Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization(第一周)深度学习的实践层面 (Practical aspects of Deep Learning)
1. Setting up your Machine Learning Application
1.1 训练,验证,测试集(Train / Dev / Test sets)

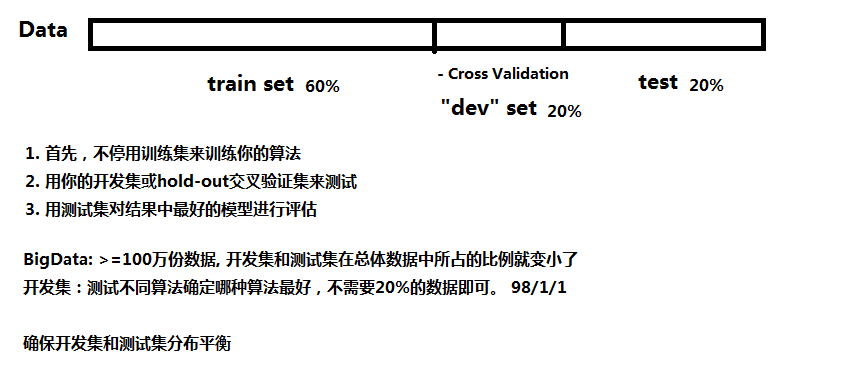
1.2 Bias/Variance(偏差和方差)
- 高偏差(high bias)称为"欠拟合"(underfitting), 练集误差与验证集误差都高.
- 高方差(high variance)称为过拟合(overfitting), 训练集误差很低而验证集误差很高.
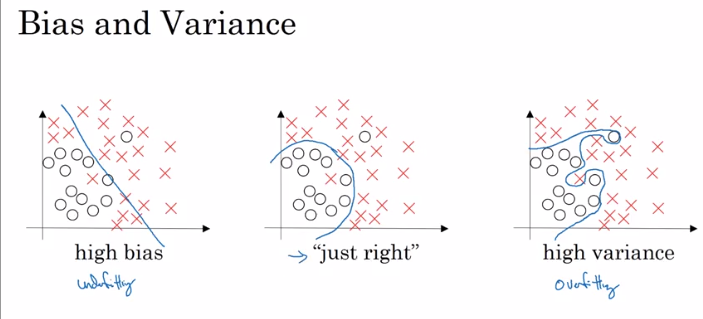

1.3 Basic "recipe" for Machine learning
1.31 High bias(高偏差)
- 更大的神经网络
1.32 High Variance(高方差)
- 更多数据
- 正则化
- CNN
2. Regularizing your neural network(发生过拟合—高方差)
2.1 L2正则化(权重衰减)




正则项说明,无论$w^[l]$是什么,我们都试图使之更小(趋于0)。则计算得的 $z[l]=w[l]a[l−1]+b[l]$ 更容易(以tanh例)落在激活函数 $g(z[l])$ 中间那一段接近线性的部分, 以达到简化网络的目的(线性的激活函数使得无论多少层的网络, 效果都和一层一样)。
注意:J(..)代价函数,需要加上 $\frac{\lambda}{m}w^{[l]}$
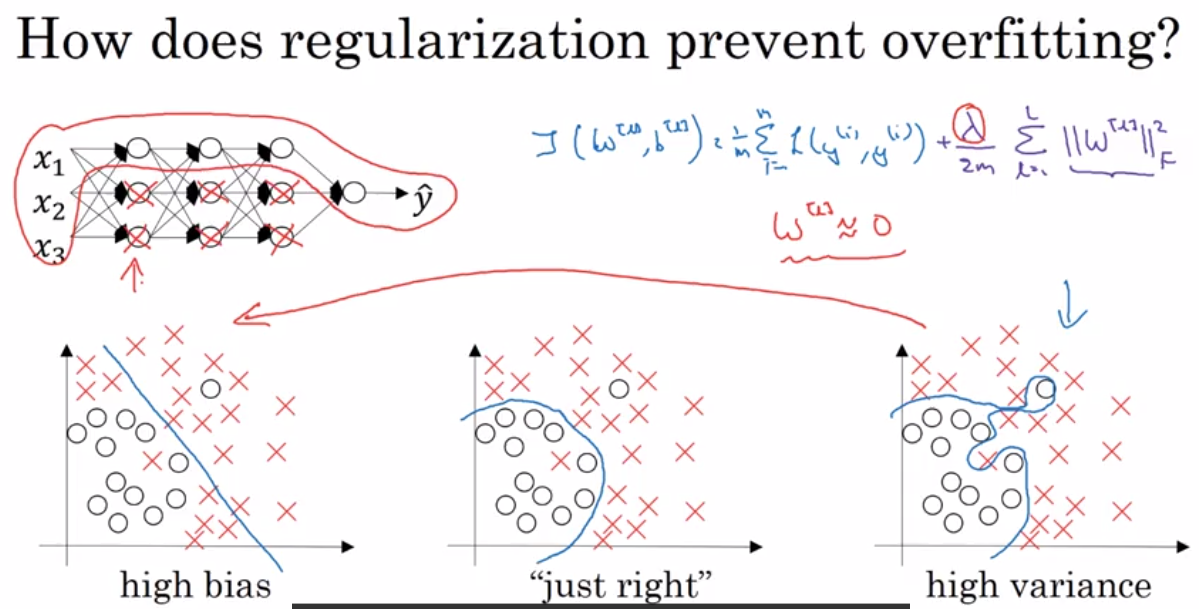
2.2 随机失活(Dropout)正则化
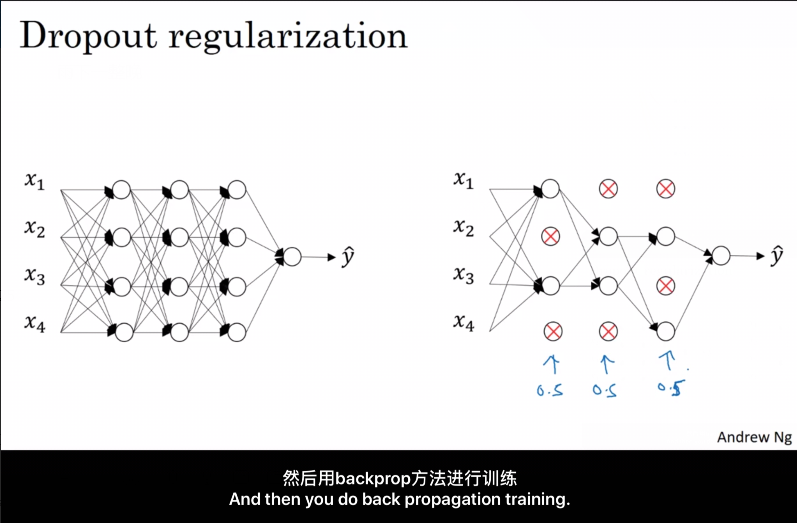
对每一轮的训练, Dropout 遍历网络的每一层, 设置神经网络中每一层每个节点的失活概率, 不参与本轮的训练, 于是得到一个更小的网络.
最常用的为 反向随机失活(Inverted Dropout).

该方法在向前传播时, 根据 随机失活的概率 (例如0.2), 将每一层(例如 $l$层)的 $a^{[l]}$ 矩阵($a=g(z)$)中被选中失活的元素置为0,则该层的 $a^{[l]}$ 相当于少了 20% 的元素. 为了不影响下一层 $ z^{[l+1]} $ 的期望值, 我们需要 $a^{[l]}$ /= 0.8 以修正权重.
由于训练时的 "$a^{[l]}$ /= 0.8" 修复了权重, 在测试阶段无需使用 Dropout。
注:Dropout 不能与梯度检验同时使用, 因为 Dropout 在梯度下降上的代价函数J难以计算.
3. 归一化(Normalizing)
训练神经网络,其中一个加速训练的方法就是归一化输入。假设一个训练集有两个特征,
输入特征为 2 维,归一化需要两个步骤:(一些特征0~1,一些0~1000)
零均值化:
μ $ =\frac{1}{m}\sum^m_{i=1}x^{(i)} $;
$ x:=x-μ $

归一化方差:
ρ $ ^2=\frac{1}{m}\sum^m_{i=1}x^{(i)}**2 $
x /= ρ^2
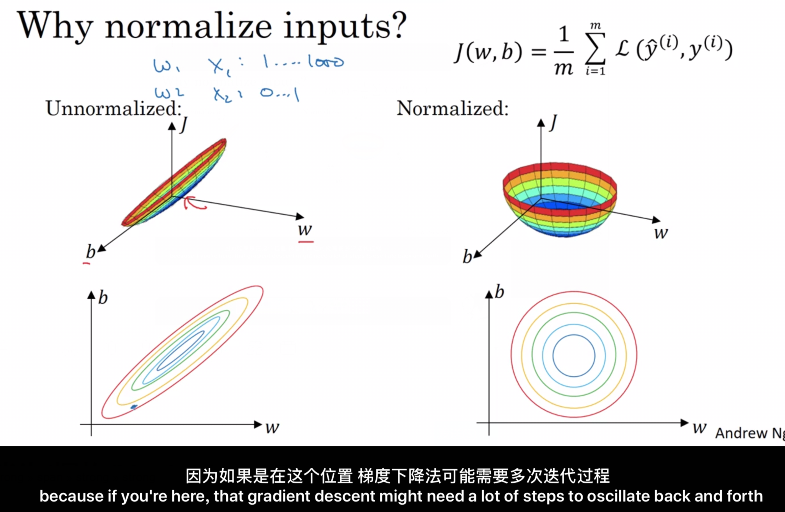
归一化直观的理解就是使得代价函数更圆, 更容易优化代价函数.
4. 梯度消失/爆炸(Vanishing / Exploding Gradients
为了方便理解,假设使用了线性激活函数 g(z)=z , 且:
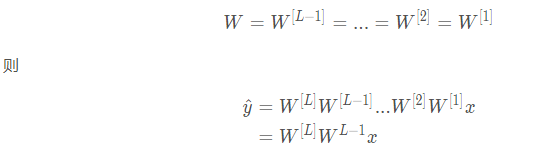
可知若 $W$ 中有元素权重为 1.5 , 则最终得到 $1.5^{L-1}$ , 若层数很深, 计算得 $yˆ \hat{y}$ 也很大; 同理,若权重为 0.5 , 进行 $L−1$次幂运算后值会很小. 这便是梯度爆炸与梯度消失.
有效的解决方案:由于 $z=w1x1+w2x2+...+wnxn$ (忽略 b), 为了预防 $z$太大或太小, 则$n$ 越大时, 期望 $w_i$ 越小, 则在随机(0~1)初始化$W$ 时, 我们对其乘上一个小于1的倍数, 使之更小。
对于Tanh, 权重乘上 $\sqrt{\frac{1}{n^{[l-1]}}} $, 或者 $ \sqrt{\frac{2}{n^{[l-1]}+n^{[l]}}}$
对于Relu, 权重乘上 $\sqrt{\frac{2}{n^{[l-1]}}} $
5. 梯度检验
在反向传播的时候, 如果怕自己 $d\theta[i] = \frac{\partial J}{\partial \theta_i}$ 等算错, 可以用导数的定义, 计算:
$d\theta_{approx}[i] = \frac{J(\theta_1, \theta_2,..., \theta_i + \varepsilon, ...) - J(\theta_1, \theta_2, ..., \theta_i - \varepsilon, ...)}{2\varepsilon}$
然后根据两者误差估计自己是否算错. 该方法仅用来调试, 且不能同 Dropout 同时使用.
Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization(第一周)深度学习的实践层面 (Practical aspects of Deep Learning)的更多相关文章
- 吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记
第一周:深度学习的实践层面 (Practical aspects of Deep Learning) 1.1 训练,验证,测试集(Train / Dev / Test sets) 创建新应用的过程中, ...
- 《Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization》课堂笔记
Lesson 2 Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization 这篇文章其 ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Initialization)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Initialization Welcome to the first assignment of "Improving D ...
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Assignment(Optimization Methods)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. 请不要ctrl+c/ctrl+v作业. Optimization Methods Until now, you've always u ...
- Coursera, Deep Learning 2, Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Course
Train/Dev/Test set Bias/Variance Regularization 有下面一些regularization的方法. L2 regularation drop out da ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第三周(Hyperparameter tuning, Batch Normalization and Programming Frameworks) —— 2.Programming assignments
Tensorflow Welcome to the Tensorflow Tutorial! In this notebook you will learn all the basics of Ten ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Gradient Checking)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Gradient Checking Welcome to the final assignment for this week! In ...
随机推荐
- 【cf849ABC】
849A - Odds and Ends 问能否将序列划分为奇数个长度奇数的奇数开头奇数结尾的子区间. 一开始想dp..不过没必要. const int N=201000; int n,a[N]; i ...
- CF280C Game on Tree
题目链接 : CF280C Game on Tree 题意 : 给定一棵n个节点的树T 根为一(我咕的翻译漏掉了...) 每次随机选择一个未被删除的点 并将它的子树删除 求删整棵树的期望步数 n ∈ ...
- web 压力测试工具
最近有收到任务,测试新服务器的性能. 花了很长时间做搜索,也整理了一些资料.以下是收集到一些简单易用的分析工具.推荐给大家使用. WebBenchhttp://www.ha97.com/4623.ht ...
- Java简单工厂模式(SimpleFactoryMode)
何为简单工厂模式? 由一个工厂类根据传入的参数,动态创建并返回相应的具体的实例! 三个构成元素: 1.工厂类 2.抽象产品 3.具体产品 优点: 1.提高扩展性 2.隐藏具体的实现类,并不需要知道产品 ...
- 【BZOJ1831】[AHOI2008]逆序对(动态规划)
[BZOJ1831][AHOI2008]逆序对(动态规划) 题面 BZOJ 洛谷 题解 显然填入的数拎出来是不降的. 那么就可以直接大力\(dp\). 设\(f[i][j]\)表示当前填到了\(i\) ...
- 【CF526G】Spiders Evil Plan(贪心)
[CF526G]Spiders Evil Plan(贪心) 题面 洛谷 CodeForces 给定一棵树,要求选择\(y\)条链,满足被链覆盖的所有点在树上联通,且\(x\)必定在联通块中. 对于每次 ...
- 「SCOI2014」方伯伯的 OJ 解题报告
「SCOI2014」方伯伯的 OJ 和列队有点像,平衡树点分裂维护即可 但是需要额外用个set之类的对编号查找点的位置 插入完了后记得splay,删除时注意特判好多东西 Code: #include ...
- [NOI2016]优秀的拆分&&BZOJ2119股市的预测
[NOI2016]优秀的拆分 https://www.lydsy.com/JudgeOnline/problem.php?id=4650 题解 如果我们能够统计出一个数组a,一个数组b,a[i]表示以 ...
- ACM-ICPC 2018 南京赛区网络预赛 G Lpl and Energy-saving Lamps(线段树)
题目链接:https://nanti.jisuanke.com/t/30996 中文题目: 在喝茶的过程中,公主,除其他外,问为什么这样一个善良可爱的龙在城堡里被监禁Lpl?龙神秘地笑了笑,回答说这是 ...
- 2.Linux基础命令
linux内一切皆文件,没有文件夹只有目录,目录也是一种文件 1.一些常用按键: 将鼠标的光标从虚拟机里切换回来:Ctrl+Alt 拖动Ubuntu内的对话框:Alt键+鼠标左键拖动 清屏:Ctrl+ ...