《Kafka权威指南》读书笔记-操作系统调优篇
《Kafka权威指南》读书笔记-操作系统调优篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
大部分Linux发行版默认的内核调优参数配置已经能够满足大多数应用程序的运行需求,不过还是可以通过调整一些参数来进一步提升Kafka的性能。这些参数主要与虚拟内存,网络子系统和用来存储日志片段的磁盘挂在点有关。这些参数一般配置在“/etc/sysctl.conf” 文件里,不过在对内核参数进行调整时,最好参考官方提供的操作系统文档。
一.虚拟内存
一般来说,Linux的虚拟内存会根据系统的工作负荷进行自动调整。我们可以对交换分区的处理方式和内存脏页进行调整,从而让Kafka更好的处理工作负载。对于大多数依赖吞吐量的应用程序来说,要尽量避免内存交换。内存页和磁盘之间的交换对Kafka各方面的性能都有重大影响。kafka大量地使用系统页面缓存,如果虚拟内存被交换到磁盘,说明已经没有多余的内存可以分配该页面缓存啦。
1>.把vm.swappiness的值设置的更小一点(默认值是60,推荐设置为小于10的数字,比如1。)
一种避免内存交换的方法是不设置任何交换分区。内存交换不是必须的 ,不过它确实能够在操作系统发生灾难性错误时提供一些帮助。进行内存交换可以防止操作系统由于内存不足而突然终止进程。基于上述原因,建议把vm.swappiness的值设置的更小一点,比如1.该参数指明了操作系统将如何使用交换分区,而不是把内存页从页面缓存里移除。要优先考虑减少页面缓存,而不是进行内存交换。详细操作步骤可参考我的笔记(链接在下文中可以看到)。
2>.为什么不把vm.swappiness设置为零
先前,人们建议把vm.swapiness设置为0,它意味着“除非发生内存益处,否则不要进行内存交换”。直到Linux内核3.5-rcl版本发布,这个值的意义才发生了变化。这个变化被一直到其他的发行版本上,包括RedHat企业版内核2.6.32-303。在发生变化之后,0意味着“在任何情况下都不要发生交换”。所以现在建议把这个值设置为1。
3>.Linux虚拟内存(swap)调优篇-“swappiness”,“vm.dirty_background_ratio”和“vm.dirty_ratio”
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9994207.html
二.磁盘与文件系统
除了选择合适的磁盘硬件设备和使用RAID外,文件系统是性能影响的另一个重要因素。有很多中文件系统可供选择,不过对于本地文件系统来说,EXT4(第四代可扩展文件系统)和XFS最为常见。近来,XFS称为很多Linux发行版默认的文件系统,因为它只需要做少量的调优即就可以承担大部分的工作负荷,比EXT4具有更好的表现。EXT4也可以做得很好,但需要做更多的调优,存在较大的风险。其中包括设置设置更长的时间间隔(默认是5)一边降低刷新的频率。EXT4还引入了块分配延迟,一旦系统崩溃,更容易造成数据的丢失和文件系统损坏。XFS也使用分配延迟算法,不过比EXT4的要安全些。
XFS为Kafka提供了更好的性能,除了有文件系统提供的自动优化之外,无需额外的调优。批量写入具有更高的效率,可以提升整体的I/O吞吐量。换句话说,这种性能的提升主要影响的是Kafka的写入能力。根据官网的测试报告,使用XFS的写入时间大约是160ms,而使用Ext4大约是250ms。因此生产环境中最好使用XFS文件系统。
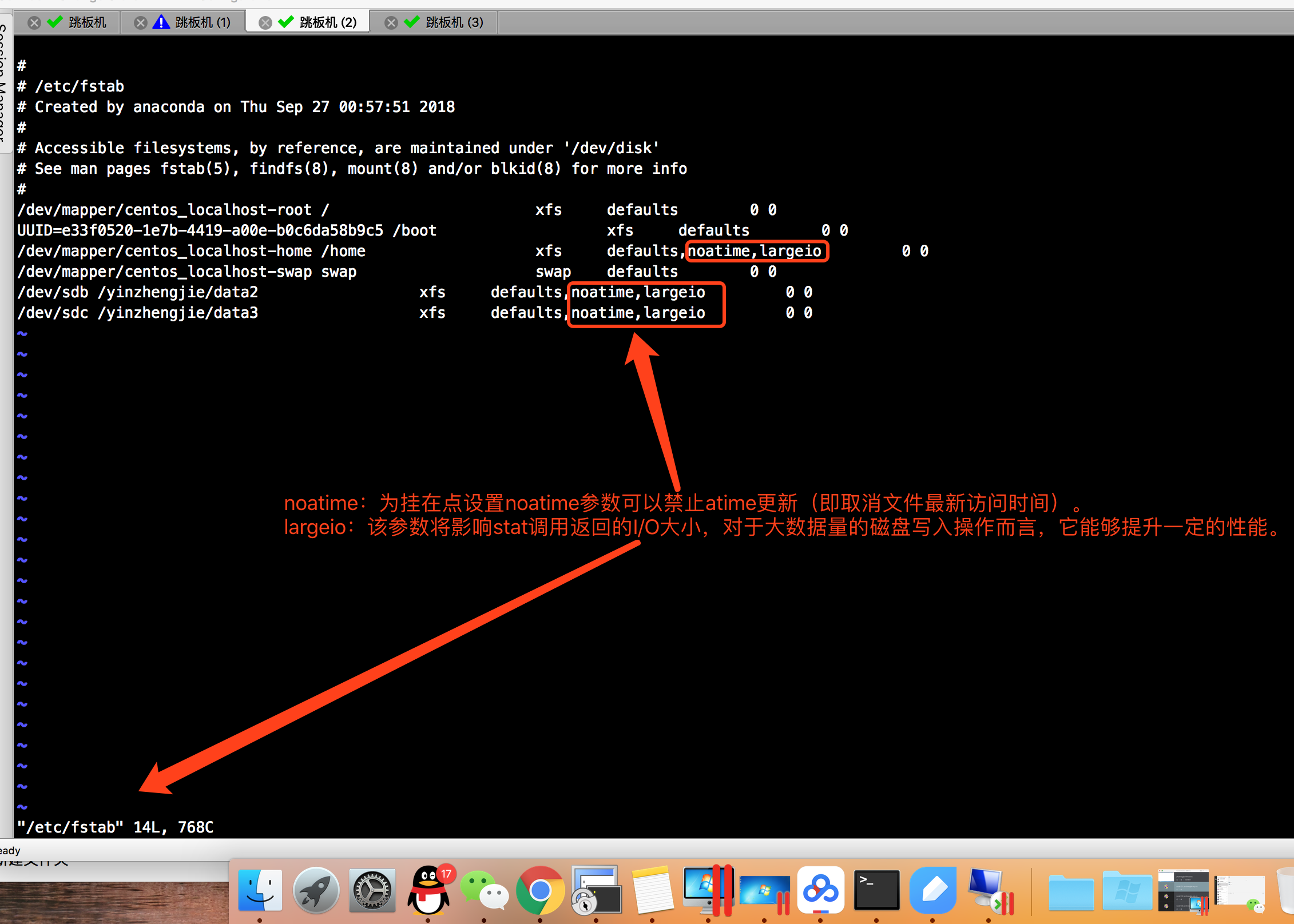
不管使用哪一种文件系统来存储日志片段,最好要对挂在点的noatime参数进行合理的设置。文件元数据包括三个时间戳:创建时间(ctime),最后修改时间(mtime)以及最后访问时间(atime)。默认情况下,每次文件被读取后,都会更新atime,这会导致大量的磁盘读写操作,而且atime属性用处不大,除非某些应用程序想要某个文件在最后一次修改后有没有访问过(这种情况可以使用retime)。Kafka用不到该属性,所以完全可以把它禁用掉。为挂载点设置noatime参数可以防止更新atime,但不会影响ctime和mtime。
对于XFS用户而言,推荐设置largeio参数,该参数将影响stat调用返回的I/O大小。对于大数据量的磁盘写入操作而言,它能够提升一定的性能。largeio是标准的mount属性,故可使用与nobh相同的方式设置。
我们只需要修改“/etc/fstab”这个开机启动时会加载的文件即可,它主要时记录操作系统开机自动挂载的事情,我们可以通过“df -h”查看磁盘挂载的情况。我们需要修改的地方我已经标识出来啦:
三.网络
这里指的的是OS级别的Socket缓冲区大小,而非Kafka自己提供的Socket缓冲区参数。事实上,Kafka自己的参数将其设置为64KB,这对于普通的内网环境而言是足够的,因为内网环境下往返时间(round-trip time,RRT)一般都很低,不会产生过多的数据堆积在Socket缓冲区中,但对于那些跨地区的数据传输而言,仅仅增加Kafka参数就不够了,因为前者也受限于OS级别的设置。因此如果是做远距离的数据传输,那么建议将OS级别的Socket缓冲区调大,比如增加到128KB,甚至更大。
还有就是关掉没有用不到的网络服务,比如IPV6等,具体实操请参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/9995756.html。
四.文件描述符限制优化
Kafka会频繁地创建并修改文件系统中的文件,这包括消息的日志文件,索引文件以及各种元数据管理文件等。我们可以使用ulimit进行资源管控,设置文件打开数据和用户打开进程数等等,我们也可以编辑配置文件(/etc/security/limits.conf)并添加以下内容:(添加后推出当前终端,下一次登陆服务器时就会生效!)
[root@yinzhengjie ~]# cat /etc/security/limits.conf | grep -v ^# | grep -v ^$
* soft nofile
* hard nofile
* soft nproc
* hard nproc unlimited
* soft memlock unlimited
* hard memlock unlimited
[root@yinzhengjie ~]#
除了上面的参数,我们还可以适当调大用户打开的进程数:
[root@yinzhengjie ~]# cat /etc/security/limits.d/-nproc.conf | grep -v ^# | grep -v ^$
* soft nproc
root soft nproc unlimited
[root@yinzhengjie ~]#
五.JVM参数优化
鉴于Kafka broker主要使用的时堆外内存,即大量使用操作系统的页缓存,因此并不需要为JVM分配太多的内存。在实际使用中,通常broker设置不超过6GB的堆空间,咱们关于kafka的JVM调优对象主要针对2个配置文件,即:“kafka-run-class.sh”和“kafka-server-start.sh”两个脚本(这两个脚本都在Apache kafka安装包解压后的bin目录下)。
1>."kafka-run-class.sh"
找到“# JMX settings” 这一行,我们可以自定义JMX的端口,举个案例如下:
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=12345 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
fi
找到“# Generic jvm settings you want to add”这一行,你可以自行添加JVM的参数列表,举个案例如下:(注意,这个脚本会被kafka-server-start.sh脚本调用,因此这里配置了就最好不要在其他位置配置哟!)
# Generic jvm settings you want to add
if [ -z "$KAFKA_OPTS" ]; then
KAFKA_OPTS="-Xmx6g -Xms6g -XX:MetaspaceSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50
-XX:MaxMetaspaceFreeRatio="
fi
2>."kafka-server-start.sh"
我们可以找到“export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G”这一行参数,它定义了kafka启动的堆内存大小,一般推荐不要超过6G,因为Kafka并不是很吃内存,它主要吃的的是离堆内存。因此我们需要把更多的内存留给OS。而kafka在写数据时,数据并不是真正写入磁盘,而是写到页缓存中,而这些页缓存就是OS的内存空间,最终数据由操作系统负责写入磁盘。Kafka并不负责底层直接和内存进行交互。
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx5G -Xms5G"
fi
温馨提示,我们这里制定了Kafka的heap内存为5G,如果你在"kafka-run-class.sh"脚本中指定了Kafka的参数时,你会发现这个脚本的配置并不会生效,原因是我们在使用"kafka-server-start.sh"时会调用“kafka-run-class.sh”这个脚本,即Kafka的变量被覆盖啦!因此我们在启动时发现kafka的heap内存为6G。
《Kafka权威指南》读书笔记-操作系统调优篇的更多相关文章
- cassandra权威指南读书笔记--性能调优
cassandra自带测试工具cassandra-stress.nodetool proxyhistograms可以在多个节点运行,发现最慢的协调节点.nodetool tablehistograms ...
- Kafka权威指南 读书笔记之(五)深入Kafka
集中讨论以下3 个有意思的话题 :• Kafka 如何进行复制:• Kafka 如何处理来自生产者和消费者的请求 :• Kafka 的存储细节,比如文件格式和索引. 集群成员关系 Kafka 使用 Z ...
- Kafka权威指南 读书笔记之(三)Kafka 生产者一一向 Kafka 写入数据
不管是把 Kafka 作为消息队列.消息总线还是数据存储平台来使用 ,总是需要有一个可以往 Kafka 写入数据的生产者和一个从 Kafka 读取数据的消费者,或者一个兼具两种角色的应用程序. 开发者 ...
- Kafka权威指南 读书笔记之(四)Kafka 消费者一一从 Kafka读取数据
KafkaConsumer概念 消费者和消费者群组 Kafka 消费者从属于消费者群组.一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息. 往群组里增加消费者是横向伸缩消费能力 ...
- Kafka权威指南 读书笔记之(一)初识Kafka
发布与订阅消息系统 数据(消息)的发送者(发布者)不会直接把消息发送给接收者,这是发布与订阅消息系统的一个特点.发布者以某种方式对消息进行分类,接收者(订阅者)订阅它们, 以便接收特定类型的消息.发布 ...
- Java性能优化权威指南-读书笔记(二)-JVM性能调优-概述
概述:JVM性能调优没有一个非常固定的设置,比如堆大小设置多少,老年代设置多少.而是要根据实际的应用程序的系统需求,实际的活跃内存等确定.正文: JVM调优工作流程 整个调优过程是不断重复的一个迭代, ...
- Java性能优化权威指南-读书笔记(五)-JVM性能调优-吞吐量
吞吐量是指,应用程序的TPS: 每秒多少次事务,QPS: 每秒多少次查询等性能指标. 吞吐量调优就是减少垃圾收集器消耗的CPU周期数,从而将更多的CPU周期用于执行应用程序. CMS吞吐调优 CMS包 ...
- Java性能优化权威指南-读书笔记(四)-JVM性能调优-延迟
延迟指服务器处理一个请求所花费的时间,单位一般是ms.s. 本文主要讲降低延迟可以做的服务器端JVM优化. JVM延迟优化 新生代 新生代大小决定了应用平均延迟 如果平均Minor GC持续时间大于应 ...
- HTTP权威指南读书笔记
HTTP权威指南笔记 读书有两种境界,第一种境界是将书读薄,另一种是读厚.本篇文章就是HTTP权威指南的读书笔记,算是读书的第一重境界,将厚书读薄.文章对HTTP的一些关键概念做了比较详细的概述,通读 ...
随机推荐
- 【C/C++】龙格库塔+亚当姆斯求解数值微分初值问题
/* 解数值微分初值问题: 龙格-库塔法求前k个初值 + 亚当姆斯法 */ #include<bits/stdc++.h> using namespace std; double f(do ...
- Civil 3D 二次开发 名称模板不能正常工作
using Autodesk.AECC.Interop.Land; using Autodesk.AECC.Interop.UiLand; using Autodesk.AutoCAD.Applica ...
- BZOJ5419[Noi2018]情报中心——线段树合并+虚树+树形DP
题目链接: [NOI2018]情报中心 题目大意:给出一棵n个节点的树,边有非负边权,并给出m条链,对于每条链有一个代价,要求选出两条有公共边的链使两条链的并的边权和-两条链的代价和最大. 花了一天的 ...
- CSS初步学习
1.选择器: 如果你要在HTML元素中设置CSS样式,你需要在元素中设置"id" 和 "class"选择器. id 选择器 id 选择器可以为标有特定 id 的 ...
- bzoj 1029: [JSOI2007]建筑抢修 (优先队列)
链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1029 思路: 按结束时间排序,优先选结束时间短的,选完后扔到优先队列里(大的优先),如果选到 ...
- maven编译时出现There are test failures
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.10:test (default-tes ...
- flask项目第一次如何运行创建数据库
- MT【304】反射路径长度比
(高考压轴题改编)如图,长方体$ABCD-A_1B_1C_1D_1$中,$AB=11,AD=7,AA_1=12.$一质点从顶点$A$设向$E(4,3,12)$遇到长方体的面反射(服从光的反射原理),将 ...
- Android多种方法显示当前日期和时间
文章选自StackOverflow(简称:SOF)精选问答汇总系列文章之一,本系列文章将为读者分享国外最优质的精彩问与答,供读者学习和了解国外最新技术.本文探讨Android显示当前日期和时间的方法. ...
- 【转】从此以后谁也别说我不懂LDO了!
LDO是个很简单的器件,但是我跟客户沟通的过程中,发现客户工程师的技术水平参差不齐,有的工程师只是follow 别人以前的设计,任何原理和设计方法都不懂,希望大家看完这篇文章都能成为LDO 专家. 第 ...