hadoop小结
测试小结:
1.如果只需要对数据集进行过滤,筛选则只需要编写Mapper类,不需要Reduce类,此时要执行下面一条语句:job.setNumReduceTesk(0);
2.如果需要对处理的数据进行分组(group by)、排序(order by)、表连接(join)、排重(distinct)等操作则需要编写Reducer类,因为这些操作都是基于MapTask的输出键(Key)来完成的;
3.如果既有分组又有排序只能使用两个MapReduce作业来串接完成,因为分组和排序会涉及到两次Shuffle过程;
分组与排序的本质何在?
分组是基于排序来完成,也就是说在分组之前其实上已经经过排序,从MapTask到ReduceTask的Shuffle的过程所使用的默认排序是升序,排序就是比较值的大小。
数字类型:直接根据数值大小进行比较;
字符串类型:根据字典序列(ASCII码值大小)进行比较;
大数据学习交流群:217770236 让我我们一起学习大数据
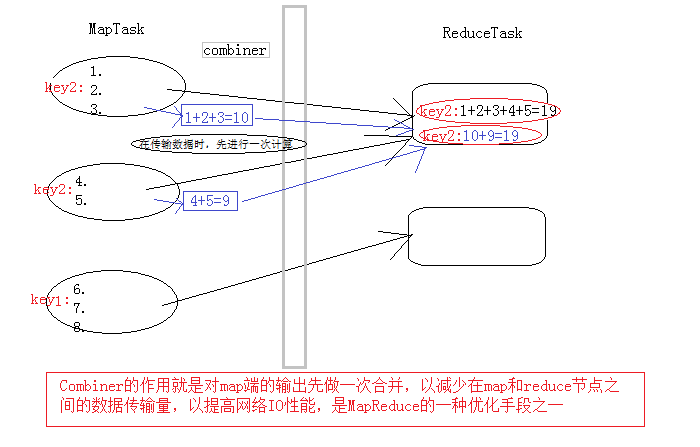
Combiner产生原因:
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一。Combiner是继承自Reducer类。
Combiner组件:
1.是在每个 map task 的本地运行,能收到map输出的每一个key的valuelist,所以可以做局部汇总处理
2.因为map task 的本地进行了局部汇总,就会让map端的输出数据大幅精简,减少shuffle过程的网络IO
3.Combiner其实就是一个reduce组件,与reduce的区别在于:Combiner运行maptask的本地
4.Combiner在使用时需要注意,输入输出KV数据类型要跟map和reduce的相应数据类型匹配(combiner的输入是map的输出;combiner的输出是reduce的输入)
5.要注意业务逻辑不能因为Combiner的加入而受影响。
那么在程序中的使用是:
可以直接在Runner类中main方法中:
在指定reduce类后,指定Combiner类即可:语句 wcjob.setCombinerClass(WordCountReducer.class);
因为Combiner实际就是reduce组件,所以可以使用之前指定的reduce即可。
Job wcjob = Job.getInstance(conf); 所以wcjob是job的实现类。
使用场景:即第五条中所述的情况;
不能使用场景:在求取平均数时,因为添加的Combiner组件是与reduce组件具有相同的逻辑,会提前求一次平均值后传给reduce类,导致求取的平均值错误。
使用卡宾类需要注意问题:
1.combiner类与普通的Reducer类都一样,继承于Reducer类;
2.combiner类的统计算法对于ReduceTask而言必须具有可拆解性,否则不能使用combiner;
3.如果你的conbiner类的算法与Reduce的算法完全一致,则可直接编写的Reducer类作为combiner;
| Hadoop中的分布式缓存:基于磁盘IO进行迭代,消耗较大,但是磁盘存储数据的性价比更高;主要做离线数据处理; |
| Spark是:基于内存进行迭代的,对于实时处理数据和处理稍微小点的数据更具有优势;主要做流式数据处理; |
| 当内存的容量能够达到很高并且购买内存花费也不高,即性价比和磁盘差距不大时,那么hadoop就将会面临被淘汰的危机。 |
hadoop集群分区:
1、分区是必须要经历Shuffle过程的,没有Shuffle过程无法完成分区操作
2、分区是通过MapTask输出的key来完成的,默认的分区算法是数组求模法:
数组求模法:
将Map的输出Key调用hashcode()函数得到的哈希吗(hashcode),此哈希吗是一个数值类型,将此哈希码数值直接与整数的最大值(Integer.MAXVALUE)取按位与(&)操作,将与操作的结果与ReducerTask
的数量取余数,将此余数作为当前Key落入的Reduce节点的索引;
-------------------------
Integer mod = (Key.hashCode()&Integer.MAXVALUE)%NumReduceTask;
被除数=34567234
NumReduceTask=3
-------结果:
0、1、2 这三个数作为Reduce节点的索引;
数组求模法是有HashPartitioner类来实现的,也是MapReduce分区的默认算法。
hadoop集群的性能和效率:
1、数据量需要达到一定的数量级使用hadoop集群来处理才是划算的
2、集群的计算性能取决于任务数量的多少,设置任务数量必须充分考虑到集群的计算能力(比如:物理节点数量);
a、Map设置的任务数量作为最小值参考
b、Reduce的任务数默认是1,如果设置了则启动设置的数量不管MapTask还是ReduceTask,
不管MapTask还是ReduceTask,只要任务数量越多则并发能力越强,处理效率会在一定程度上越高;但是,设置设置的任务数量必须参考集群中的物理节点数量,如果设置的任务数量过多,会导致每个物理节点上分摊的任务数量过多,处理器并发每个任务产生的计算开销越大,任务之间因处理负载导致相互之间的影响很大,任务失败率上升,计算性能反而下降(因为任务失败会重新请求,至多重新请求三次),因此在设计MapTask与ReduceTask任务数量时必须权衡利弊,折中考虑...
hadoop小结的更多相关文章
- 转载:Hadoop排序工具用法小结
本文转载自Silhouette的文章,原文地址:http://www.dreamingfish123.info/?p=1102 Hadoop排序工具用法小结 发表于 2014 年 8 月 25 日 由 ...
- Linux操作、hadoop和sh脚本小结
近期一直在忙项目上的事情,今天对以前的工作做一个简单的小结.明天就是国庆节啦. 1 脚本可以手动执行,可是crontab缺总是找不到路径? #!/bin/bash. /etc/profile . / ...
- Hadoop 2.4.1 设置问题小结【原创】
先丢点问题小结到这里,免得忘记,有空再弄个详细教程玩,网上的教程要不就是旧版的,要不就是没说到点子上,随便搞搞也能碰上结果是对的时候,但是知其然而不知其所以然,没意思啊.解决问题的方法有很多种,总得找 ...
- 【Hadoop】HIVE 小结概览
一.HIVE概览小结 二.HIVE安装 Hive只在一个节点上安装即可 .上传tar包 .解压 tar -zxvf hive-.tar.gz -C /cloud/ .配置mysql metastore ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark+Hadoop问题小结
1.spark执行./start-all.sh报"WARN Utils: Service 'sparkWorker' could not bind on port 0. Attempting ...
- Hadoop 2.4.1 登录认证配置小结
1.简单模式 这种模式,配置简单,使用简单. core-site.xml添加 <property> <name>hadoop.security.authorization< ...
- Hadoop 2.4.1 Map/Reduce小结【原创】
看了下MapReduce的例子.再看了下Mapper和Reducer源码,理清了参数的意义,就o了. public class Mapper<KEYIN, VALUEIN, KEYOUT, VA ...
- hadoop部署小结的命令
hadoop部署总结的命令 学习笔记,转自:hadoop部署总结的命令http://www.aboutyun.com/thread-5385-1-1.html(出处: about云开发)
随机推荐
- 关于Apahce服务器安装中遇到的问题
在这篇中,将记录一下安装Apache服务器所遇到的一些问题,并简单讲一些Apache和Tomcat的区别: 1>apache安装中遇到的问题: 1.1 Apache目前不再提供编译好的exe安装 ...
- 有哪些知名的公司在用Python
谷歌:Google App Engine.code.Google.com.Google earth.谷歌爬虫.Google广告等项目都在大量使用Python开发 CIA:美国中情局网站就是用Pytho ...
- 初识Dubbo+Zookeeprt搭建SOA项目
由于工作中天天和Dubbo打交道,天天写对外服务,所以有必要自己动手搭建一个Dubbo+zookeeper项目来更更深层次的认识Dubbo 首先了解一下SOA: 英文名称(Service Orient ...
- Promise(一)
每个Promise对象就是一个值的代理,这个值在Promise创建时可以是未知的.Promise对象允许你为异步事件的成功操作和失败操作分别绑定对应的处理方法,让异步方法可以像同步方法那样返回值,但不 ...
- Rabbitmq的使用及Web监控工具使用
本文转载自:https://www.cnblogs.com/gossip/p/4475978.html windows安装手册请参考:http://www.rabbitmq.com/install-w ...
- 关于git的reset指令说明-soft、mixed、hard
在开发过程中,git的版本管理越来越普及.在版本管理中,最常用和最重要的是重置提交的版本,恢复后悔做了的事.大家都知道用reset命令.但是有几种形态需要整理共享一下,也方便我自己查阅. 一.首先解析 ...
- 玩转Kafka的生产者——分区器与多线程
上篇文章学习kafka的基本安装和基础概念,本文主要是学习kafka的常用API.其中包括生产者和消费者, 多线程生产者,多线程消费者,自定义分区等,当然还包括一些避坑指南. 首发于个人网站:链接地址 ...
- 一次艰难debug的反思
已经很久没有遇到如此顽固的bug了,总共耗费了我近1个礼拜的时间.期间的种种冲突,个人崩溃,最终解决方案的形成,到回过头来的反思,实在有太多值得梳理的东西. 从结果上来讲,这是个人js基础极端薄弱的集 ...
- 纯小白创建第一个Node程序失败-容易忽略的一个细节
一直觉得自己基础还很差,所以自觉不敢去碰node.js,但又对其心怀好奇.恰巧最近有一点空闲时间,忍不住去试了一下水 这不,在创建第一个node程序时就吃了闭门羹,总是提示我没有定义,如下图, 这 ...
- feign包名路径添加问题
1. feign包名路径添加问题 1.1. 问题 在SpringCloud中使用feign调用路径中,不能在类上直接添加@RequestMapping(value = "/hospital- ...