【python爬虫】bilibili每周必看页面视频图片爬取
此博客仅作为交流学习
对于使用bilibili上学习和娱乐的小伙伴们有时会看到视频博主发布的视频封面好看想要得到,但是苦于没有方法,这次我用python来爬取bilibili每周必看页面视频图片。
首先分析页面:
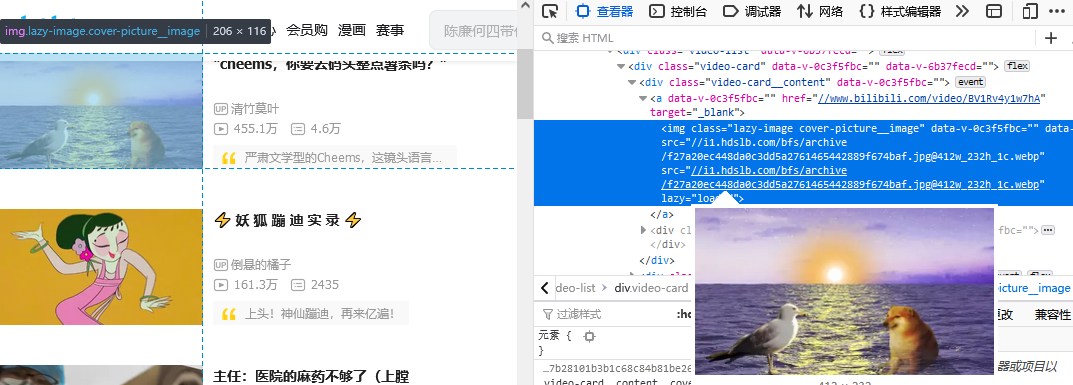
如上图所示,当我们想要在页面爬取图片时,往往得不到页面图片的地址,这时我们也得不到图片
开始抓包分析:
点击Network,CTRL+R开始抓包点击下面页面
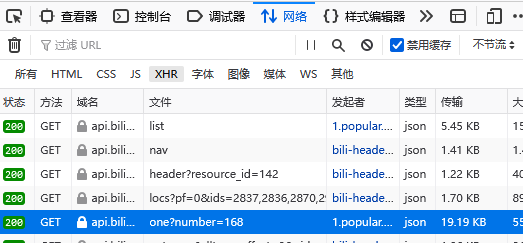
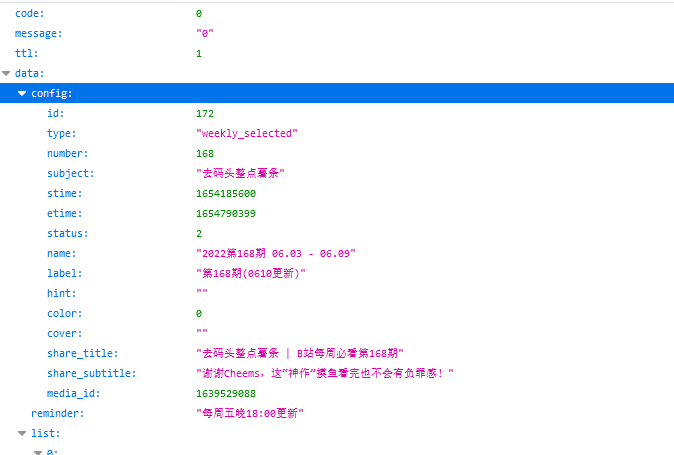
发现页面是json
那么,只要进入当前页面解析并提取页面信息便可以拿到图片地址,进而得到视频封面了
import requests
import pprint url = 'https://api.bilibili.com/x/web-interface/popular/series/one?number=168' #抓包网页
response = requests.get(url=url)
data = response.json()
pprint.pprint(data) #将页面内容规范为易懂可视页面
分析页面:
解析并保存:
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
print([pic,title]) imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
效果:
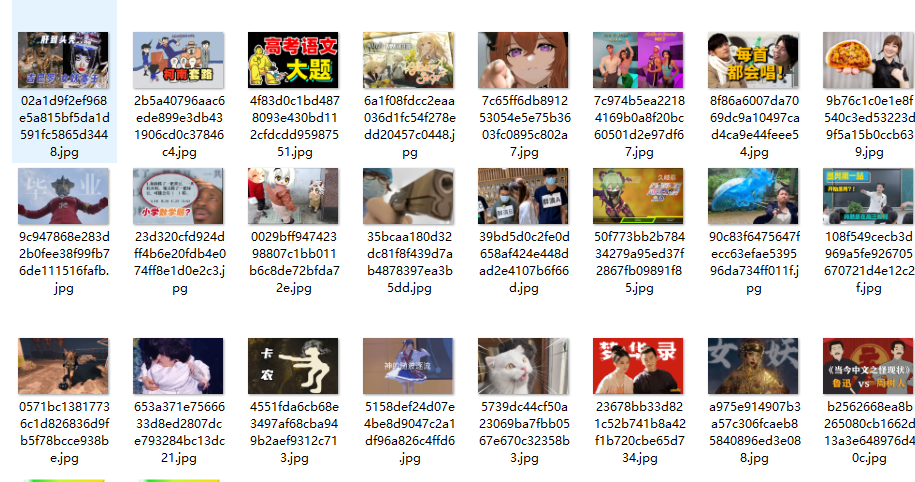
完整代码:
import requests
import pprint url = 'https://api.bilibili.com/x/web-interface/popular/series/one?number=168'
response = requests.get(url=url)
data = response.json()
#pprint.pprint(data) #将页面内容规范为易懂可视页面
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
print([pic,title]) imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
【python爬虫】bilibili每周必看页面视频图片爬取的更多相关文章
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- Python爬虫入门教程 25-100 知乎文章图片爬取器之一
1. 知乎文章图片写在前面 今天开始尝试爬取一下知乎,看一下这个网站都有什么好玩的内容可以爬取到,可能断断续续会写几篇文章,今天首先爬取最简单的,单一文章的所有回答,爬取这个没有什么难度. 找到我们要 ...
- Python爬虫实战(一) 使用urllib库爬取拉勾网数据
本笔记写于2020年2月4日.Python版本为3.7.4,编辑器是VS code 主要参考资料有: B站视频av44518113 Python官方文档 PS:如果笔记中有任何错误,欢迎在评论中指出, ...
- 小白学 Python 爬虫(16):urllib 实战之爬取妹子图
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫入门教程 12-100 半次元COS图爬取
半次元COS图爬取-写在前面 今天在浏览网站的时候,忽然一个莫名的链接指引着我跳转到了半次元网站 https://bcy.net/ 打开之后,发现也没有什么有意思的内容,职业的敏感让我瞬间联想到了 c ...
- Python爬虫入门教程 3-100 美空网数据爬取
美空网数据----简介 从今天开始,我们尝试用2篇博客的内容量,搞定一个网站叫做"美空网"网址为:http://www.moko.cc/, 这个网站我分析了一下,我们要爬取的图片在 ...
- Python 爬虫入门(三)—— 寻找合适的爬取策略
写爬虫之前,首先要明确爬取的数据.然后,思考从哪些地方可以获取这些数据.下面以一个实际案例来说明,怎么寻找一个好的爬虫策略.(代码仅供学习交流,切勿用作商业或其他有害行为) 1).方式一:直接爬取网站 ...
- Python爬虫入门教程: All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
- Python爬虫入门教程: 半次元COS图爬取
半次元COS图爬取-写在前面 今天在浏览网站的时候,忽然一个莫名的链接指引着我跳转到了半次元网站 https://bcy.net/ 打开之后,发现也没有什么有意思的内容,职业的敏感让我瞬间联想到了 c ...
- python爬虫24 | 搞事情了,用 Appium 爬取你的微信朋友圈。
昨天小帅b看到一些事情不顺眼 有人偷换概念 忍不住就写了一篇反讽 996 的 看不下去了,我支持996,年轻人就该996! 没想到有些人看不懂 这就算了 还来骂我 早些时候关注我的小伙伴应该知道我第一 ...
随机推荐
- spring事件发布与监听
一.组成部分 spring的事件监听有三个部分组成,事件(ApplicationEvent).监听器(ApplicationListener)和事件发布操作. 二.具体实现 事件 事件对象就是一个简单 ...
- Pytorch-UNet-master>utils>data_loading.py
模块,包 在package_runoob同级目录下,用test.py调用package_runoob包中内容 参考链接: Python 模块 | 菜鸟教程 (runoob.com) Dataset ...
- 【Beat】Scrum Meeting 4
时间:2021年6月29日 1.各个成员今日完成的任务以及贡献小时数 姓名 今日完成任务 贡献小时数 鑫 继续进行bug的修改 4 荣娟 继续进行bug的修改 4 亚楠 继续进行bug的修改 4 桂婷 ...
- 密码破解-hashcat的简单使用
在我们抓取到系统的hash值之后,需要通过一些工具来破解密码 hashcat是一款可以基于显卡暴力破解密码的工具,几乎支持了所有常见的加密,并且支持各种姿势的密码搭配 在kali Linux中自带的有 ...
- Python批量采集百度资讯文章,如何自定义采集日期范围
01 引言 大家好!蜡笔小曦有个朋友是做能源相关工作的,她想要有一个工具以天为单位持续地采集百度资讯中能源相关的文章进行留存和使用. 其中有个需求点是说能够自定义采集的开始日期和结束日期,这样更加灵活 ...
- 数据库中1NF,2NF,3NF的判别
参照:https://blog.csdn.net/qq_28888837/article/details/98733448 1NF:每一个都是最原子化. 2NF:找到主键后,每一个非主键对主键都是完 ...
- ThreadPool实现机制
Android中阻塞队列的应用有哪些 阻塞队列在 Android 中有很多应用,比如: 线程池:线程池任务的执行就是基于一个阻塞队列,如果线程池任务已满,则任务需要等待阻塞队列中的其他任务完成. Ha ...
- Spring Data Solr 对 Solr 的增删改查实例
Spring Data Solr 就是为了方便 solr 的开发研制的一个框架,其底层是对 SolrJ(官方 API)的封装 一.环境搭建 第一步:创建 Maven 项目(springdatasolr ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-信息智能提取从0到1快速入门——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- 2.@Param()注解
前言 在咋们的mapper层中,@Param()注解是很常见的,它是专门服务于SQL相关联的mapper接口,它有两个功能:1)多参数传值,2)取别名,替换传值 1.取别名,替换传值 1.1 代码演示 ...