高性能、快响应!火山引擎 ByteHouse 物化视图功能及入门介绍
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
物化视图是指将视图的计算结果存储在数据库中的一种技术。当用户执行查询时,数据库会直接从已经预计算好的结果中获取数据,而不需要重新计算视图。具体来说,物化视图是一种以表格形式存储的结果集合。当创建一个物化视图时,数据库会在后台对视图进行计算,并将结果存储在表中。当用户查询该视图时,数据库会直接从表中获取结果,而不需要重新计算视图。这样可以大大提高查询性能和响应速度。
在使用物化视图时,需要注意以下四点:
物化视图的计算结果需要实时更新。如果源数据发生变化,需要及时更新物化视图的计算结果,以确保结果的准确性。
物化视图需要占用存储空间。由于物化视图需要将计算结果存储在表中,因此会占用一定的存储空间。在使用物化视图时,需要权衡存储空间和查询性能的关系。
物化视图需要考虑查询的复杂度。对于一些复杂的查询语句,物化视图可能无法提高查询性能。因此,在使用物化视图时,需要对查询语句进行分析和优化,以确保能够发挥物化视图的最大作用。
总之,物化视图是一种非常实用的技术,可以帮助我们提高数据库的查询性能和响应速度。在实际应用中,我们需要根据实际情况进行权衡和优化,以充分发挥物化视图的作用。
应用场景介绍
物化视图作为日常提高数据库查询性能和响应速度的一种实用技术,可以帮助业务人员在多个场景中收获价值。
场景 1:数据分析场景
以字节跳动举例,我们每天要处理大量的数据,比如包括用户行为数据、广告投放数据等等。这些数据往往需要进行复杂的查询和分析,使用物化视图来存储经常使用的数据,就可以减少复杂查询的执行时间,提高数据分析的效率。
场景 2:广告投放场景
在广告投放场景中,业务人员需要对广告投放数据进行实时监控和分析。物化视图可以帮助存储广告投放数据的计算结果,以便快速查询和分析。通过物化视图,快速地检测广告投放中的问题,减少广告投放的错误率,提高广告平台的效率和盈利能力。
场景 3:推荐系统
众所周知,推荐系统每天都需要对大量数据进行复杂计算与分析。通过使用物化视图,将计算结果存储在表格中,减少计算复杂度,提高推荐系统的响应速度。比如,我们可以通过物化视图存储用户的兴趣标签,加速对用户的个性化推荐。
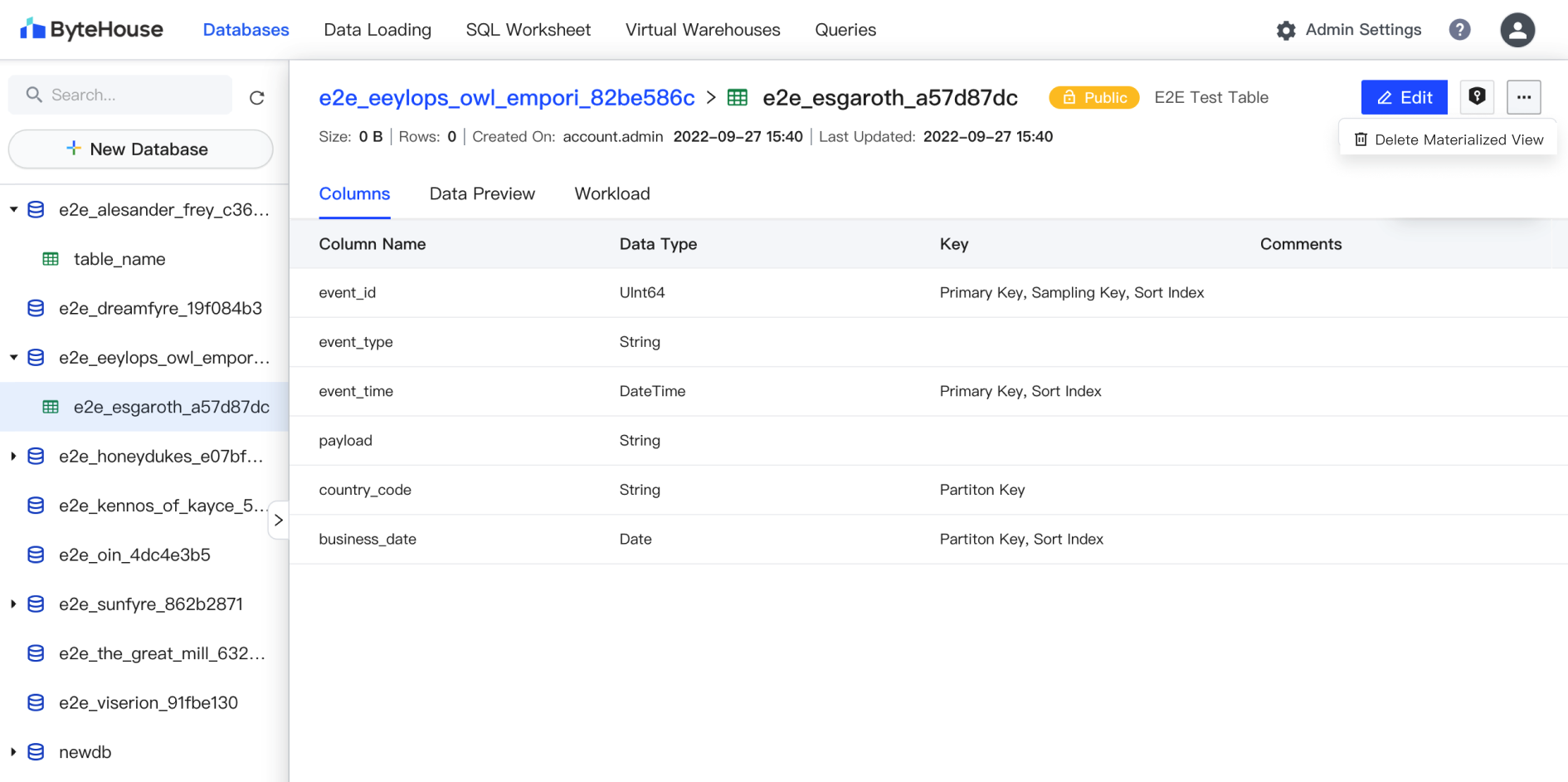
ByteHouse 物化视图快速入门
在 ByteHouse 客户的实际应用中,物化视图功能可以应用于许多场景。
比如,在电子商务网站中,我们可以创建一个物化视图,用于计算每个用户的订单总额。当需要查询某个用户的订单总额时,数据库只需要从物化视图中获取结果,而不需要重新计算,这可以大大提高查询的速度。
ByteHouse 客户——Chainbase 便是一个例子。Chainbase 是一个 Web3 开发者平台,为开发人员提供云化的 API 服务,以帮助接入加密网络、轻松构建可扩展的 Web3 原生应用。
开发者们可以使用 ChainBase,来构建高效、安全的区块链应用。ByteHouse 提供的物化视图功能,不仅能让 ChainBase 的查询速度得到提升,同时还实现了实时可视化的数据分析,大大提升了数据库查询分析的效率。
ByteHouse 的物化视图功能具备 7 个显著特点:
始终保持最新
可以手动或自动更新
易于使用,可以通过界面或 SQL 进行管理
ByteHouse 会自动为高频复杂查询创建物化视图
企业级功能
支持 RBAC
提供统计数据和建议,帮助用户优化物化视图
下面简单介绍如何快速入门,使用 ByteHouse 物化视图功能:
用户界面
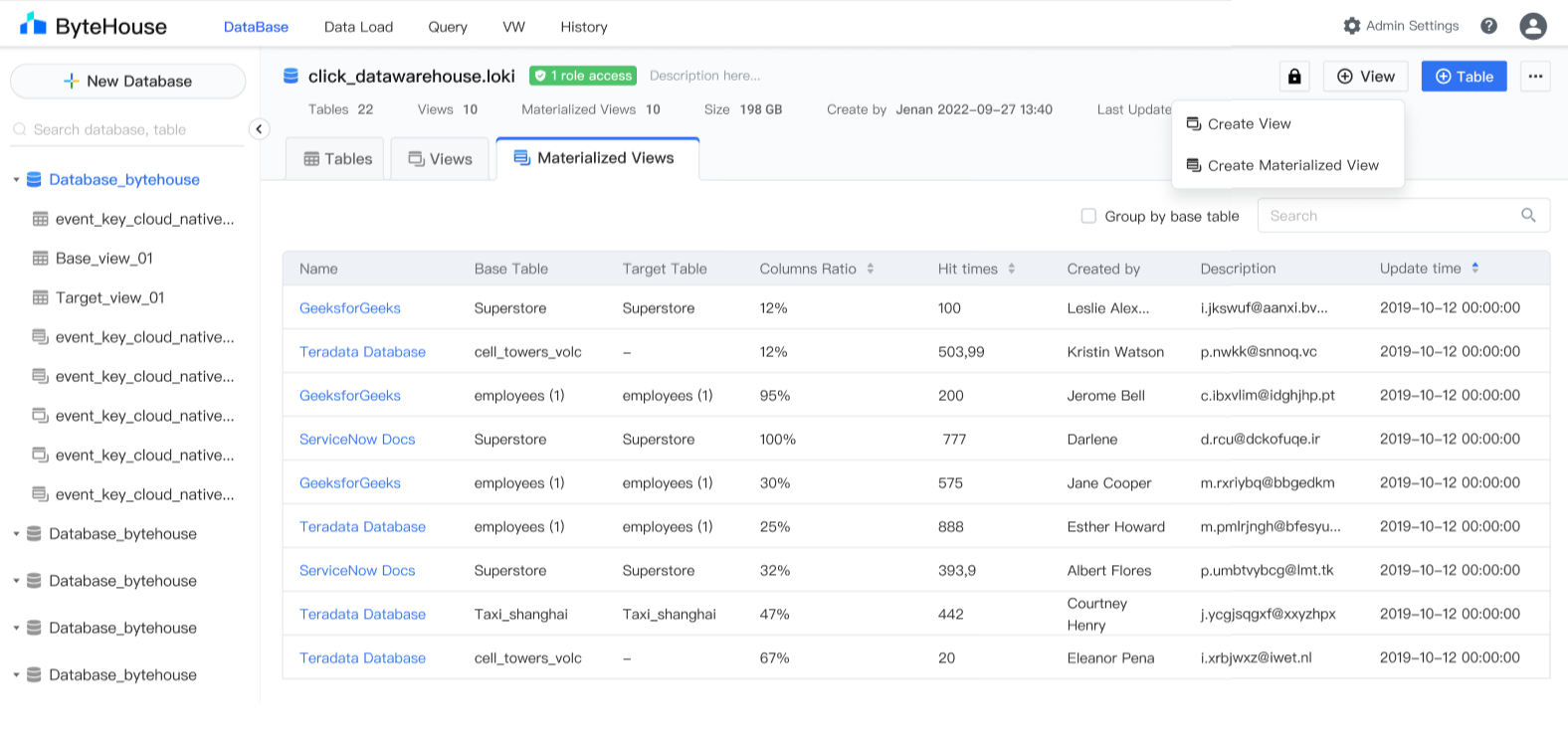
进入物化视图:数据库 > 新建 > 新建物化视图
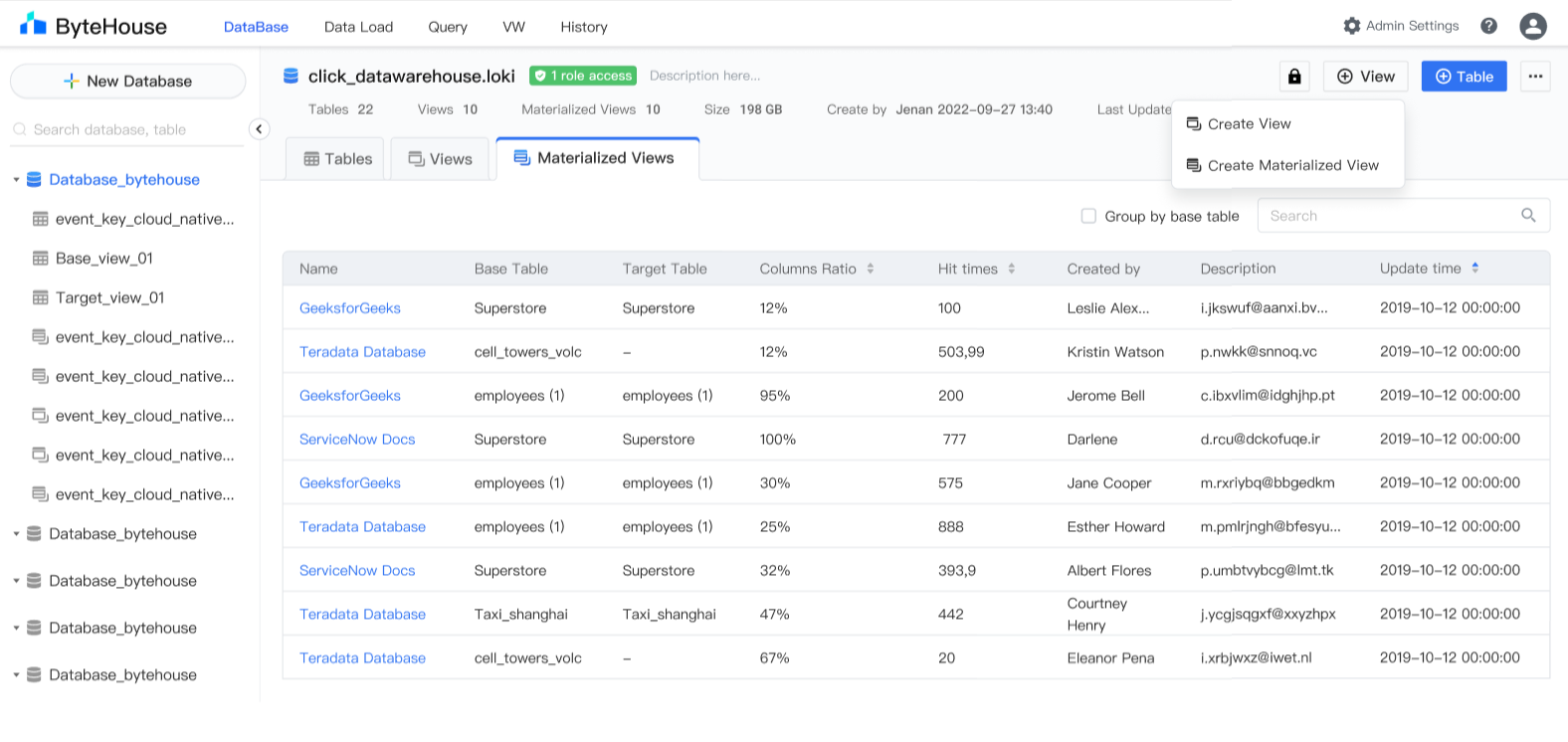
2. 根据 SQL 样例,填写物化视图语句。
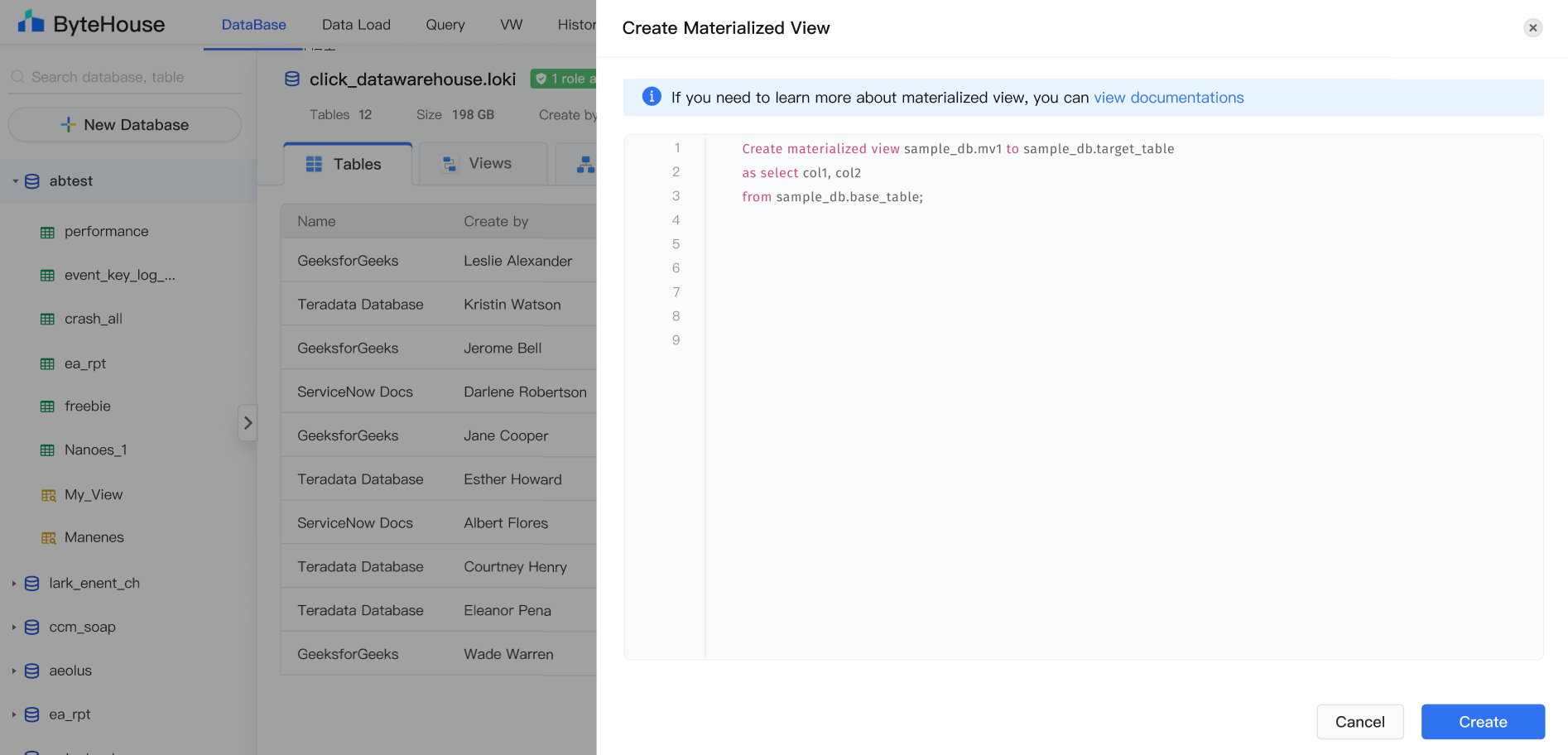
3.创建成功后。如果需要对以往历史的数据分区进行物化,根据 SQL 样例,手动刷新所定义分区。

如何进行 SQL 创建
推荐用法 - 手动定义目标表(target_table_name)的物化视图创建方法
CREATE MATERIALIZED VIEW [IF NOT EXISTS] mv_name [TO [db_name.]target_table_name]
AS SELECT select_statement FROM base_table_name;
其他用法 - 系统内部定义目标表的物化视图创建方法
CREATE MATERIALIZED VIEW [IF NOT EXISTS] mv_name(
[col1 DataType1]
[col2 DataType2]
...
)
[ENGINE = engine_name]
[PARTITION BY par_name]
[ORDER BY col_name [POPULATE]]
AS SELECT select_statement FROM base_table_name;
如何更新物化视图
在创建物化视图时刻起,物化视图的数据与原始表的数据同步更新,如果需要对以往历史的数据分区进行物化,对于运行中的物化视图,我们提供了刷新分区功能。
更新语法
REFRESH MATERIALIZED VIEW xxx PARTITION xxx
例子:
refresh materialized view test partition '2019-01-01' (同步'2019-01-01'分区的原始数据)
更新过程
该功能用来更新物化视图表的某个分区数据,并默认进行级联操作,即更新该视图表分区数据的同时,会同时更新依赖于当前视图表的所有物化视图的同一 partition,并一直级联传递下去。如果不想级联,可以加上 SETTINGS,设置 cascading_refresh_materialized_view 为 0,即:
refresh MATERIALIZED VIEW xxx PARTITION xxx SETTINGS cascading_refresh_materialized_view = 0
在更新视图分区数据时,相应底表分区的数据量可能十分巨大,更新会占用许多 CPU 和内存,还可能会导致更新失败,这时可以使用参数 max_rows_to_refresh_by_partition。在 Clickhouse 中一个 partition 由多个数据 part 组成,使用该参数,我们可以控制在该 partition 单机数据总行数超过该参数定义的值时,基于 part 级别一部分一部分的更新该分区,而不是在整个 partition 上进行更新,这样可以控制资源使用量。当然,如果视图是聚合表,按 part 一部分一部分的进行更新会导致最后视图数据的聚合效果不如在整个 partition 上进行更新,需要自己进行平衡。该参数默认值是 100000000 (1 亿),使用例子:
refresh MATERIALIZED VIEW xxx PARTITION xxx SETTINGS max_rows_to_refresh_by_partition = xxx
此外,可以使用 partitionStatus 函数获取一张物化视图表对应分区的状态,状态有三类:None (表示分区不存在),Normal (表示分区存在并处于正常状态),Refreshing (表示分区正在被更新)。例子:
select partitionStatus(test, test_mv, '2020-01-01')
如何管理物化视图
入口:数据库 > 物化视图
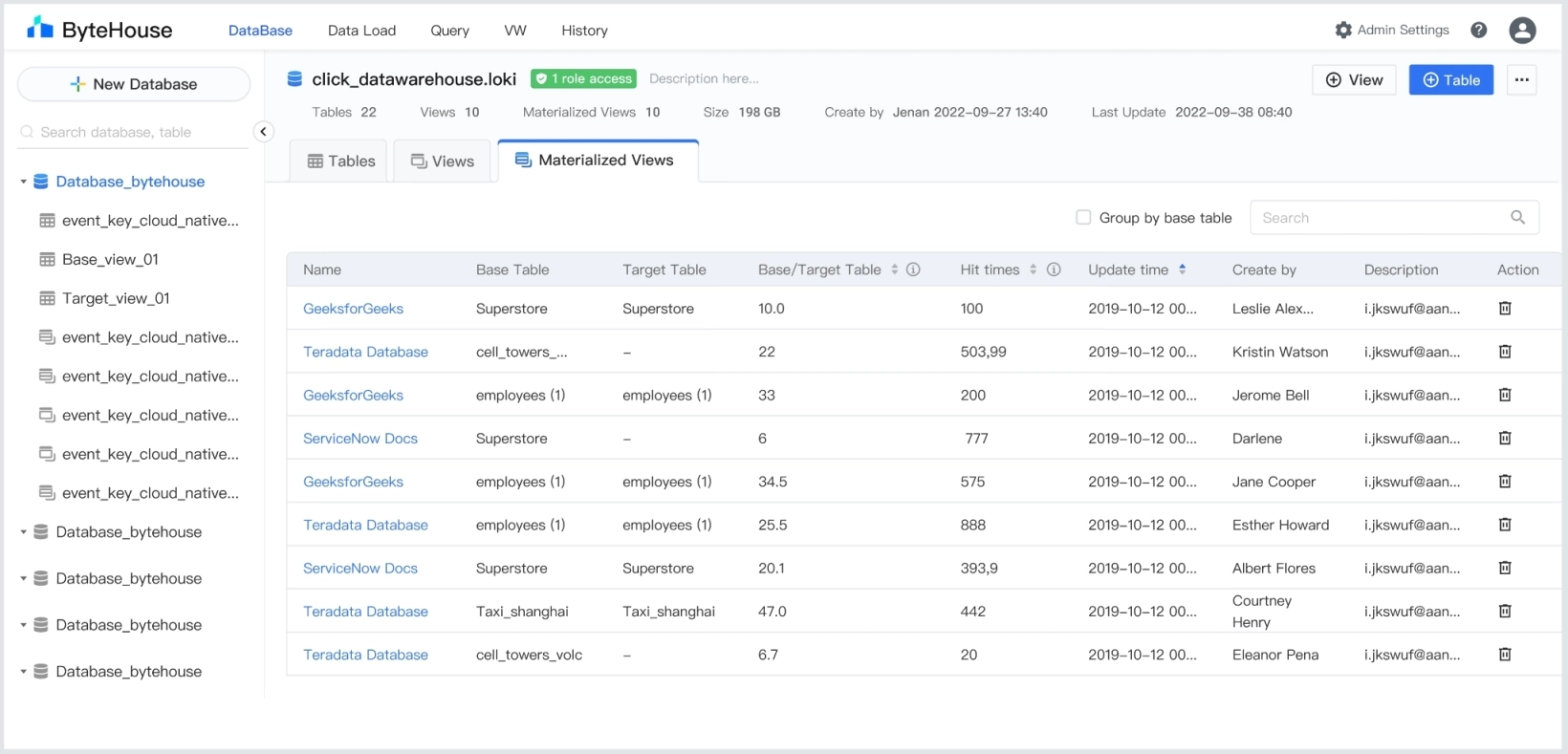
Bytehouse 会列出数据库中的所有物化视图,以及它们的底表/目标表行数比例,以及命中率。
底表/目标表行数比例:当该比例>10,则表示该物化视图比较有效率
命中率:当该命中率较高时,则表示该物化视图在 60 天内经常被访问
如何查询物化视图
用户可以直接查询物化视图,但一般推荐直接查询底表。Bytehouse 优化器会自动做出查询改写,以大幅度改善查询处理时间。
如何删除物化视图
用户可以通过界面或者 SQL 删除物化视图。
界面
如果用户创建了目标表,也需要手动 drop 目标表。
SQL
如果用户创建了目标表,也需要手动 drop 目标表。
drop view xxxx
点击跳转 火山引擎云原生数据仓库ByteHouse 了解更多
高性能、快响应!火山引擎 ByteHouse 物化视图功能及入门介绍的更多相关文章
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- HBase高性能复杂条件查询引擎
转自:http://blog.csdn.net/bluishglc/article/details/31799255 mark 写在前面 本文2014年7月份发表于InfoQ,HBase的PMC成员T ...
- SQL Server索引视图以(物化视图)及索引视图与查询重写
本位出处:http://www.cnblogs.com/wy123/p/6041122.html 经常听Oracle的同学说起来物化视图,物化视图的作用之一就是可以实现查询重写,听起来有一种高大上的感 ...
- postgres中的视图和物化视图
视图和物化视图区别 postgres中的视图和mysql中的视图是一样的,在查询的时候进行扫描子表的操作,而物化视图则是实实在在地将数据存成一张表.说说版本,物化视图是在9.3 之后才有的逻辑. 比较 ...
- ORACLE 物化视图
最近几天,我负责的P项目环境中提供给W系统的一个视图,由于查询逻辑复杂,数据量比较大,导致每次查询视图的时候,查询速度慢,效率低下,遭到了w系统人员的投诉.想了想,还是改成物化视图吧,用了物化视图,腰 ...
- [转载]oracle物化视图
原文URL:http://lzfhope.blog.163.com/blog/static/636399220124942523943/?suggestedreading&wumii 环境or ...
- 详解Oracle数据货场中三种优化:分区、维度和物化视图
转 xiewmang 新浪博客 本文主要介绍了Oracle数据货场中的三种优化:对分区的优化.维度优化和物化视图的优化,并给出了详细的优化代码,希望对您有所帮助. 我们在做数据库的项目时,对数据货场的 ...
- ClickHouse性能优化?试试物化视图
一.前言 ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS):目前我们使用CH作为实时数仓用于统计分析,在做性能优化的时候使用了 物化视图 这一特性作为优化手段,本文主 ...
随机推荐
- mergehex tools安装
(1)nRF5x command line tools包括Jlink驱动以及Nordic自己开发的一些命令行工具,具体包括Jlink驱动,nrfjprog,nrfutil以及mergehex等. 下载 ...
- Sqoop从MySQL向Hive增量式导入数据报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/json/JSONObject
1.问题描述: (1)问题示例: Step1:创建作业: [Hadoop@master TestDir]$ sqoop job \> --create myjob_1 \> -- impo ...
- 如何用猿大师播放器在网页上同时播放20路以上海康威视高分辨率(1920*1080)摄像头RTSP视频流?
问: 同时播放分辨率为1920*1080的高清分辨率的摄像头视频流,找了很长时间试过无数方法均不能满足,服务器转码方案卡顿非常严重,几乎不能播放.了解到猿大师可以用到本机的硬件解码和加速,播放高清视频 ...
- mysql查询增加自增列
mysql> SELECT a.user, @i:=@i+1 as id FROM user a,(SELECT @i:=0) b; +------------------+------+| u ...
- 一条随手的Arduino sketch优化 以Examples-02.Digital-Debounce为例
1 const int buttonPin = 2; 2 const int ledPin = 13; 3 4 int ledState = HIGH; 5 int buttonState; 6 in ...
- Markdown操作方法
Markdown学习 标题 三级标题 四级标题 字体 原本 hello,world! 斜体 hello,world! 加粗 hello,world! 斜体加粗 hello,world! 删除 hell ...
- 三天吃透MySQL面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础.Java基础.多线程.JVM.数据库.Redis.Spring.Mybatis.SpringMVC.SpringBoot.分布式.微服务.设计模式 ...
- Ipmitool命令之ipmitool user(用户管理)
常见的用户配置命令: (1)查看用户清单 root@master:~# ipmitool user list 1 ID Name Callin Link Auth IPMI Msg Channel P ...
- Java笔记第十三弹
函数式接口 有且仅有一个抽象方法的接口 适用于Lambda使用的接口 @FunctionalInterface//表示函数式接口 函数式接口作为方法的参数 public class Main{ pub ...
- 3.错误代码C4996
3.错误代码C4996 错误 C4996 'strcpy': This function or variable may be unsafe. Consider using strcpy_s inst ...