在英特尔 CPU 上加速 Stable Diffusion 推理
前一段时间,我们向大家介绍了最新一代的 英特尔至强 CPU (代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的 分布式微调 和 推理。
本文将向你展示在 Sapphire Rapids CPU 上加速 Stable Diffusion 模型推理的各种技术。后续我们还计划发布对 Stable Diffusion 进行分布式微调的文章。
在撰写本文时,获得 Sapphire Rapids 服务器的最简单方法是使用 Amazon EC2 R7iz 系列实例。由于它仍处于预览阶段,你需要 注册 才能获得访问权限。与之前的文章一样,我使用的是 r7iz.metal-16xl 实例 (64 个 vCPU,512GB RAM),操作系统镜像为 Ubuntu 20.04 AMI (ami-07cd3e6c4915b2d18)。
本文的代码可从 Gitlab 上获取。我们开始吧!
Diffusers 库
Diffusers 库使得用 Stable Diffusion 模型生成图像变得极其简单。如果你不熟悉 Stable Diffusion 模型,这里有一个很棒的 图文介绍。
首先,我们创建一个包含以下库的虚拟环境: Transformers、Diffusers、Accelerate 以及 PyTorch。
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers accelerate torch==1.13.1
然后,我们写一个简单的基准测试函数,重复推理多次,最后返回单张图像生成的平均延迟。
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
现在,我们用默认的 float32 数据类型构建一个 StableDiffusionPipeline,并测量其推理延迟。
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
平均延迟为 32.3 秒。正如这个英特尔开发的 Hugging Face Space 所展示的,相同的代码在上一代英特尔至强 (代号 Ice Lake) 上运行需要大约 45 秒。
开箱即用,我们可以看到 Sapphire Rapids CPU 在没有任何代码更改的情况下速度相当快!
现在,让我们继续加速它吧!
Optimum Intel 与 OpenVINO
Optimum Intel 用于在英特尔平台上加速 Hugging Face 的端到端流水线。它的 API 和 Diffusers 原始 API 极其相似,因此所需代码改动很小。
Optimum Intel 支持 OpenVINO,这是一个用于高性能推理的英特尔开源工具包。
Optimum Intel 和 OpenVINO 安装如下:
pip install optimum[openvino]
相比于上文的代码,我们只需要将 StableDiffusionPipeline 替换为 OVStableDiffusionPipeline 即可。如需加载 PyTorch 模型并将其实时转换为 OpenVINO 格式,你只需在加载模型时设置 export=True。
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
# Don't forget to save the exported model
ov_pipe.save_pretrained("./openvino")
OpenVINO 会自动优化 bfloat16 模型,优化后的平均延迟下降到了 16.7 秒,相当不错的 2 倍加速。
上述 pipeline 支持动态输入尺寸,对输入图像 batch size 或分辨率没有任何限制。但在使用 Stable Diffusion 时,通常你的应用程序仅限于输出一种 (或几种) 不同分辨率的图像,例如 512x512 或 256x256。因此,通过固定 pipeline 的输出分辨率来解锁更高的性能增益有其实际意义。如果你需要不止一种输出分辨率,您可以简单地维护几个 pipeline 实例,每个分辨率一个。
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
固定输出分辨率后,平均延迟进一步降至 4.7 秒,又获得了额外的 3.5 倍加速。
如你所见,OpenVINO 是加速 Stable Diffusion 推理的一种简单有效的方法。与 Sapphire Rapids CPU 结合使用时,和至强 Ice Lake 的最初性能的相比,推理性能加速近 10 倍。
如果你不能或不想使用 OpenVINO,本文下半部分会展示一系列其他优化技术。系好安全带!
系统级优化
扩散模型是数 GB 的大模型,图像生成是一种内存密集型操作。通过安装高性能内存分配库,我们能够加速内存操作并使之能在 CPU 核之间并行处理。请注意,这将更改系统的默认内存分配库。你可以通过卸载新库来返回默认库。
jemalloc 和 tcmalloc 是两个很有意思的内存优化库。这里,我们使用 jemalloc,因为我们测试下来,它的性能比 tcmalloc 略好。 jemalloc 还可以用于针对特定工作负载进行调优,如最大化 CPU 利用率。详情可参考 jemalloc调优指南。
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
接下来,我们安装 libiomp 库来优化多核并行,这个库是 英特尔 OpenMP 运行时库 的一部分。
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
最后,我们安装 numactl 命令行工具。它让我们可以把我们的 Python 进程绑定到指定的核,并避免一些上下文切换开销。
numactl -C 0-31 python sd_blog_1.py
使用这些优化后,原始的 Diffusers 代码只需 11.8 秒 就可以完成推理,快了几乎 3 倍,而且无需任何代码更改。这些工具在我们的 32 核至强 CPU 上运行得相当不错。
我们还有招。现在我们把 英特尔 PyTorch 扩展 (Intel Extension for PyTorch, IPEX) 引入进来。
IPEX 与 BF16
IPEX 扩展了 PyTorch 使之可以进一步充分利用英特尔 CPU 上的硬件加速功能,包括 AVX-512 、矢量神经网络指令 (Vector Neural Network Instructions,AVX512 VNNI) 以及 先进矩阵扩展 (AMX)。
我们先安装 IPEX。
pip install intel_extension_for_pytorch==1.13.100
装好后,我们需要修改部分代码以将 IPEX 优化应用到 pipeline 的每个模块 (你可以通过打印 pipe 对象罗列出它有哪些模块),其中之一的优化就是把数据格式转换为 channels-last 格式。
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
# to channels last
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
# Create random input to enable JIT compilation
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
# optimize with IPEX
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
我们使用了 bloat16 数据类型,以利用 Sapphire Rapids CPU 上的 AMX 加速器。
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
经过此番改动,推理延迟从 11.9 秒进一步减少到 5.4 秒。感谢 IPEX 和 AMX,推理速度提高了 2 倍以上。
还能榨点性能出来吗?能,我们将目光转向调度器 (scheduler)!
调度器
Diffusers 库支持为每个 Stable Diffusion pipiline 配置 调度器 (scheduler),用于在去噪速度和去噪质量之间找到最佳折衷。
根据文档所述: “ 截至本文档撰写时,DPMSolverMultistepScheduler 能实现最佳的速度/质量权衡,只需 20 步即可运行。” 我们可以试一下 DPMSolverMultistepScheduler。
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
最终,推理延迟降至 5.05 秒。与我们最初的 Sapphire Rapids 基线 (32.3 秒) 相比,几乎快了 6.5 倍!
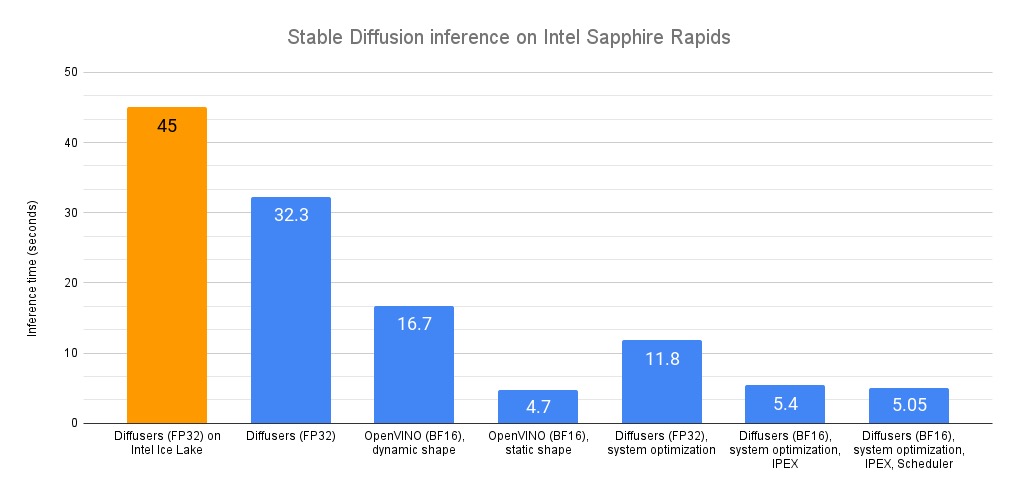
运行环境: Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7
总结
在几秒钟内生成高质量图像的能力可用于许多场景,如 2C 的应用程序、营销和媒体领域的内容生成,或生成合成数据以扩充数据集。
如你想要在这方面起步,以下是一些有用的资源:
- Diffusers 文档
- Optimum Intel 文档
- 英特尔 IPEX on GitHub
- 英特尔和 Hugging Face 联合出品的开发者资源网站
如果你有任何问题或反馈,请通过 Hugging Face 论坛 告诉我们。
感谢垂阅!
英文原文: https://hf.co/blog/stable-diffusion-inference-intel
作者: Julien Simon, Ella Charlaix
译者: MatrixYao
审校/排版: zhongdongy (阿东)
在英特尔 CPU 上加速 Stable Diffusion 推理的更多相关文章
- 现代英特尔® 架构上的 TensorFlow* 优化——正如去年参加Intel AI会议一样,Intel自己提供了对接自己AI CPU优化版本的Tensorflow,下载链接见后,同时可以基于谷歌官方的tf版本直接编译生成安装包
现代英特尔® 架构上的 TensorFlow* 优化 转自:https://software.intel.com/zh-cn/articles/tensorflow-optimizations-on- ...
- 英特尔与 Facebook 合作采用第三代英特尔® 至强® 可扩展处理器和支持 BFloat16 加速的英特尔® 深度学习加速技术,提高 PyTorch 性能
英特尔与 Facebook 曾联手合作,在多卡训练工作负载中验证了 BFloat16 (BF16) 的优势:在不修改训练超参数的情况下,BFloat16 与单精度 32 位浮点数 (FP32) 得到了 ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
- 使用英特尔 Sapphire Rapids 加速 PyTorch Transformers 模型
大约一年以前,我们 展示 了如何在第三代 英特尔至强可扩展 CPU (即 Ice Lake) 集群上分布式训练 Hugging Face transformers 模型.最近,英特尔发布了代号为 Sa ...
- 【硬件】- 英特尔CPU命名中的产品线后缀
产品线后缀是CPU命名体系里最复杂最难懂的,在英特尔冗长的产品线中,CPU的后缀也是千变万化.不带后缀的CPU一般就是最普通的桌面级处理器,不管是性能还是价格都比较中庸,比如当前性价比较高的Core ...
- 【硬件】- 英特尔CPU命名规则
前言 一款Intel CPU的命名,一般由5个部分组成:品牌,品牌标识符,Gen标识,SKU数值,产品线后缀. 以下图为例: 品牌 英特尔旗下处理器有许多子品牌,包括我们熟悉的凌动(ATOM).赛扬( ...
- 2020年英特尔CPU供应短缺将持续
导读 有着相当靠谱的爆料历史的台媒 DigiTimes 报道称,其预计英特尔的 CPU 供应短缺问题,将持续到 2020 年末.对于这样的预测,我们其实早已见怪不怪,毕竟该公司首席执行官 Bob Sw ...
- 英特尔CPU系列
1.酷睿(Core)系列,主要应用于管理 3D.高级视频和照片编辑,玩复杂游戏,享受高分辨率 4K 显示. 2.奔腾(PenTIum)系列,主要应用于借助功能丰富的处理器,加快便携式 2 合 1 电脑 ...
- Linux 4.20内核得到更新,英特尔CPU 性能降低50%
根据HKEPC的报道,Linux近日发布了 4.20 内核的一些漏洞修复更新,更新后可能会出现50% 的性能损失,是今年内所有安装Spectre/Meltdown 修补程式中效能跌幅最大的一次. 据报 ...
- VR电竞游戏在英特尔®架构上的用户体验优化
作为人与虚拟世界之间的新型交互方式,VR 能够让用户在模拟现实中获得身临其境的感受.但是,鉴于 VR 的帧预算为每帧 11.1ms (90fps),实现实时渲染并不容易,需要对整个场景渲染两次(一只眼 ...
随机推荐
- 接口返回JSON字符串压缩和解压
using System;using System.Collections.Generic;using System.Linq;using System.Web;using System.IO;usi ...
- antv g6 出现 n.addEdge is not a function问题
问题描述直接上图 解决方式就是将edge里面边的source和target对应的id换成字符串类型就行. 例如: edges: [ { id: 299, source": 3629.toSt ...
- vue-cli简介
1.定义:vue-cli(俗称:vue 脚手架)是 vue 官方提供的.快速生成 vue 工程化项目的工具,提供了终端里的 vue 命令.它可以通过 vue create 快速搭建一个新项目: 特点: ...
- 实践课:i至诚app案例分析---江洁兰
这个作业属于哪个课程 至诚软工实践F班 这个作业要求在哪里 作业要求 这个作业的目标 分析产品软件,找出其中的问题并进行分析,提高对产品软件bug方面的认识 学号 212106715 第一部分 找Bu ...
- raid随笔
1.raid 0 准备两个磁盘 [root@localhost ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 40G 0 disk ...
- EVE如何提升名望值
目录 背景介绍 简介 名望值划分 军团名望值 利弊 背景介绍 玩eve将近3个星期,开着毒蜥级刷1级代理人任务感觉没有一点难度,想尽快刷3.4级代理任务,而我目前能够接到的最高代理任务也就才1级. ...
- loadrunner入门(关联)
左右边界:提取第一个id web_reg_save_param_ex( "ParamName=Id", "LB=//OK[ ...
- Go_day08
Go的Io流 获取文件信息 //获取文件 fileinfo, err := os.Stat("./aa.txt")//相对绝对路径都可以 if err != nil { fmt.P ...
- 使用react-vite-antd,修改antd主题,报错 [vite] Internal server error: Inline JavaScript is not enabled. Is it set in your options? It is hacky way to make this function will be compiled preferentially by less
一般报错 在官方文档中,没有关于vite中如何使用自定义主题的相关配置,经过查阅 1.安装less yarn add less (已经安装了就不必再安装) 2.首先将App.css改成App.les ...
- CentOS7更改阿里源
阿里云yum源:1)备份当前yum源防止出现意外还可以还原回来cd /etc/yum.repos.d/cp /CentOS-Base.repo /CentOS-Base-repo.bak2)使用wge ...