之前的内存管理机制,而是使用1.6.0中引入 ...
- RAMCloud:内存云存储的内存分配机制
现在全闪存阵列已经见怪不怪了,EMC的XtremIO,还有VNX-F(Rockies),IBM FlashSystem.全闪存真正为效率而生,重新定义存储速度.凭借极致性能,高可用性,为您极大提高企业 ...
随机推荐
- 开源在线分析诊断工具Arthas(阿尔萨斯)--总结
阿里重磅开源在线分析诊断工具Arthas(阿尔萨斯) arthas用法 启动demo java -jar arthas-demo.jar 启动 java -jar arthas-boot.jar at ...
- iptables和netfilter
1.iptables和netfilter说明 [1]netfilter/iptables组成Linux平台下的包过滤防火墙,iptables是用户空间的管理工具,netfilter是内核空间的包处理框 ...
- iOS XML解析使用-韩国庆
欢迎-------(北京-iOS移动开发金牌教师QQ:2592675215)韩老师给你带来XML解析课程 今天给大家讲解下xml解析的第三方简单用法:首先我解释下,json和xml解析格式. JSON ...
- codeblock 生成和使用makefile
下载cbp2make 文件名:cbp2make-stl-rev138.tar.gz 里面有个cbp文件用codeblock打开,编译,生成的bin目录下有个执行文件. 使用命令生成Makefile . ...
- 个人简介HTML
码云链接:https://gitee.com/lengxiaoyixuan222/codes/z4dxnvr0ce2blpkihsg7985 源代码: <!doctype html> &l ...
- Android 开发 将window变暗
前言 在创建弹窗功能时,一般有需求将背景的window界面变暗.下面两组代码就实现了变暗与恢复的功能. 变暗 public void startDark(){ WindowManager.Layout ...
- ORA-12560: TNS:protocol adapter error
C:\Users\dong>sqlplus/nolog SQL*Plus: Release 11.2.0.1.0 Production on Mon Nov 19 14:12:51 2018 C ...
- mysql 5.5数据导入5.7 Failed - Error on Table user - 1067 - Invalid default value for 'CREATE_date'
表结构是这样 DROP TABLE IF EXISTS `user`;CREATE TABLE `user` (....省略了一些无关紧要的字段 `CREATE_DATE_` timestamp NO ...
- 浅谈Android之Activity生命周期
Activity作为四大组件之一,出现的频率相当高,基本上我们在android的各个地方都能看见它的踪影,因此深入了解Activity,对于开发高质量应用程序是很有帮助的.今天我们就来详细地聊聊Ac ...
- 《python编程快速上手》
第一部分 编程基础 @表达式 ** % // @ >>> int(3.4) 3 >>>round(3.555,2)3.56 @判断条件时:0和0.0和‘’都是Fal ...