python模块详情与开发规范
循环导入
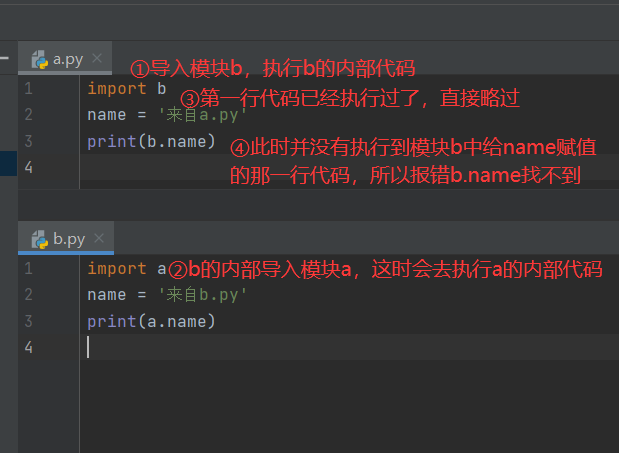
在初学模块时,我们有些时候会出现两个文件彼此导入,这时候可能会有报错。
比如有以下两个py文件
a.py
import b
name = '来自a.py'
print(b.name)
b.py
import a
name = '来自b.py'
print(a.name)
此时无论是执行a.py或是b.py都会报错,这是因为某个名字还没有被创建就被使用了。
解决办法
- 将导入模块的句式写在定义名字的下面
# 修改b.py文件为
name = '来自b.py'
import a # 放在定义名字的下面
print(a.name)
"""此时运行a.py文件就不会报错了,想要运行b.py文件就要修改a.py里的代码"""
- 将导入模块的句式写在函数体代码内
# 修改b.py文件为
# 修改b.py文件为
def index():
import a
print(a.name)
name = '来自b.py'
"""此时a.py中想要使用b.py里的名称就不会报错了"""
所以在编程过程中,循环导入问题我们一定要尽量去避免出现。

py文件类型
python文件可以被分为两种类型
- 执行文件
- 被导入文件
我们可以让py文件输出内置变量__name__来查看此时的文件是执行文件还是被导入文件。
创建a.py文件
print(__name__)
创建b.py文件
import a
执行a.py,执行结果:
__main__
执行b.py,执行结果:
a
可以看出,如果是执行文件时,输出__name__变量的值为__main__,而如果是被导入文件时,输出__name__变量的值为被导入文件的名称。
所以我们一般会利用这一结果用于区分被导入的代码和测试代码
if __name__ == '__main__':
代码块
"""
如果此文件是执行文件的时候才会执行if里面的代码
被别的文件导入的时候不会执行if里面的代码
"""

模块的查找顺序
模块查找顺序:内存空间-->内置模块-->sys.path中(类似于环境变量)。
在导入一个模块时,如果该模块已加载到内存空间中,就可以直接引用;在内存空间找不到该模块时,就会去内置模块中寻找,还是找不到的话就会去sys.path中查找,都找不到时就会报错。
sys.path的内容
# 导入模块sys
import sys
print(sys.path) # 输出sys.path
sys.path里的内容是一个列表,列表里面存放了很多路径。当内存中和内置中都没有要查找的模块时,就会去sys.path里的路径中挨个查找。
案例
创建如下文件和文件夹
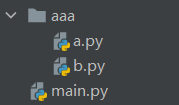
a.py
import b
name = '来自a.py'
print(b.name)
b.py
name = '来自b.py'
main.py
import a
print(a.name)
此时运行main.py会报错说找不到a,因为导模块时没有在内存、内置和sys.path中找到a。
解决办法一:使用sys.path.append添加路径
修改main.py
import sys
sys.path.append(r'.\aaa') # 添加文件夹aaa的路径即可
import a
print(a.name)
解决办法二:使用from...import...句式查找
修改main.py
from aaa import a
print(a.name)
但是此时运行main.py文件还是会报错,说模块b找不到啦,这是因为a.py执行代码导入模块b,查找模块b是按照main.py的sys.path路径查找的,所以会找不到b,所以还要修改a.py文件代码
修改a.py
from aaa import b
name = '来自a.py'
print(b.name)
这时候就没有问题啦!

相对导入与绝对导入
在导入模块的时候一切查找模块的句式都是以执行文件的路径为准,无论导入的句式是在执行文件中还是在被导入文件中。
绝对导入
永远按照执行文件所在的路径一层层往下查找。
如下图:
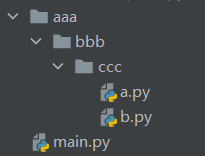
如果main.py想要导入a.py,并使用绝对导入
# main.py代码
from aaa.bbb.ccc import a
相对导入
相当导入打破了必须参照执行文件的所在路径的要求,只需要考虑当前模块所在的路径然后使用特殊符号"."去查找其他模块即可。
.表示当前路径
..表示上一层路径
../..表示上上一层路径
如下图:
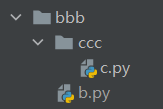
如果我想让在ccc文件夹中的c.py中想要导入b.py
# c.py代码
from .. import b
注意:相对导入只能在被导入文件中使用,不能在执行文件中使用。
包
从专业角度讲:包就是内部含有__init__.py的文件夹。
从实际角度讲:包就是多个模块的结合体(内部存放了多个模块文件)。
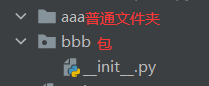
在导入普通文件夹里面的模块时,需要用绝对导入或者是给sys.path添加路径,但是导入包里面的模块时,是不需要这么做的,设计好__init__.py文件后,只要用import + 包名就可以了。
创建如下目录结构
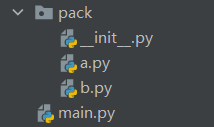
a.py
name = '来自a.py'
b.py
name = '来自b.py'
__init__.py
from . import a
from . import b
name_from_a = a.name
name_from_b = b.name
main.py
import pack
print(pack.name_from_a)
print(pack.name_from_b)
执行main.py结果
来自a.py
来自b.py
以上是包的使用方法,当然了,你也可以把包当成普通文件夹使用。
软件开发目录规范
其实软件开发的过程中,都是有规范的,哪个文件该放哪些文件夹都是需要注意的,这样才方便管理项目。

规范:
bin文件夹
存放程序的启动文件,如run.py之类的
conf文件夹
存放程序的配置文件,如settings.py之类的
core文件夹
存放程序的核心业务,实现具体需求的代码都放在里面
lib文件夹
存放程序公共的功能,如自定义模块之类的
db文件夹
存放程序的数据,比如用户信息之类数据会存放在这
log文件夹
存放程序的日志记录,如程序的报错信息、运行时间的信息存放在这
reademe文本文件
存放程序的说明、使用方法等额外的信息
requirements.txt文本文件
存放程序需要使用的第三方模块及对应的版本
特殊说明
目录的名字可以不一致,但是主要的思想是一致的,就是为了方便管理项目。

python模块详情与开发规范的更多相关文章
- Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型)
Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型) 一丶软件开发规范 六个目录: #### 对某 ...
- Python 入门之 软件开发规范
Python 入门之 软件开发规范 1.软件开发规范 -- 分文件 (1)为什么使用软件开发规范: 当几百行--大几万行代码存在于一个py文件中时存在的问题: 不便于管理 修改 可读性差 加载速度慢 ...
- import模块/包--软件开发规范
一. 模块 模块:就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. import加载的模块分为四个通用类别: 1 使用python编写的代码(.py文件) 2 已被编译 ...
- 扩展Python模块系列(一)----开发环境配置
本系列将介绍如何用C/C++扩展Python模块,使用C语言编写Python模块,添加到Python中作为一个built-in模块.Python与C之间的交互目前有几种方案: 1. 原生的Python ...
- python模块导入-软件开发目录规范-01
模块 模块的基本概念 模块: # 一系列功能的结合体 模块的三种来源 """ 模块的三种来源 1.python解释器内置的模块(os.sys....) 2.第三方的别人写 ...
- python基础-软件目录开发规范
为什么要设计好目录结构? "设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题.对于这种风格上的规范,一直都存在两种态度: 一类同学认为,这种个人风 ...
- python基础学习笔记——开发规范
> 编码 1 2 3 4 5 所有的 Python 脚本文件都应在文件头标上 # -*- coding:utf-8 -*- 用于设置编辑器,默认保存为 utf-8 格式. > 注释 ...
- CSIC_716_20191115【内置函数、递归、模块、软件开发规范】
内置函数 map map映射:语法结构(函数对象,可迭代对象) 依次从可迭代对象中取值,然后给函数做运算,再依次返回运算的结果. ss = map(lambda x: x + x, [1, 2, 3] ...
- python之模块、包的导入过程和开发规范
摘要:导入模块.导入包.编程规范 以My_module为例,My_module的代码如下: __all__ = ['name','read'] print('in mymodule') name = ...
随机推荐
- 002.MEMS应用在开关电源上,实现大功率超小型化
设计任务书 1.有关MEMS还有待具体了解 2.有关开关电源的目前难题也需要了解
- Linux网络配置:Nat和桥接模式详解
Linux网络配置:Nat和桥接模式详解 一.我们首先说一下VMware的几个虚拟设备: Centos虚拟网络编辑器中的虚拟交换机: VMnet0:用于虚拟桥接网络下的虚拟交换机: VMnet1:用于 ...
- Linux 0.11源码阅读笔记-文件IO流程
文件IO流程 用户进程read.write在高速缓冲块上读写数据,高速缓冲块和块设备交换数据. 什么时机将磁盘块数据读到缓冲块? 什么时机将缓冲块数据刷到磁盘块? 函数调用关系 read/write( ...
- java继承时能包括静态的变量和方法吗?举例说明!
子类继承了超类定义的所有实例变量和方法包括静态的变量和方法(马克-to-win见下例),并且为它自己增添了独特的元素.子类只能有一个超类.Java不支持多超类的继承. 子类拥有超类的所有成员,但它不能 ...
- 微信小程序获取今天,昨天,后天
today 是需要计算的某一天的日期例如"2018-12-12",传 null 默认今天,addDayCount 是要推算的天数, -1是前一天,0是今天,1是后一天. onLoa ...
- caioj 1001: [视频]实数运算1[水题]
题意:输入两个实数a和b,输出它们的和 题解:简单题不写题解了-- 代码: #include <cstdio> double a, b; int main() { while (~scan ...
- Vue UI 可视化项目管理界面
除了直接使用npm的命令进行安装脚手架的安装以外,我们还可以使用Vue提供的GUI方法vue ui来进行项目的构建以及安装 win+R powershell 打开终端 在一个干净的目录下输入命令 vu ...
- Sql获取表所有列名字段——select * 替换写法,Sqlserver、Oracle、PostgreSQL、Mysql
实际开发中经常用到select * from table,往往需要知道具体的字段,这个时候再去数据库中翻或者查看数据字典比较麻烦.为了方便,自己特意写了一个小函数f_selectall,针对SqlSe ...
- String_StringBuilder_StringBuffer 区别
1.String: String类是final修饰的,属于不可变(immutable)类,每次对原对象操作都会产生新的String对象. 源码中String类的定义:private final cha ...
- js中的undefined
undefined,一个特殊值,通常用于指示变量尚未赋值,是一个JavaScript的 原始数据类型 . 如果后台返回前台数据为空(无数据),那么用该对象获取其中的属性会显示undefined. 如果 ...