Flask像Jenkins一样构建自动化测试任务
flask这个框架很轻量,做一些小工具还是可以很快上手的。
1、自动化
某一天你入职了一家高大上的科技公司,开心的做着软件测试的工作,每天点点点,下班就走,晚上陪女朋友玩王者,生活很惬意。
但是美好时光一般不长,这种生活很快被女主管打破。为了提升公司测试效率,公司决定引入自动化流程,你在网上搜了一套技术方案 python + selenium,迅速写了一套自动化测试的脚本。
from selenium import webdriver
def test_selenium():
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
...
driver.quit()
...
编写脚本的日子很累,你需要每天加班,而且没有加班工资。 虽然如此,你也没有太多怨言,因为你能明显感觉到自己一点点掌握了自动化测试的流程,正在踏入职业发展的新阶段。这套脚本很快用于公司的主流程测试,也会在回归测试中使用。
因为大量的重复劳动都可以用这套自动化测试脚本代替,于是你又有时间陪女朋友了,上班也可以偶尔划水了,也可以时不时瞄一瞄自己的基金有没有涨。
当然,美好时光一般不长。在一次大改版中,前端页面发生了大量变化,你的自动化测试代码因为没有做抽象封装,基本已经不能用了。
又可以加班了,生活又可以充实起来了。你动用了一些像 PageObject 的模式对代码进行了重新设计,也加入了关键字驱动,尽量让测试逻辑变成可配置的。 设计完成以后,当前端页面变化时,只需要重点维护关键字表格。
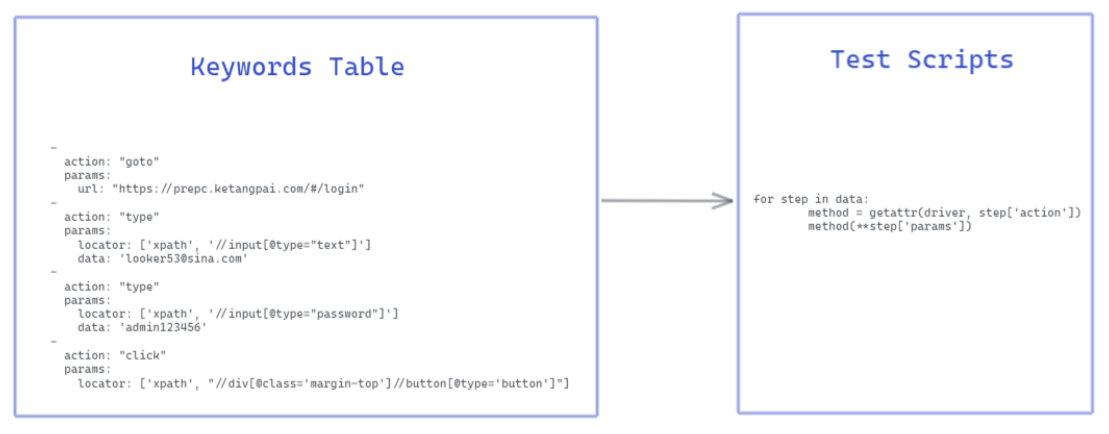
你又为公司做了一些贡献,你已经完全胜任自动化测试的工作,甚至能够带一两个小弟。他们时不时找你问一些问题,但是对于自动化的维护工作还是要靠你自己,当你请假时,这些工作只能停滞。于是公司希望你做一些改进,让功能测试人员也可以运行这些自动化测试。
2、开始测试平台
你看到网上有很多人提到测试平台,想着自己也可以做一个可视化平台,这样功能测试人员也可以通过在界面上进行简单的设置,就可以使用底层的自动化代码了。很快 flask 出现在你的视线中,你做的第一个功能就是实现类似于 jenkins 的构建功能。
首先,你搭建了一个 flask 服务,服务启动后,你能顺利访问 5000 端口。
from flask import Flask
app = Flask(__name__)
app.run(port=5000)
然后,你配置了一个 url 地址,当访问这个 url 地址时,服务会调用一个函数,这个 url 和函数的绑定关系就是路由。函数的返回值可以是普通字符串,可以是 json 数据,也可以是 html 页面。
@app.route('/')
def index():
"show all projects in workspace dir"
workspace = pathlib.Path(app.root_path) / 'workspace'
projects = [project.name for project in workspace.iterdir()]
return render_template('index.html', projects=projects)
上面的代码就是模仿 jenkins, 把自动化测试的脚本放在项目的 workspace 目录下,当访问 / 根路径时,index 函数就会被调用。index 函数的作用就是列举 workspace 目录下的所有项目名,通过 return 展示在前端界面。具体的前端代码如下:
<h2>展示所有的项目</h2>
{% for p in projects %}
<div>
{{ p }}
<a href="/build?project={{p}}">构建</a>
</div>
{% endfor %}

在页面上点击构建,程序会跳转到 flask 设置好的 /build 这个 url 中,这个路由负责运行自动化测试的代码,他会接收用户传过来的 project 参数,找到在 workspace 目录下的项目,再执行自动化测试指令(这里统一用 pytest 指令)。
@app.route("/build", methods=['get', 'post'])
def build():
project_name = request.args.get('project')
pytest.main([f'workspace/{project_name}'])
return "build success"
到目前为止,完整的流程是这样的:首先,在平台首页会展示所有可以构建的项目,这些项目其实就是把 workspace 子目录当中的目录名列举出来;然后,点击项目旁边的构建按钮,跳转到 /build,根据项目名称执行自动化指令,等待自动化任务执行完成,返回 build success。

3、优化
你基本上已经实现了功能,现在功能测试人员可以通过你搭建的简易平台执行自动化命令。但是这个平台还存在一些问题:第一、没有收集到构建信息,无法查看测试之后的结果;第二、用户必须等待自行测试脚本执行完成,才能返回前端具体的结果,如果自动化测试的执行时间很长,用户会一直停在这个页面,无法做其他事情。
你想到了并发编程,创建一个子进程单独去运行自动化测试脚本,因为子进程可以和主进程独立,所以不需要等待子进程执行完成,主进程就可以立即给前端返回结果。于是你重新编写了 build 函数:
@app.route("/build")
def build():
id = uuid.uuid4().hex
project_name = request.args.get('project')
with open(id, mode='w', encoding='utf-8') as f:
subprocess.Popen(
['pytest', f'workspace/{project_name}'],
stdout=f
)
return redirect(f'/build-history/{id}')
1、首先,通过 uuid 生成一个 id 号来表示这一次构建任务,之后可以通过这个 id 号查看此次构建的记录;
2、通过 subprocess 创建子进程运行自动化任务,把输出结果保存到文件当中,文件名就是生成的 id 号,之后想查看构建的结果时,只需要读取这个文件当中的内容;
3、只要子进程创建成功,马上通过 redirect 重定向到查看结果的 url, 此时并不需要等到子进程执行完就可以查看构建结果。
查看构建结果只需要通过 id 读取文件中的内容返回。
@app.route("/build-history/<id>")
def build_history(id):
with open(id, encoding='utf-8') as f:
data = f.read()
return data
4、生成器
上面读取文件的代码有点问题。当构建重定向到 /build-histrory 后,此时自动化测试脚本才刚刚执行,读取文件中的内容是空的。只有当测试脚本运行,产生越来越多的运行记录,文件中才会出现更多的内容,你必须手动刷新页面才能获取这些新内容。 当自动化任务执行时间很长的时候,你需要不停的刷新 /build-history 页面才能获取最新的构建信息。直到子进程结束,不再有新的内容被写入文件。
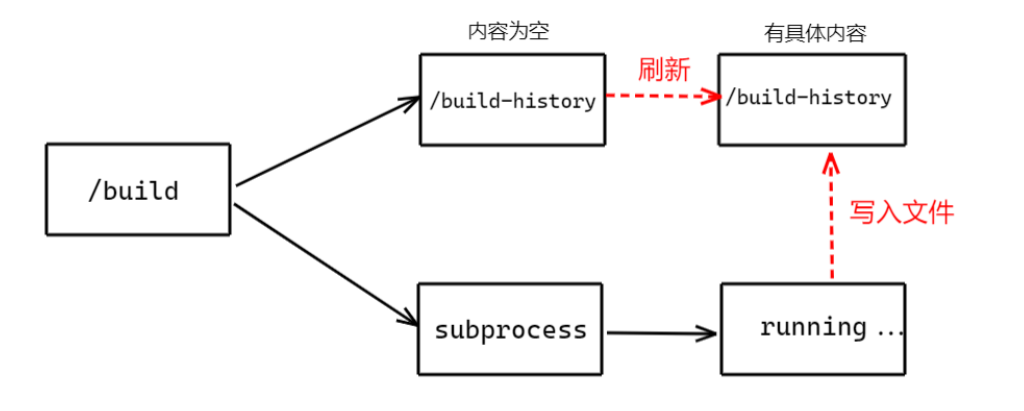
为了动态获取文件数据,你使用了生成器惰性获取数据,在 /build-history 的页面加载过程中,只要运行自动化任务的子进程还在运行,就不停的读取文件内容,将它们动态的返回给前端页面。
为了判断子进程的状态,在 /build 的时候,把子进程的 pid 传给 /build-history。
@app.route("/build", methods=['get', 'post'])
def build():
id = uuid.uuid4().hex
project_name = request.args.get('project')
with open(id, mode='w', encoding='utf-8') as f:
proc = subprocess.Popen(
['pytest', f'workspace/{project_name}'],
stdout=f
)
return redirect(f'/build-history/{id}?pid={proc.pid}')
在查看结果时,先编写一个生成器 stream, 每次读取文件中 100 长度的数据,直到进程运行结束。除了通过构建后的重定向,你也可以手动输入 id,查看历史构建记录。此时只需传 id, 不需要传进程名,直接读取文件中的数据。就算文件特别大,也可以通过批量加载,不至于因为同时读取大量数据给服务器造成压力。
import psutil
@app.route("/build-history/<id>")
def build_history(id):
pid = request.args.get('pid', None)
def stream():
f = open(id, encoding='utf-8')
if not pid:
while True:
data = f.read(100)
if not data:
break
yield data
else:
try:
proc = psutil.Process(pid=int(pid))
except:
return 'no such pid'
else:
while proc.is_running():
data = f.read(100)
yield data
return Response(stream())
最后效果:

5、总结
一般来说,做自动化测试只需要做到第一步,有脚本可以执行,就可以代替重复劳动。做测试平台只是让脚本变得更加好用。
但是有很多的测试平台让自动化运行起来更加复杂,要配置很多很多参数才能跑一个完整的测试用例,这似乎有点折本求末,也是很多人都在做的事情。
本文通过 flask 程序实现了一个最简单的 toy jenkins,辅助理解像 jenkins 这样的工具如何执行任务。其实像简单的构建任务,做起来也有很多问题需要解决,这些只有在遇到具体业务的时候我们才会去思考。
希望我们做的工具都是实用的,好用的。
Flask像Jenkins一样构建自动化测试任务的更多相关文章
- Jenkins+PMD构建自动化静态代码检测
前言:软件缺陷是不可避免的,要尽量减少错误并提高软件质量,主要有两在类技术,即缺陷预防和缺陷检测 缺陷预防包括编写更好的设计规范.实施代码审核制度.运行代码静态分析工具.运行单元测试等 PMD是一种开 ...
- jenkins + pipeline构建自动化部署
一.引言 Jenkins 2.x的精髓是Pipeline as Code,那为什么要用Pipeline呢?jenkins1.0也能实现自动化构建,但Pipeline能够将以前project中的配置信息 ...
- Jenkins下构建UI自动化之初体验
一.缘 起 笔者之前一直在Windows环境下编写UI自动化测试脚本,近日在看<京东系统质量保障技术实战>一书中,萌生出在jenkins下构建UI自动化测试的想法 二.思 路 首先,在Li ...
- 持续集成(CI):WEB自动化+Allure+Jenkins定时构建
一.allure插件安装 pytest可以通过allure集成展示优美的测试报告,同样allure也可以与Jenkins集成,并且Jenkins有构建记录,所以可以看到历史构建曲线图,通过曲线图可以清 ...
- Jenkins 构建自动化 .NET Core 发布镜像
Jenkins 构建自动化 .NET Core 发布镜像 导读 在本章中,将介绍如何在 Linux 下使用 Docker 部署.启动 Jenkins,编写脚本,自动化构建 .NET Core 应用,最 ...
- 【Gitlab+Jenkins+Ansible】构建自动化部署
说明: Gitlab.Jenkins.生产服务器.测试服务器上都需要安装Git. 一.安装Gitlab 1.主机配置 IP: 10.10.10.105 OS: CentOs7. Gitlab版本:gi ...
- 从零开始使用Jenkins来构建Docker容器(Ubuntu 14.04)
当开发更新了代码,提交到Gitlab上,然后由测试人员触发Jenkins,于是一个应用的新版本就被构建了.听起来貌似很简单,duang~duang~duang,我用了是这样,你们用了也是这样,看起来这 ...
- 使用Jenkins来构建Docker容器
使用Jenkins来构建Docker容器(Ubuntu 14.04) 当开发更新了代码,提交到Gitlab上,然后由测试人员触发Jenkins,于是一个应用的新版本就被构建了.听起来貌似很简单,dua ...
- Linux-GitLab+Jenkins持续集成+自动化部署
GitLab+Jenkins持续集成+自动化部署 什么是持续集成? (1)Continuous integration (CI) 持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个 ...
随机推荐
- 目标检测复习之Anchor Free系列
目标检测之Anchor Free系列 CenterNet(Object as point) 见之前的过的博客 CenterNet笔记 YOLOX 见之前目标检测复习之YOLO系列总结 YOLOX笔记 ...
- vue同时监听多个参数变化
computed: { // 同时监听多个参数 toWatch() { const { params1, params2 } = this.observeObj; return { params1, ...
- Solon 1.8.0 发布,云原生微服务开发框架
相对于 Spring Boot 和 Spring Cloud 的项目 启动快 5 - 10 倍 qps 高 2- 3 倍 运行时内存节省 1/3 ~ 1/2 打包可以缩小到 1/2 ~ 1/10(比如 ...
- poj3784(对顶堆)
题意:多组数据,让你求出1~i(i为奇数&&i<=n)的中位数 思路:首先复杂度必为O(n)或O(nlogn)的(数据范围) 思索,如果题目要求1次中位数,好求!排个序,取a[( ...
- 使用 KubeKey 搭建 Kubernetes/KubeSphere 环境的"心路(累)历程"
目录 今天要干嘛? 在哪里干? 从哪里开始干? 快速开干! 解决依赖问题再继续干! 如何干翻重来? 连着 KubeSphere 一起干! 干不过,输了. 重整旗鼓,继续干! 再次重整旗鼓,继续干! 一 ...
- Linux系列之安装中文字体
Linux系统安装中文字体 拷贝字体文件至Linux 从windows电脑的C:\Windows\fonts复制字体文件上传至Linux服务器新建的目录下 复制ttc.ttf文件至Linux服务器字体 ...
- 超级重磅!Apache Hudi多模索引对查询优化高达30倍
与许多其他事务数据系统一样,索引一直是 Apache Hudi 不可或缺的一部分,并且与普通表格式抽象不同. 在这篇博客中,我们讨论了我们如何重新构想索引并在 Apache Hudi 0.11.0 版 ...
- BUUCTF-佛系少年
佛系少年 这题我感觉超扯,不知道当时环境是不是断网的,断网咋解密的出来.. 下载后有个压缩包,带加密的,首先16进制看看是否是真加密 这里可以看到,压缩包数据区这里都是未加密的方式 但是到了压缩包目录 ...
- go int64传到前端导致溢出问题排查
简介 开周会的时候一位同事分享了一个踩坑经验,说在go里面还好好的int64类型,到前端就变得奇奇怪怪了,和原来不一样了.正好我对前端javascript有一点点了解,然后连夜写了点代码探索了一下 ...
- UiPath循环活动For Each的介绍和使用
一.For Each的介绍 For Each:循环迭代一个列表.数组.或其他类型的集合, 可以遍历并分别处理每条信息 二.For Each在UiPath中的使用 1. 打开设计器,在设计库中新建一个 ...