分布式中的 transaction log
分布式中的 transaction log
在分布式系统中,有很多台node组成一个cluster,对于client 的一个写操作请求而言,在什么样的情况下,cluster告诉client此次写操作请求是成功的呢?
首先来定义一下什么是写操作成功?
假设有一个三节点的cluster,一个primary node,两个replica node如下图所示:
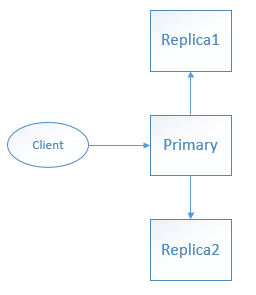
- 方案1. client 向primary发写请求,primary 将待写的数据持久化后,返回响应给client此次写操作成功,然后primary再将数据复制给其他两台replica node。
- 方案2. client 向primary发写请求,primary 将待写的数据 复制 到其他两台 replica node,等待 replic node将数据持久化后给primary响应,然后primary再返回响应给client此次写操作成功。
方案1,client有着良好的响应性,因为只需要primary持久化了,就给client响应;并发性更高,因为对于cluster而言,只需要primary持久化了,cluster 就算“暂时”成功处理了一个请求。
但是对于client而言,读操作就不方便了。因为,client要想读到最新的数据,读primary node是没问题的,但是读 replic node就有可能读不到最新的数据,因为:primary 还未来得及将最新的数据 复制到 replica 时,client向replica 发起了读数据请求,如下图所示:
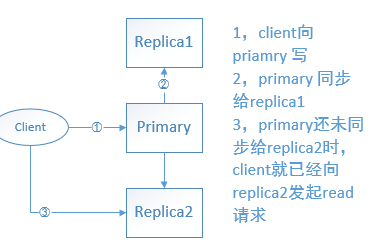
这样,client就读不到它刚才明明已经写入成功的数据了。
方案2,client 读取任何一台node都能读取到最新写入的数据,但是client的响应性不佳。
上面的讨论是从client角度、cluster角度来讨论的,还可以从数据的角度来讨论,就是数据是否被丢失。
一个cluster,一般是要接收大量的client的写请求的,如果来一个写请求,cluster就执行一次磁盘写操作(将数据持久化)那么性能应该是不佳的。因此,可以先将若干个写请求的数据都放到一个buffer中,然后等一段时间再批量将这些数据刷新到磁盘(sync)。
当引入了buffer,将写操作数据批量写磁盘 这种机制时,什么时候给client返回写操作成功的响应呢?是等若干个写操作数据批量同步到磁盘后,再给client返回写请求成功的响应、还是数据只是存储到所谓的buffer里面,就给client返回写操作成功的响应?而buffer的引入,又对 primary node 将数据 复制到 replica node 产生何种影响?
另外,就算真的不引入所谓的buffer,如果client的写操作很复杂、代价很大,难不成真的是要等数据持久化到磁盘才能给client响应成功吗?这种方式是不是有点与“并发控制 锁操作中的”悲观锁……
这个真的就不好说了,可能不同的产品有不同的实现细节吧。比如ElasticSearch、Mongodb
而当引入了buffer之后,由于将client的写操作数据都批量缓存起来了,那万一机器挂了,那这些缓存的数据就全丢失了,而如果client发一个请求,就同步一次磁盘,那处理性能又受到了影响,这似乎是一个两难的问题。
因此,为了解决这个问题,引入了一个叫“replication log”的概念。relication log有多种不同的实现方式,比如 write ahead log(WAL),而在ElasticSearch里面也有一个类似的东西,叫做transaction log(不知道我理解的对不对)
replication log的思想就是:针对client的写操作,生成一条日志,该日志详细记录了写操作对数据进行何种操作。一般日志只支持append操作的,一般地,相比于写数据操作、写日志要轻量级得多。另外日志还有个好处是:如果node在写操作过程中失败了,比如数据写到一半失败了,那及有可能造成数据的不一致性,那它还可以再读取日志,从日志中恢复出来。
下面来举个具体的例子,个人理解。
client 向 elasticsearch cluster 发起 index 操作。文档要分词,到Lucene底层要构造segment,生成 倒排索引(posting list)这种数据结构。这是一种“费时费力、代价很大的操作”,因此,不可能 针对 一篇文档一个index请求,就flush 一次segment。因此可以每隔一段时间、批量flush segment。而如果批量flush 的话,如果机器宕机了,那就会丢失很多数据。因此,es 引入了translog:
all the index/delete/update operations are written to the translog and the translog is fsynced after every index/delete/update operations to make sure the changes are persistent. the client receives acknowledgement for writes after the translog is fsynced on both primary and replic shards
写translog 应该要比 lucene segment flush 操作要轻量级得多。另外,primary shards 只需要将translog持久化、并同步给replica 后,就可以给client返回 写操作成功的响应了,这样可支持写操作的高并发。
总结
本文从三个角度:client、cluster、数据是否丢失 阐述了分布式中的读写一致性及数据可靠性。
- 节点之间的数据复制方式(同步复制、异步复制)是宏观上(针对的是各个node)的一种影响数据可靠性的因素
- replication log(transaction log)是一种微观上(针对的是具体的写操作)影响数据可靠性的因素
个人理解,可能有错。
原文:https://www.cnblogs.com/hapjin/p/9655879.html
分布式中的 transaction log的更多相关文章
- The transaction log for database 'xxxx' is full due to 'ACTIVE_TRANSACTION'
今天查看Job的History,发现Job 运行失败,错误信息是:“The transaction log for database 'xxxx' is full due to 'ACTIVE_TRA ...
- SQL Server Transaction Log Truncate && Shrink
目录 什么是事务日志 事务日志的组成 事务日志大小维护方法 Truncate Shrink 索引碎片 总结 什么是事务日志 Transaction log 是对数据库管理系统执行的一系列动作的记录 ...
- 通过Transaction Log(fn_dblog)取回被删除的数据
最近跟 James 讨论为何「ApexSQL Log」这个工具可以读到被删除的数据呢? 原来它是透过 Transaction Log 来读取数据的! 于是透过 Transaction Log 到网络上 ...
- MySQL中的redo log和undo log
MySQL中的redo log和undo log MySQL日志系统中最重要的日志为重做日志redo log和归档日志bin log,后者为MySQL Server层的日志,前者为InnoDB存储引擎 ...
- The transaction log for database 'tempdb' is full due to 'ACTIVE_TRANSACTION'
今天早上,Dev跟我说,执行query statement时出现一个error,detail info是: “The transaction log for database 'tempdb' is ...
- 在Salesforce中通过 Debug Log 方式 跟踪逻辑流程
在Salesforce中通过 Debug Log方式 跟踪逻辑流程 具体位置如下所示: Setup ---> Logs ---> Debug Logs ---> Monitored ...
- javascript 中的console.log和弹出窗口alert
主要是方便你调式javascript用的.你可以看到你在页面中输出的内容. 相比alert他的优点是: 他能看到结构话的东西,如果是alert,淡出一个对象就是[object object],但是co ...
- mysql中slow query log慢日志查询分析
在mysql中slow query log是一个非常重要的功能,我们可以开启mysql的slow query log功能,这样就可以分析每条sql执行的状态与性能从而进行优化了. 一.慢查询日志 配置 ...
- DB2 “The transaction log for the database is full” 存在的问题及解决方案
DB2在执行一个大的insert/update操作的时候报"The transaction log for the database is full.. "错误,查了一下文档是DB ...
随机推荐
- 前端之Android入门(3):MVC模式(上)
很多Android的入门书籍,在前面介绍完布局后就会逐个介绍组件,然后开始编写组件使用的例子.每每到此时小伙伴们都可能会有些疑问:是否应该先啃完一本<Java编程思想>学点 Java 知识 ...
- 【BZOJ5469】[FJOI2018]领导集团问题(动态规划,线段树合并)
[BZOJ5469][FJOI2018]领导集团问题(动态规划,线段树合并) 题面 BZOJ 洛谷 题解 题目就是让你在树上找一个最大的点集,使得两个点如果存在祖先关系,那么就要满足祖先的权值要小于等 ...
- 【CF1097E】Egor and an RPG game(动态规划,贪心)
[CF1097E]Egor and an RPG game(动态规划,贪心) 题面 洛谷 CodeForces 给定一个长度为\(n\)的排列\(a\),定义\(f(n)\)为将一个任意一个长度为\( ...
- Bug预防体系(上千bug分析后总结的最佳实践)
Bug预防体系(上千bug分析后总结的最佳实践) 原创 2017-08-16俞美玲 光荣之路 吴老的<selenium webdriver 实战宝典>出版了! web常见产品问题及预防 ...
- bzoj4337树的同构
树是一种很常见的数据结构. 我们把N个点,N-1条边的连通无向图称为树. 若将某个点作为根,从根开始遍历,则其它的点都有一个前驱,这个树就成为有根树. 对于两个树T1和T2,如果能够把树T1的所有点重 ...
- MongoDB查询内嵌数组(限定返回符合条件的数组中的数据)(1)
https://blog.csdn.net/bicheng4769/article/details/79579830 项目背景 最近在项目中使用mongdb来保存压测结果中的监控数据,那么在获取监控数 ...
- navicat premium 12破解流程
具体步骤:这是破解的具体链接 仅此记录,以供后续之需
- Luogu P4097 [HEOI2013]Segment 李超线段树
题目链接 \(Click\) \(Here\) 李超线段树的模板.但是因为我实在太\(Naive\)了,想象不到实现方法. 看代码就能懂的东西,放在这里用于复习. #include <bits/ ...
- (链表) leetcode 21. Merge Two Sorted Lists
Merge two sorted linked lists and return it as a new list. The new list should be made by splicing t ...
- Vue(基础七)_webpack使用工具(下)
一.前言 1.webpack.config文件配置 2.webpack打包css文件 ...