看完这一篇,ShardingSphere-jdbc 实战再也不怕了
谈到分库分表中间件时,我们自然而然的会想到 ShardingSphere-JDBC 。
这篇文章,我们聊聊 ShardingSphere-JDBC 相关知识点,并实战演示一番。
1 ShardingSphere 生态
Apache ShardingSphere 是一款分布式的数据库生态系统,它包含两大产品:
- ShardingSphere-Proxy
- ShardingSphere-JDBC
▍一、ShardingSphere-Proxy
ShardingSphere-Proxy 被定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
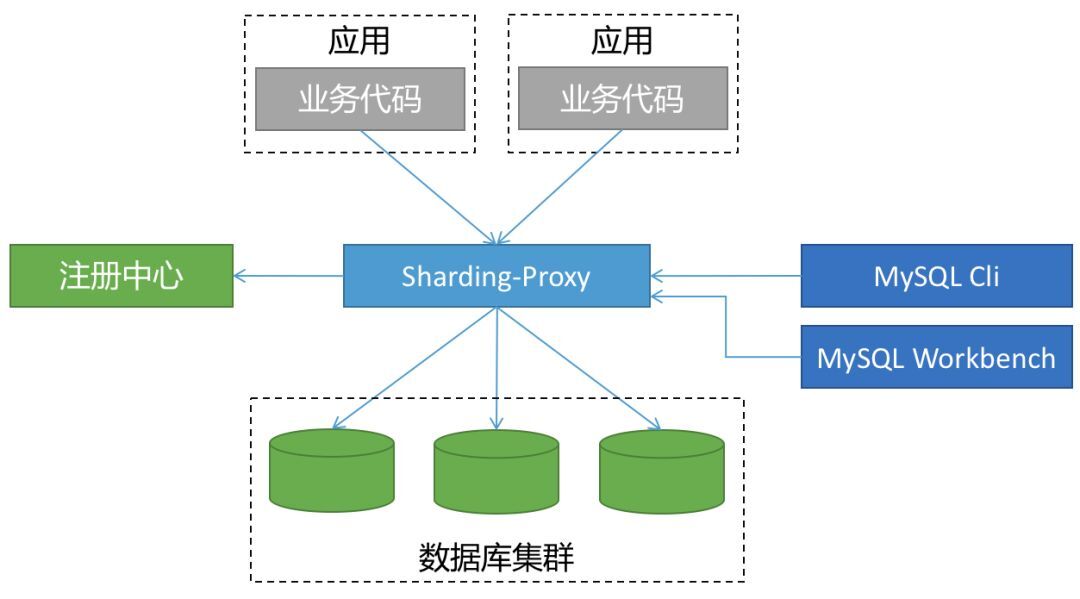
代理层介于应用程序与数据库间,每次请求都需要做一次转发,请求会存在额外的时延。
这种方式对于应用非常友好,应用基本零改动,和语言无关,可以通过连接共享减少连接数消耗。
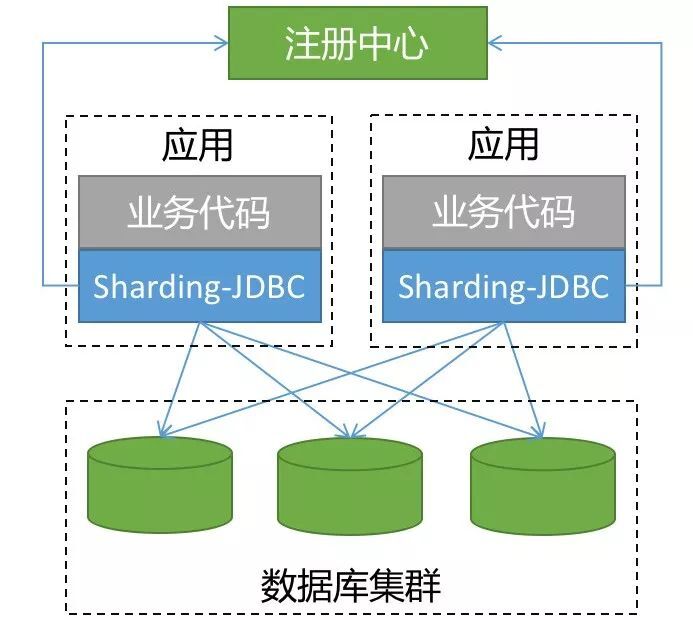
▍二、ShardingSphere-JDBC
ShardingSphere-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身, 我们经常简称之为:sharding-jdbc 。
它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
当我们在 Proxy 和 JDBC 两种模式选择时,可以参考下表对照:
| JDBC | Proxy | |
|---|---|---|
| 数据库 | 任意 |
MySQL/PostgreSQL |
| 连接消耗数 | 高 |
低 |
| 异构语言 | 仅Java |
任意 |
| 性能 | 损耗低 |
损耗略高 |
| 无中心化 | 是 |
否 |
| 静态入口 | 无 |
有 |
越来越多的公司都在生产环境使用了 sharding-jdbc ,最核心的原因就是:简单(原理简单,易于实现,方便运维)。
2 基本原理
在后端开发中,JDBC 编程是最基本的操作。不管 ORM 框架是 Mybatis 还是 Hibernate ,亦或是 spring-jpa ,他们的底层实现是 JDBC 的模型。
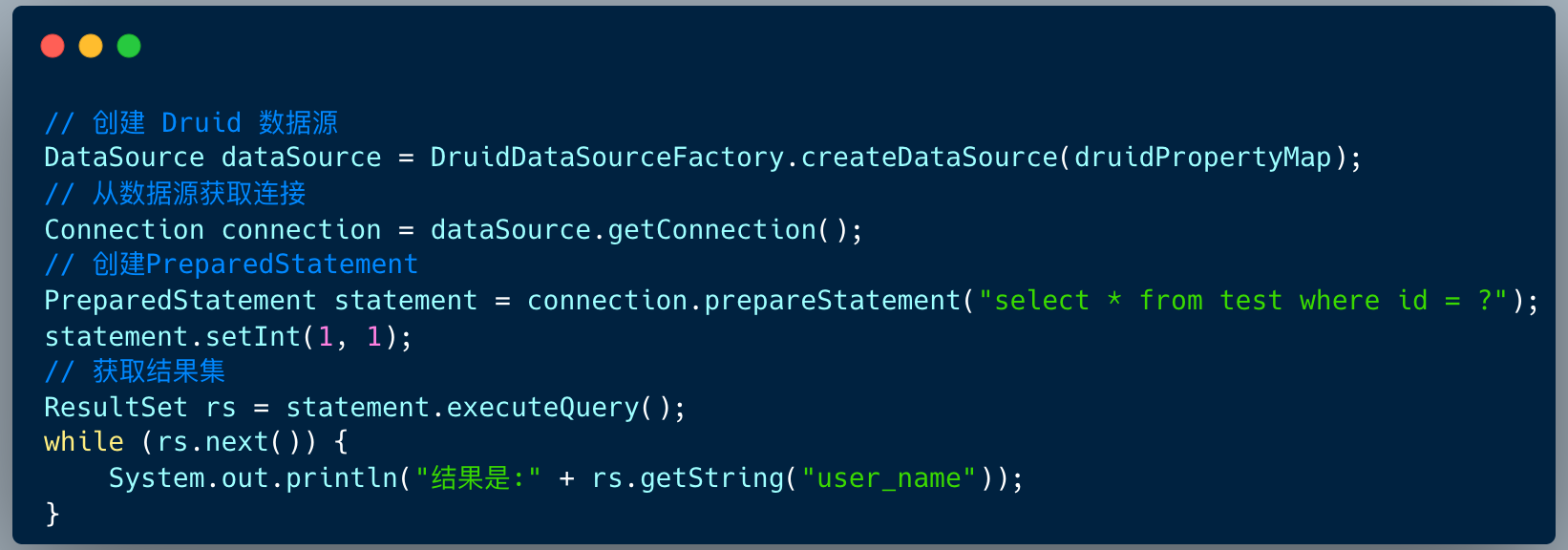
sharding-jdbc 的本质上就是实现 JDBC 的核心接口。
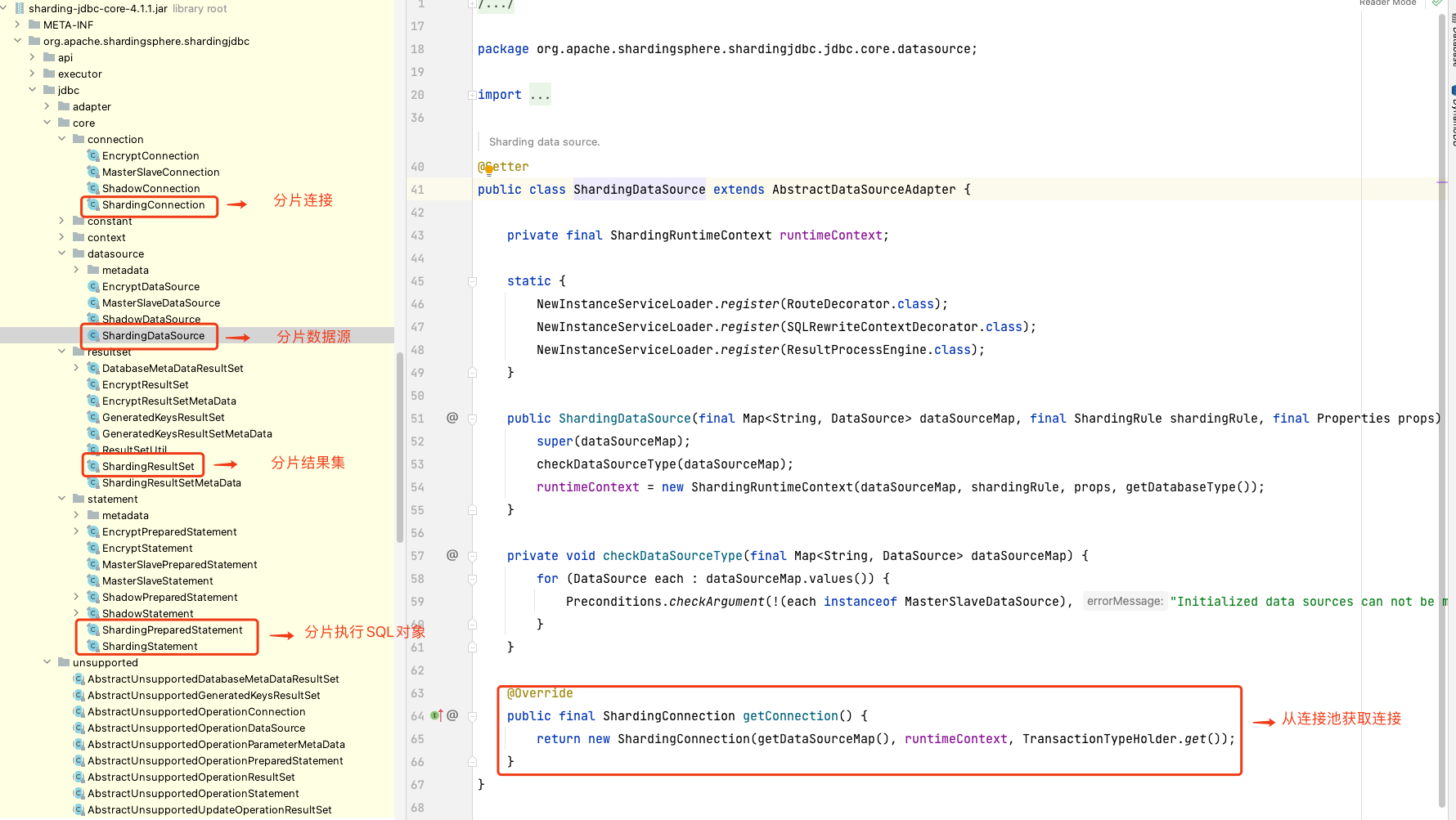
| 接口 | 实现类 |
|---|---|
| DataSource | ShardingDataSource |
| Connection | ShardingConnection |
| Statement | ShardingStatement |
| PreparedStatement | ShardingPreparedStatement |
| ResultSet | ShardingResultSet |
虽然我们理解了 sharding-jdbc 的本质,但是真正实现起来还有非常多的细节,下图展示了 Prxoy 和 JDBC 两种模式的核心流程。
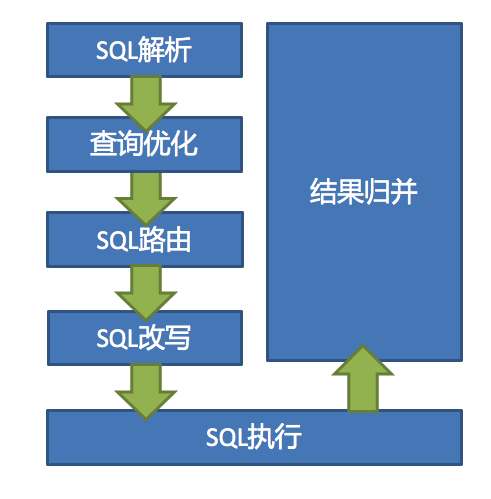
1.SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。
解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
2.执行器优化
合并和优化分片条件,如 OR 等。
3.SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
4.SQL 改写
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
5.SQL 执行
通过多线程执行器异步执行。
6.结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
本文的重点在于实战层面, sharding-jdbc 的实现原理细节我们会在后续的文章一一给大家呈现 。
3 实战案例
笔者曾经为武汉一家 O2O 公司订单服务做过分库分表架构设计 ,当企业用户创建一条采购订单 , 会生成如下记录:
订单基础表t_ent_order :单条记录
订单详情表t_ent_order_detail :单条记录
订单明细表t_ent_order_item:N 条记录
订单数据采用了如下的分库分表策略:
订单基础表按照 ent_id (企业用户编号) 分库 ,订单详情表保持一致;
订单明细表按照 ent_id (企业用户编号) 分库,同时也要按照 ent_id (企业编号) 分表。
首先创建 4 个库,分别是:ds_0、ds_1、ds_2、ds_3 。
这四个分库,每个分库都包含 订单基础表 , 订单详情表 ,订单明细表 。但是因为明细表需要分表,所以包含多张表。

然后 springboot 项目中配置依赖 :
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
配置文件中配置如下:
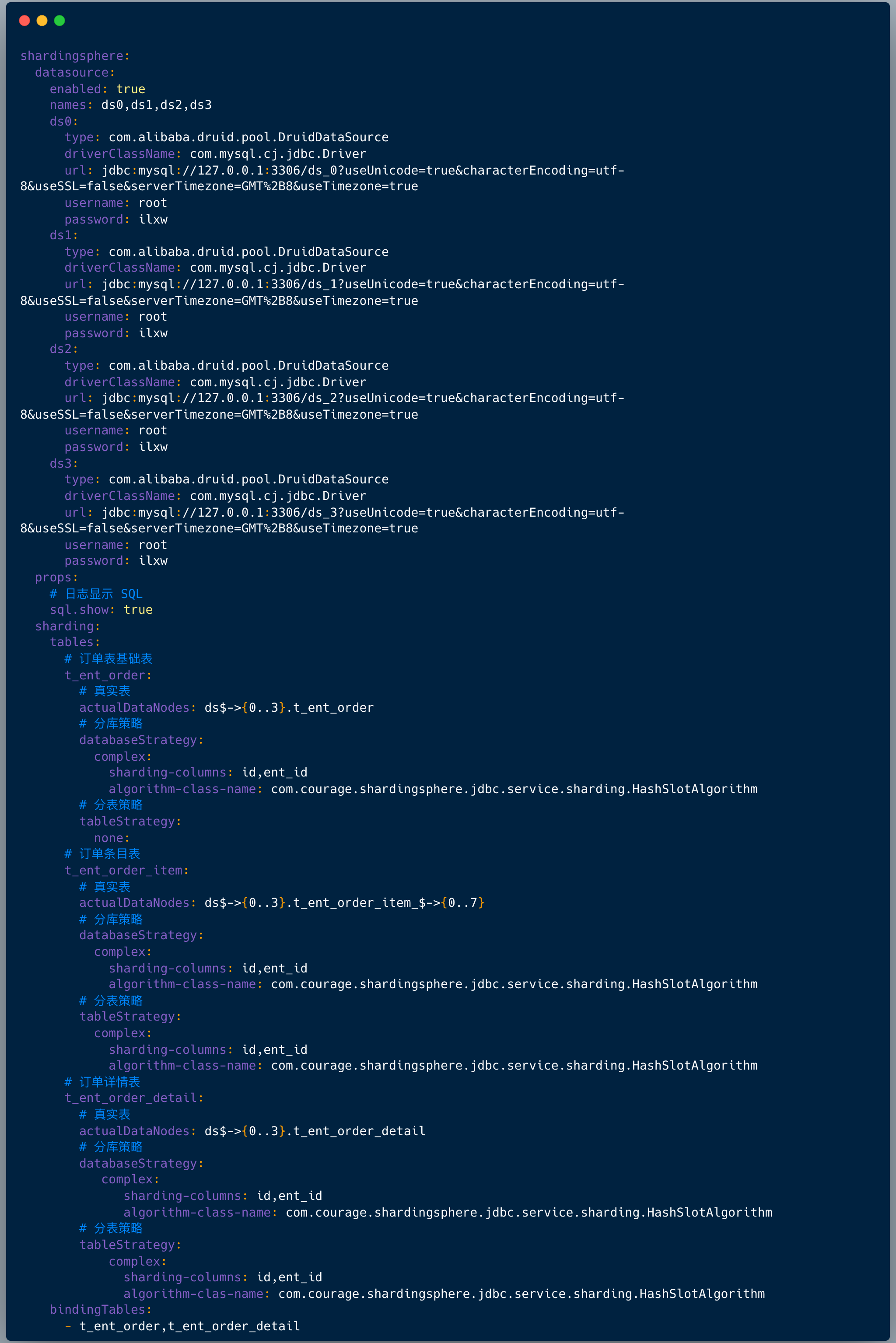
配置数据源,上面配置数据源是: ds0、ds1、ds2、ds3 ;
配置打印日志,也就是:sql.show ,在测试环境建议打开 ,便于调试;
配置哪些表需要分库分表 ,在 shardingsphere.datasource.sharding.tables 节点下面配置:

上图中我们看到配置分片规则包含如下两点:
1.真实节点
对于我们的应用来讲,我们查询的逻辑表是:t_ent_order_item 。
它们在数据库中的真实形态是:t_ent_order_item_0 到 t_ent_order_item_7。
真实数据节点是指数据分片的最小单元,由数据源名称和数据表组成。
订单明细表的真实节点是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。
2.分库分表算法
配置分库策略和分表策略 , 每种策略都需要配置分片字段( sharding-columns )和分片算法。
4 基因法 & 自定义复合分片算法
分片算法和阿里开源的数据库中间件 cobar 路由算法非常类似的。
假设现在需要将订单表平均拆分到4个分库 shard0 ,shard1 ,shard2 ,shard3 。
首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
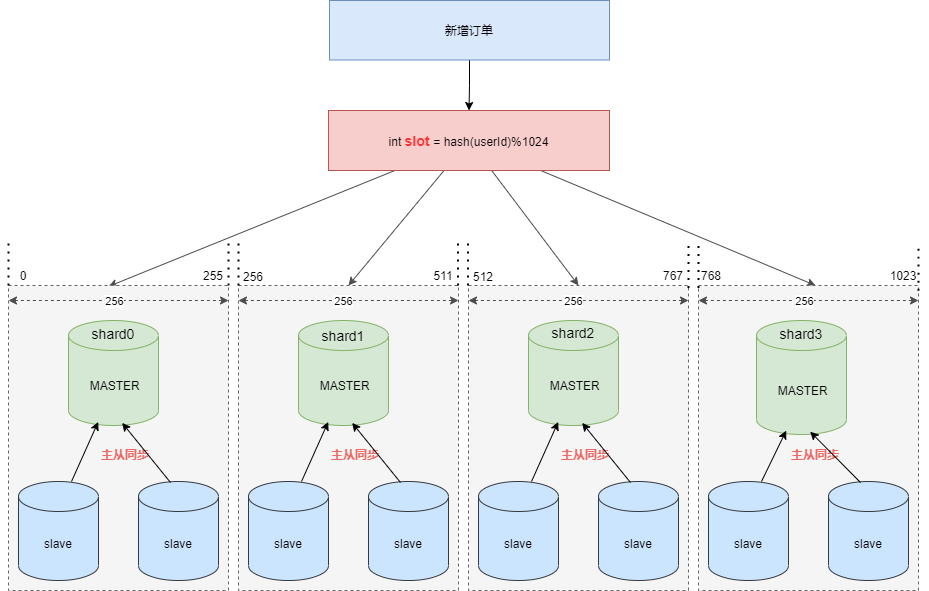
看起来分片算法很简单,但我们需要按照订单 ID 查询订单信息时依然需要路由四个分片,效率不高,那么如何优化呢 ?
答案是:基因法 & 自定义复合分片算法。
基因法是指在订单 ID 中携带企业用户编号信息,我们可以在创建订单 order_id 时使用雪花算法,然后将 slot 的值保存在 10位工作机器 ID 里。
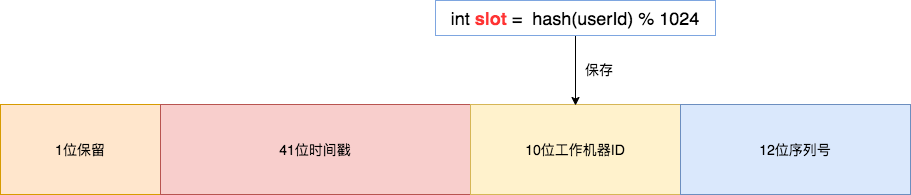
通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分片里。
Integer getWorkerId(Long orderId) {
Long workerId = (orderId >> 12) & 0x03ff;
return workerId.intValue();
}
下图展示了订单 ID 使用雪花算法的生成过程,生成的编号会携带企业用户 ID 信息。

解决了分布式 ID 问题,接下来的一个问题:sharding-jdbc 可否支持按照订单 ID ,企业用户 ID 两个字段来决定分片路由吗?
答案是:自定义复合分片算法。我们只需要实现 ComplexKeysShardingAlgorithm 类即可。
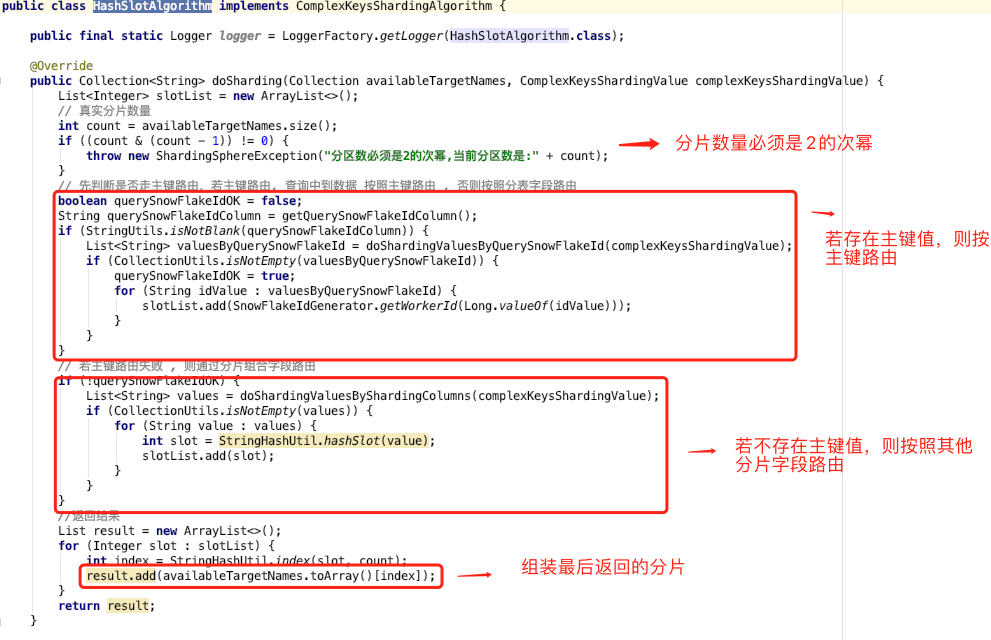
复合分片的算法流程非常简单:
1.分片键中有主键值,则直接通过主键解析出路由分片;
2.分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片。
5 扩容方案
既然做了分库分表,如何实现平滑扩容也是一个非常有趣的话题。
在数据同步之前,需要梳理迁移范围。
1.业务唯一主键;
在进行数据同步前,需要先梳理所有表的唯一业务 ID,只有确定了唯一业务 ID 才能实现数据的同步操作。
需要注意的是:业务中是否有使用数据库自增 ID 做为业务 ID 使用的,如果有需要业务先进行改造 。另外确保每个表是否都有唯一索引,一旦表中没有唯一索引,就会在数据同步过程中造成数据重复的风险,所以我们先将没有唯一索引的表根据业务场景增加唯一索引(有可能是联合唯一索引)。
2.迁移哪些表,迁移后的分库分表规则;
分表规则不同决定着 rehash 和数据校验的不同。需逐个表梳理是用户ID纬度分表还是非用户ID纬度分表、是否只分库不分表、是否不分库不分表等等。
接下来,进入数据同步环节。
整体方案见下图,数据同步基于 binlog ,独立的中间服务做同步,对业务代码无侵入。
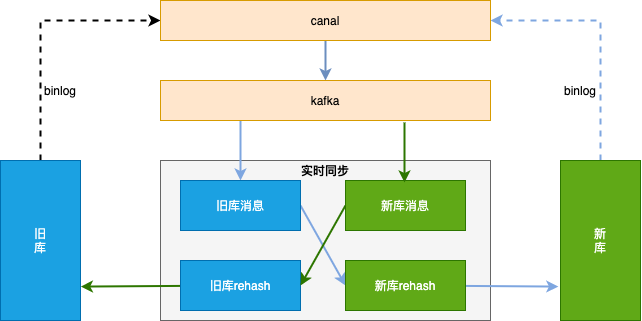
首先需要做历史数据全量同步:也就是将旧库迁移到新库。
单独一个服务,使用游标的方式从旧库分片 select 语句,经过 rehash 后批量插入 (batch insert)到新库,需要配置jdbc 连接串参数 rewriteBatchedStatements=true 才能使批处理操作生效。
因为历史数据也会存在不断的更新,如果先开启历史数据全量同步,则刚同步完成的数据有可能不是最新的。
所以我们会先开启增量数据单向同步(从旧库到新库),此时只是开启积压 kafka 消息并不会真正消费;然后在开始历史数据全量同步,当历史全量数据同步完成后,在开启消费 kafka 消息进行增量数据同步(提高全量同步效率减少积压也是关键的一环),这样来保证迁移数据过程中的数据一致。
增量数据同步考虑到灰度切流稳定性、容灾 和可回滚能力 ,采用实时双向同步方案,切流过程中一旦新库出现稳定性问题或者新库出现数据一致问题,可快速回滚切回旧库,保证数据库的稳定和数据可靠。
增量数据实时同步的大体思路 :
1.过滤循环消息
需要过滤掉循环同步的 binlog 消息 ;
2.数据合并
同一条记录的多条操作只保留最后一条。为了提高性能,数据同步组件接到 kafka 消息后不会立刻进行数据流转,而是先存到本地阻塞队列,然后由本地定时任务每X秒将本地队列中的N条数据进行数据流转操作。此时N条数据有可能是对同一张表同一条记录的操作,所以此处只需要保留最后一条(类似于 redis aof 重写);
3.update 转 insert
数据合并时,如果数据中有 insert + update 只保留最后一条 update ,会执行失败,所以此处需要将 update 转为 insert 语句 ;
4.按新表合并
将最终要提交的 N 条数据,按照新表进行拆分合并,这样可以直接按照新表纬度进行数据库批量操作,提高插入效率。
扩容方案文字来自 《256变4096:分库分表扩容如何实现平滑数据迁移》,笔者做了些许调整。
6 总结
sharding-jdbc 的本质是实现 JDBC 的核心接口,架构相对简单。
实战过程中,需要配置数据源信息,逻辑表对应的真实节点和分库分表策略(分片字段和分片算法)
实现分布式主键直接路由到对应分片,则需要使用基因法 & 自定义复合分片算法 。
平滑扩容的核心是全量同步和实时双向同步,工程上有不少细节。
实战代码地址:
https://github.com/makemyownlife/shardingsphere-jdbc-demo
参考资料:
256变4096:分库分表扩容如何实现平滑数据迁移?
黄东旭:分布式数据库历史、发展趋势与 TiDB 架构
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!

看完这一篇,ShardingSphere-jdbc 实战再也不怕了的更多相关文章
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
- Sql Or NoSql,看完这一篇你就懂了
前言 你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSql间纠结不定,到底该选用那种最好?今天的你就是昨天的我,这也是写这篇文章的初衷. 这篇文章是我好几 ...
- Sql Or NoSql,看完这一篇你就懂了(转五月的仓颉)
前言 你是否在为系统的数据库来一波大流量就几乎打满CPU,日常CPU居高不下烦恼?你是否在各种NoSql间纠结不定,到底该选用那种最好?今天的你就是昨天的我,这也是写这篇文章的初衷. 这篇文章是我好几 ...
- new的过程是怎样的?看完这一篇就懂了
在现实世界中,找对象是一门学问,找对象不在于多而在于精 在计算机世界中,面向对象编程的关键在于能否灵活地运用类,如何设计出一个符合需求的对象也是也是值得学习和思考的. 那么,面向对象编程到底是什么? ...
- Springboot 整合RabbitMq ,用心看完这一篇就够了
该篇文章内容较多,包括有rabbitMq相关的一些简单理论介绍,provider消息推送实例,consumer消息消费实例,Direct.Topic.Fanout的使用,消息回调.手动确认等. (但是 ...
- 什么是服务端渲染、客户端渲染、SPA、预渲染,看完这一篇就够了
服务端渲染(SSR) 简述: 又称为后端渲染,服务器端在返回html之前,在html特定的区域特定的符号里用数据填充,再给客户端,客户端只负责解析HTML. 鼠标右击点击查看源码时,页 ...
- 看完这一篇,再也不怕面试官问到IntentService的原理
IntentService是什么 在内部封装了 Handler.消息队列的一个Service子类,适合在后台执行一系列串行依次执行的耗时异步任务,方便了我们的日常coding(普通的Service则是 ...
- 了解Java内存模型,看完这一篇就够了
前言(此文草稿是年前写的,但由于杂事甚多一直未完善好.清明假无事,便收收尾发布了) 年关将近,个人工作学习怠惰了不少.两年前刚做开发的时候,信心满满想看看一个人通过自己的努力,最终能达到一个什么样的高 ...
- Python虚拟环境和包管理工具Pipenv的使用详解--看完这一篇就够了
前言 Python虚拟环境是一个虚拟化,从电脑独立开辟出来的环境.在这个虚拟环境中,我们可以pip安装各个项目不同的依赖包,从全局中隔离出来,利于管理. 传统的Python虚拟环境有virtualen ...
- 在知乎上看到 Web Socket这篇文章讲得确实挺好,从头看到尾都非常形象生动,一口气看完,没有半点模糊,非常不错
在知乎上看到这篇文章讲得确实挺好,从头看到尾都非常形象生动,一口气看完,没有半点模糊,非常不错,所以推荐给大家,非常值得一读. 作者:Ovear链接:https://www.zhihu.com/que ...
随机推荐
- VSCODE 中.art文件识别为html文件
setting.json文件中 { "git.ignoreMissingGitWarning": true, "explorer.confirmDelete": ...
- Dart开发服务端,我是不是发烧(骚)了?
前言 最近一段时间,我和我的团队开发了两个 APP. 客户端方面采用了 Flutter,方便跨平台. 服务端方面剑走偏锋,没有采用 php, pythod, java之类的,而是采用了与 Flutte ...
- uniapp中请求接口问题
在main.js文件中配置: //Vue.prototype.$baseUrl="http://192.168.1.164/api" //线下接口 Vue.prototype.$b ...
- apt install protobuf
protobuf介绍:https://www.cnblogs.com/niuben/p/14212711.html protobuf利用源码编译安装已经看到过很多方法,这里总结下用apt安装的方法. ...
- 基本能看懂的C编译器,只有365行!
Fabrice Bellard is a French computer programmer known for writing FFmpeg, QEMU, and the Tiny C Compi ...
- Spring 和 Spring MVC的区别
Spring 和 Spring MVC的区别 学习Spring MVC也有几天时间了,那么Spring和Spring MVC的区别到底在哪里,二者是什么关系呢?认为二者是一个东西那肯定是不对的,而 ...
- 04-Sed操作参数
1 Sed操作参数 1.1 s--替换 s表示替换(substitute)文件内的字符串. [address1],[address2]s/pattern/replacement/[flag] # s/ ...
- os 模块 sys模块 json模块
今日内容详细 os模块(重要) os模块主要与代码运行所在的操作系统打交道 import os 1.创建目录 1.创建目录(文件夹) os.mkdir(r'L4') # 只可以创建单级目录 相对路径 ...
- Java 进阶P-5.3+P-5.4
封装 增加可扩展性 可以运行的代码!=良好的代码 对代码做维护的时候最能看出代码的质量 如果想要增加一个方向,如down或up 用封装来降低耦合 Room类和Game类都有大量的代码和出口相关 尤其是 ...
- JAVA虚拟机15---虚拟机的类加载机制
1.概述 在Class文件中描述的各类信息,最终都需要加载到虚拟机中之后才能被运行和使用.而虚拟机如何加载这些Class文件,Class文件中的信息进入到虚拟机后会发生什么变化,这就涉及到虚拟机的类加 ...