ETL hive update 之 deltamerge 优化
- full join 横向join ,不能map join 走shuffle
- row_number() over ( partition by 主键 order by $flag desc) rank ... where rank =1 ,走shufle
select
id,
order_datekey,
f_procurement_order,
from
(
select
id,
order_datekey,
f_procurement_order,
row_number() over (
partition by id
order by
b_flag_i desc
) rank
from
(
select
id,
order_datekey,
f_procurement_order,
0 b_flag_i
from
ods_pms_procurement_order_item_hm old
WHERE
c_t >= 1479916800
or u_t >= 1479916800
union all
select
id,
order_datekey,
f_procurement_order,
1 b_flag_i
from
ods_pms_procurement_order_item_hm_delta_64124FEADBFA9720 new
) t
) st
where
rank = 1;
- 差集 + 并集方式 效率最高 前提是增量数据较少,要不也要走shuffle
# semi_1 数据 id , name
1 jx
2 gj
# semi_2数据id, age
1 28
3 30
select a.id,a.name from semi_1 a left anti join semi_2 b on a.id = b.id;
left anti join 是以左表为主,如果join上就返回null,否则返回左表数据。
2 gj
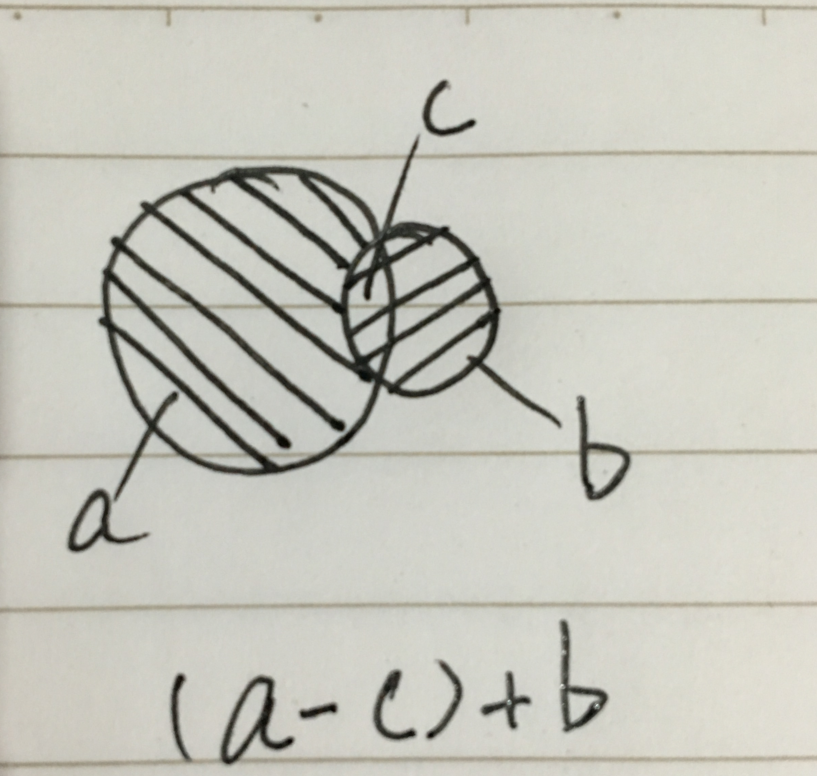
下图a代表完整old 全集,b代表完整new全集,c代表a与b join 上的交集部分(比如id相等的部分)所以思路就是(a-c)+b实现hive 的update
SET hive.mapred.mode=nonstrict;
INSERT overwrite TABLE $target.table
SELECT
$stream.format
FROM
$target.table old left anti
join ($delta) new on $stream.unique_keys
UNION ALL
SELECT
$stream.format
FROM
$target.table ;
fields = 'id,name'
new = 'new'
old = 'old'
and_str = ' AND '
cmd = []
for field in fields.split(','):
str = old + '.' + field + ' = ' + new + '.' + field
cmd.append(str)
print and_str.join(cmd)
ETL hive update 之 deltamerge 优化的更多相关文章
- 写好Hive 程序的若干优化技巧和实际案例
使用Hive可以高效而又快速地编写复杂的MapReduce查询逻辑.但是一个”好”的Hive程序需要对Hive运行机制有深入的了解,像理解mapreduce作业一样理解Hive QL才能写出正确.高效 ...
- Hive性能分析和优化方法
Hive性能分析和优化方法 http://wenku.baidu.com/link?url=LVrnj-mD0OB69-eUH-0b2LGzc2SN76hjLVsGfCdYjV8ogyyN-BSja5 ...
- Hive使用Calcite CBO优化流程及SQL优化实战
目录 Hive SQL执行流程 Hive debug简单介绍 Hive SQL执行流程 Hive 使用Calcite优化 Hive Calcite优化流程 Hive Calcite使用细则 Hive向 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hive查询注意及优化tips
Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具.使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别, 所以需要去掉原有关系型数 ...
- HIVE的几种优化
5 WAYS TO MAKE YOUR HIVE QUERIES RUN FASTER 今天看了一篇[文章] (http://zh.hortonworks.com/blog/5-ways-make-h ...
- hive 总结四(优化)
本文参考:黑泽君相关博客 本文是我总结日常工作中遇到的坑,结合黑泽君相关博客,选取.补充了部分内容. 表的优化 小表join大表.大表join小表 将key相对分散,并且数据量小的表放在join的左边 ...
- hive中笛卡尔积的优化
由于一个业务,必须要进行笛卡尔积,但是速度太慢了,left join时左表大概4万条数据,右表大概 3000多条数据,这样大概就是一亿多条数据, 这在大数据领域其实不算很大的数据量,但是hive中跑的 ...
- Hive参数层面常用优化
1.hive数据仓库权限问题: set hive.warehouse.subdir.inherit.perms=true; 2.HiveServer2的内存 连接的个数越多压力越大,可以加大内存:可以 ...
随机推荐
- .net core+Spring Cloud学习之路 一
文章开头唠叨两句. 2019年了,而自己参加工作也两年有余了,用一个词来概括这两年多的生活,就是:“碌碌无为”. 也不能说一点收获都没有,但是很少.2019来了,我立志要打破现状,改变自己,突破自我. ...
- Xunit和Nunit的区别
https://www.cnblogs.com/Leo_wl/p/5727712.html 舍弃Nunit拥抱Xunit 前言 今天与同事在讨论.Net下测试框架的时候,说到NUnit等大多数测试 ...
- Python error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall.bat)解决方案
error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall.bat). Get it - 解决方案 python通过pi ...
- dispatherServlet拦截所有请求,但是不拦截JSP和其他配置的servelt
不是顺序问题,是就不拦截Servlet 不是load-on-startup启动先后顺序问题,是就是不拦截Servlet. SpringMVC默认用的是第二个 //<url-pattern> ...
- cmake add_custom_command 使用
cmake add_custom_command 使用 今天整理编译工程,想在编译工程前面用tolua生成c文件, 使用命令add_custom_command后,附加的命令并不执行,如下: add_ ...
- 使用命令查看 Laravel 的版本
进入项目根目录文件夹后,进入命令行,输入命令: php artisan --version 或者输入: php artisan 会出现 artisan 的帮助文档,最上面就是 laravel 的版本号
- Freescale MKL16Z1288VF4 芯片调试接口
WDOG监视内部系统操作,并在发生故障时强制复位.它可以运行在一个独立的1 kHz低功率振荡器,具有可编程刷新窗口,以检测程序流或系统频率的偏差. 看门狗计时器保持一个时间在系统上运行,并重置它,以防 ...
- 指定的经纬度是否落在多边形内 java版
这个想法算法就是判断一个点向左的射线跟一个多边形的交叉点有几个,如果结果为奇数的话那么说明这个点落在多边形中,反之则不在. A: B: C: D: E: no1: no2: y1: y2: 以上的AB ...
- DockerToolbox在Win7上的安装和设置
为什么使用Docker Toolbox Docker在Windows上使用有两种方式,一是利用VirtualBox建立linux虚拟机,在linux虚拟机中安装docker服务端和客户端,二是利用Wi ...
- 浏览器F12(开发者调试工具) 功能介绍
调试时使用最多的功能页面是:元素(ELements).控制台(Console).源代码(Sources).网络(Network)等. 元素(Elements):用于查看或修改HTML元素的属性.CSS ...