京东APP百亿级商品与车关系数据检索实践
导读
本文主要讲解了京东百亿级商品车型适配数据存储结构设计以及怎样实现适配接口的高性能查询。通过京东百亿级数据缓存架构设计实践案例,简单剖析了jimdb的位图(bitmap)函数和lua脚本应用在高性能场景。希望通过本文,读者可以对缓存的内部结构知识有一定了解,并且能够以最小的内存使用代价将位图(bitmap)灵活应用到各个高性能实际场景。
1.背景
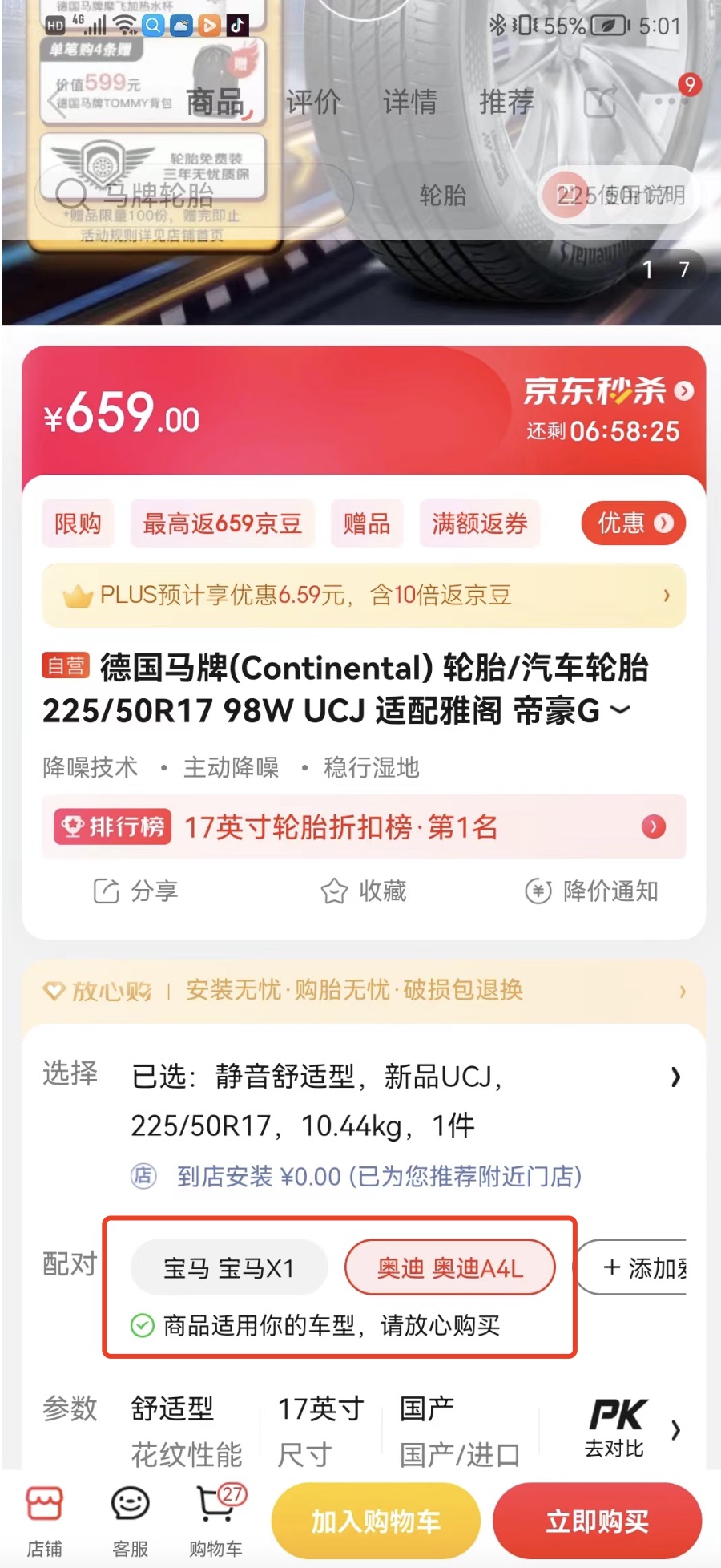
整个汽车行业行特殊性,对于零配件有一个很强的对口特性,不同车使用的零配件(例如:轮胎、机油、三滤、雨刮、火花塞等)规格型号不一样。在售卖汽车零配件的时候,不能像3C家电、服饰,需要结合用户具体车辆信息,推荐适合的配件商品。基于此原因,京东自建人车档案模型并且利用算法清洗出百亿级的车型-零配件的适配关系数据,最终形成“人->车-〉货”关系链路,解决“人不识货”的问题。 具体使用场景如下图:
.
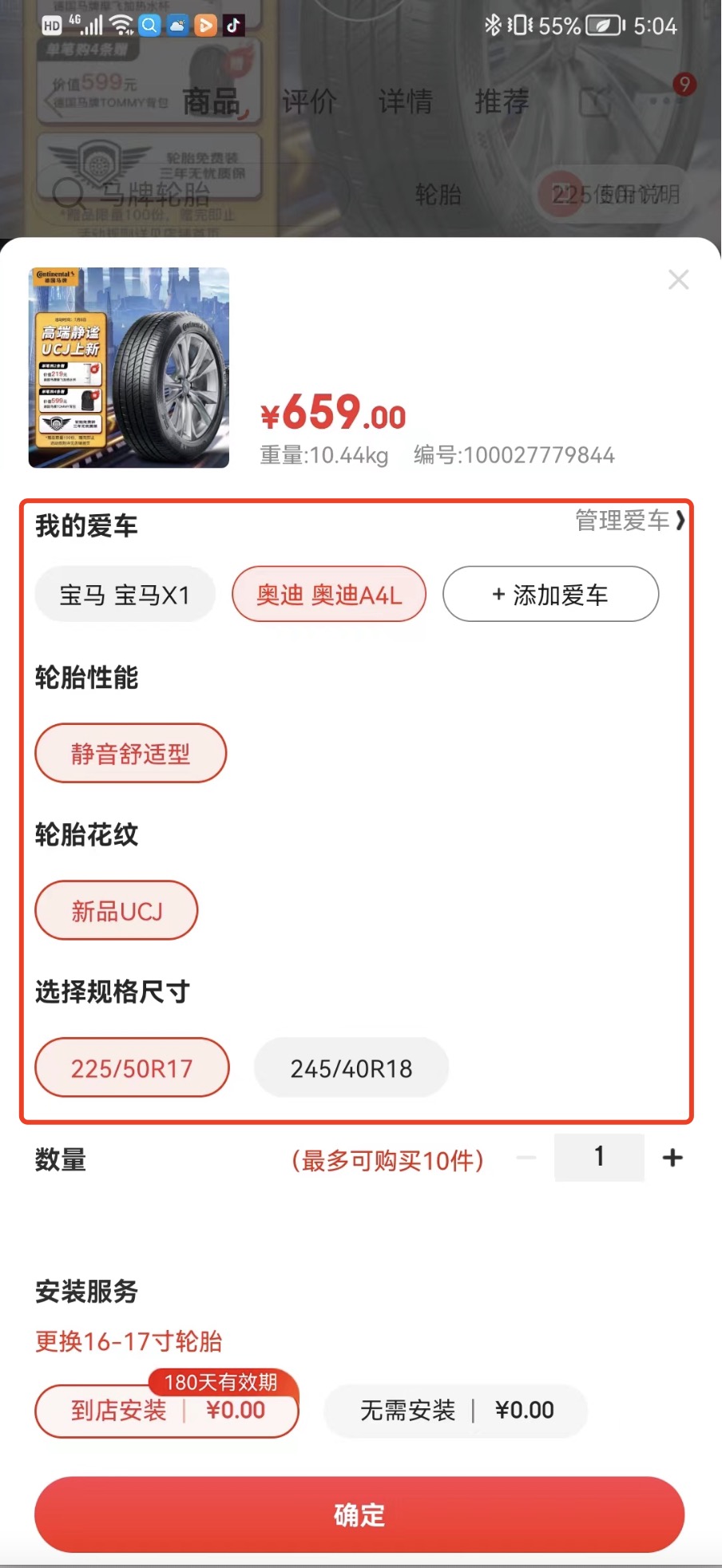
图1.1京东商详推荐商品 图1.2京东加购弹窗推荐商品
2.数据模型
“人-> 车->货”关系的核心链路是由人(京东用户)、乘用车和SKU这三部分组成。
首先,用户在京东APP的商搜页、商详页多个位置都可以选择自己的车型信息进行绑定(例如:图2.1,京东商详绑车入口位置“+添加爱车”按钮),建立“人车档案”数据。
.
图2.1.京东商详绑车入口位置 图2.2.京东商搜绑车入口位置
其次,运营在后台管理系统中将商品与车型进行绑定,建立“商品与车型关系”数据(商品与车型的关系数据量级在百亿级别)。
最终,购买商品的时候,京东推荐系统可以通过用户自己绑定的车型推荐出适合该车型的商品。具体商品适配车型数据模型,见图2.3。
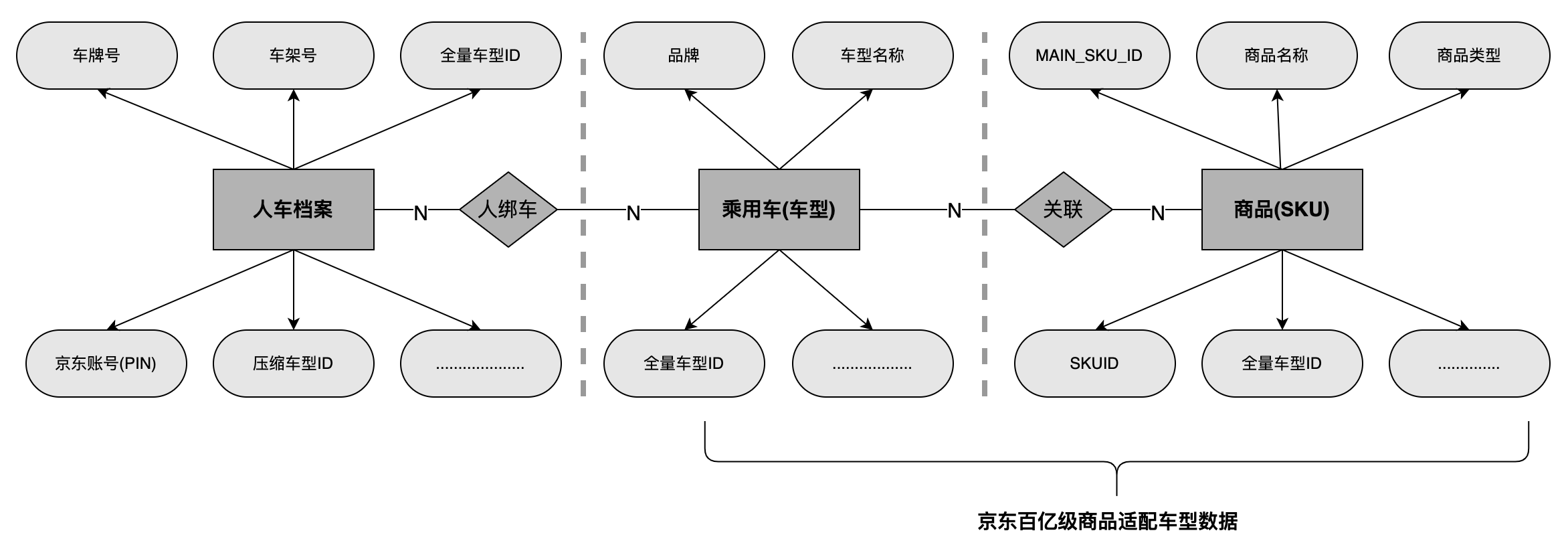
图2.3京东商品适配车型数据模型
3.缓存结构设计
基于前面两个部分的介绍,我们可以了解到整个商品搜索适配推荐存在两个最核心问题。第一、百亿级商品适配车型数据的存储结构设计,尽可能的占用资源成本最小;第二、商详通过用户车型来搜索适配商品时,必须保证接口性能的TP99位于毫秒级。最终技术选型的时候,采用了jimdb的位图(bitmap)函数来进行数据存储。
3.1位图(bitmap)结构
位图(bitmap)是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个bit的值是0或者1;也就是说一个bit能存储的最多信息是2。
• 位(bit):计算机内部数据存储的最小单位,例如:11001100是一个八位二进制数。
• 字节(byte):计算机中数据处理的基本单位,习惯上用大写B来表示,1B(byte,字节)=8bit。
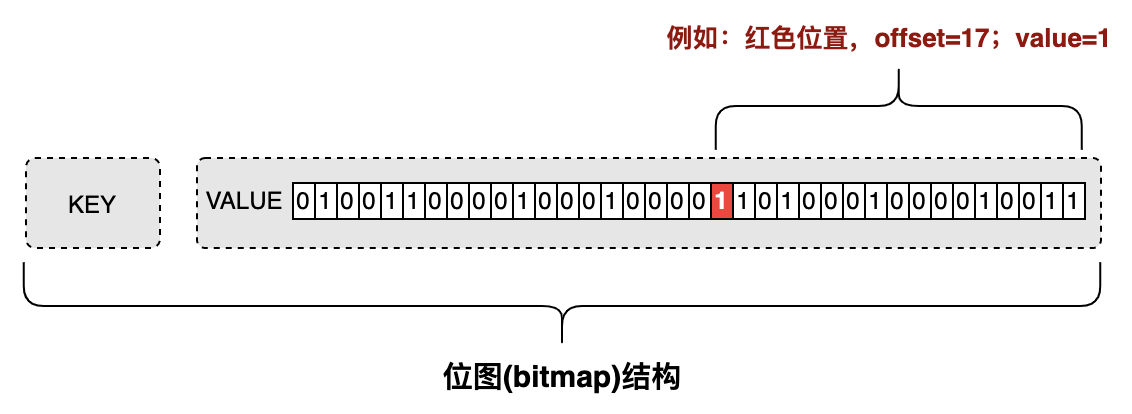
图3.1位图(bitmap)内部结构
3.2位图(bitmap)数据写流程
位图(bitmap)是基于jimdb的SDS(简单动态字符串)类型的一系列位操作,遵循jimdb的SDS特性,例如:位图(bitmap)最大长度512M,最大可以存储232位。以下是“big”字符串的SDS结构示例:
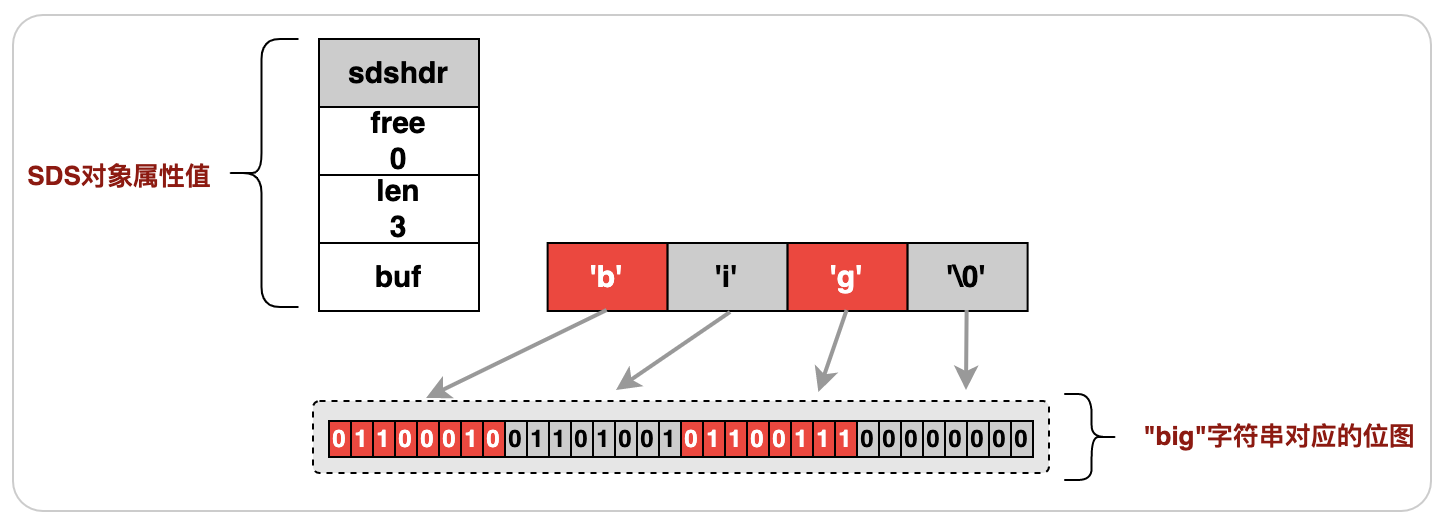
图3.2.1“big”字符串的SDS结构
SDS(简单动态字符串)为了保证性能采用了空间预分配的策略:空间预分配用于优化SDS的字符串增长操作。SDS的API对一个SDS进行修改并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空。具体预分配流程图如下:
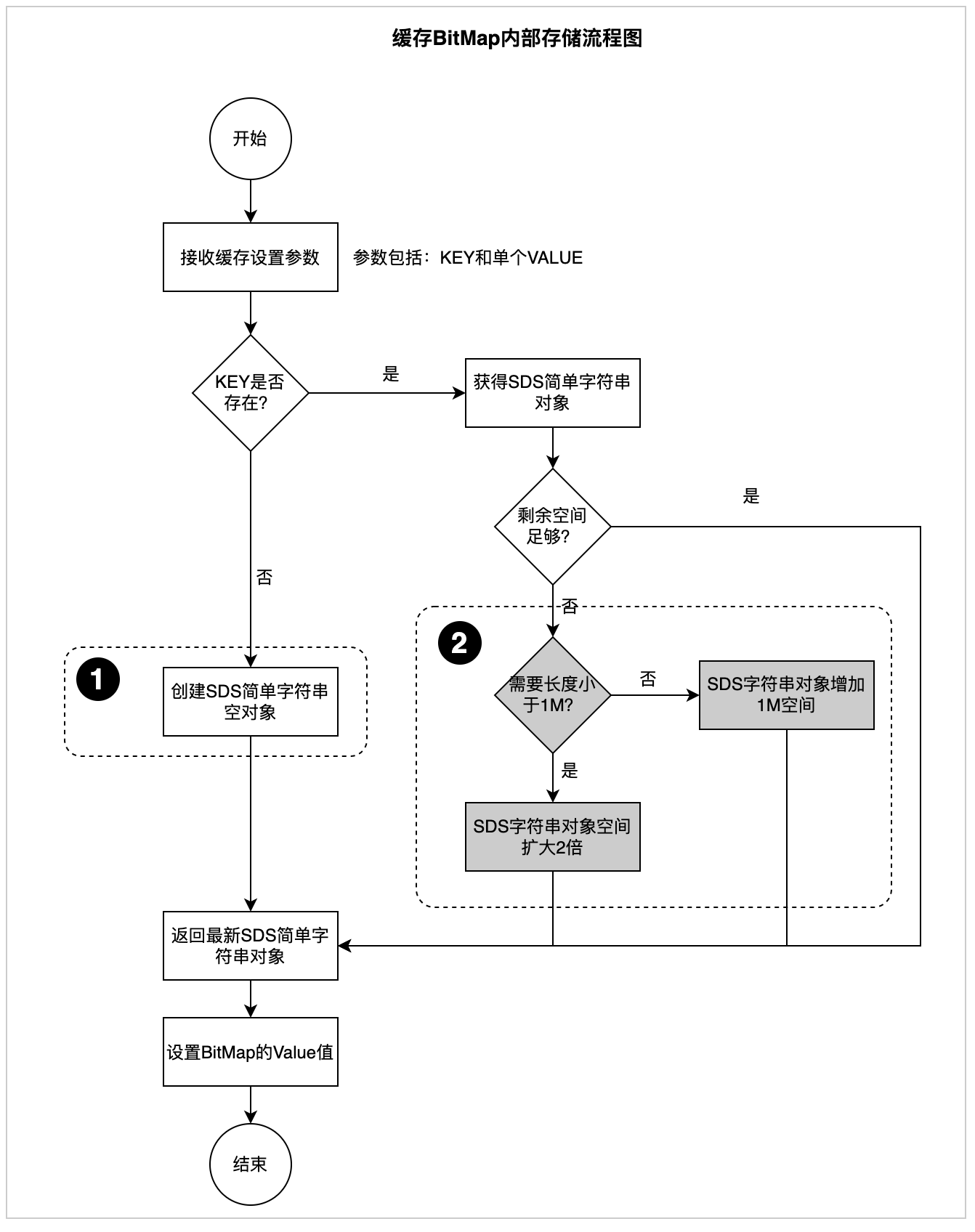
图3.2.2SDS预分配流程图
位置1:创建SDS简单字符串预分配空间为:偏移量/8+1。
位置2:剩余空间不足时,预分配空间流程。
3.3压缩商品与车关系缓存
| 偏移量(自增ID) | 全量车型 | 商品SKU |
|---|---|---|
| 1 | 1165788 | 101362 |
| 2 | 1165793 | 101362 |
商品适配车型关系(百亿级数据量)
商品与车关系缓存存储过程中,采用了商品SKU作为KEY,全量车型ID的偏移量(采用偏移量是为降低内存消耗)作为VALUE值来进行存储。
全量车型ID大约有几十万的数据量,极限情况下一个商品SKU可以适配几十万辆车,很容易造成缓存大KEY的问题,为此我们进行了偏移量(全量车型ID对应的自增ID)的分段处理。具体是按照:SKU作为缓存KEY的基础上,追加一个分段标记数字作为新KEY,每个偏移量都会按照分段范围对应一个分段标记数字。例如:偏移量1~50000,对应缓存KEY为SKU+0;偏移量50001~100000,对应缓存KEY为SKU+1,其它偏移量以此类推,这样就保证了一个SKU即使适配所有车辆也不会出现缓存大KEY的情况。
BitMap缓存结构底层使用SDS简单字符串,为了保证性能采用了预分配空间的策略(图3.2.2,“缓存BitMap内部存储流程图”的“位置2”中虚线框圈选),这样在缓存商品与车关系的时候浪费了大量的缓存空间。为此我们调整了偏移量存储顺序,首先获取到需要缓存的车型内最大的偏移量,保证同一个缓存KEY第1次创建SDS简单字符串(图3.2.2,“缓存BitMap内部存储流程图”的“位置1”中虚线框圈选)后,不再进行第2次空间扩容,这样来最大限度的提升缓存利用率,起到压缩空间目的。缓存数据关系流程如下:
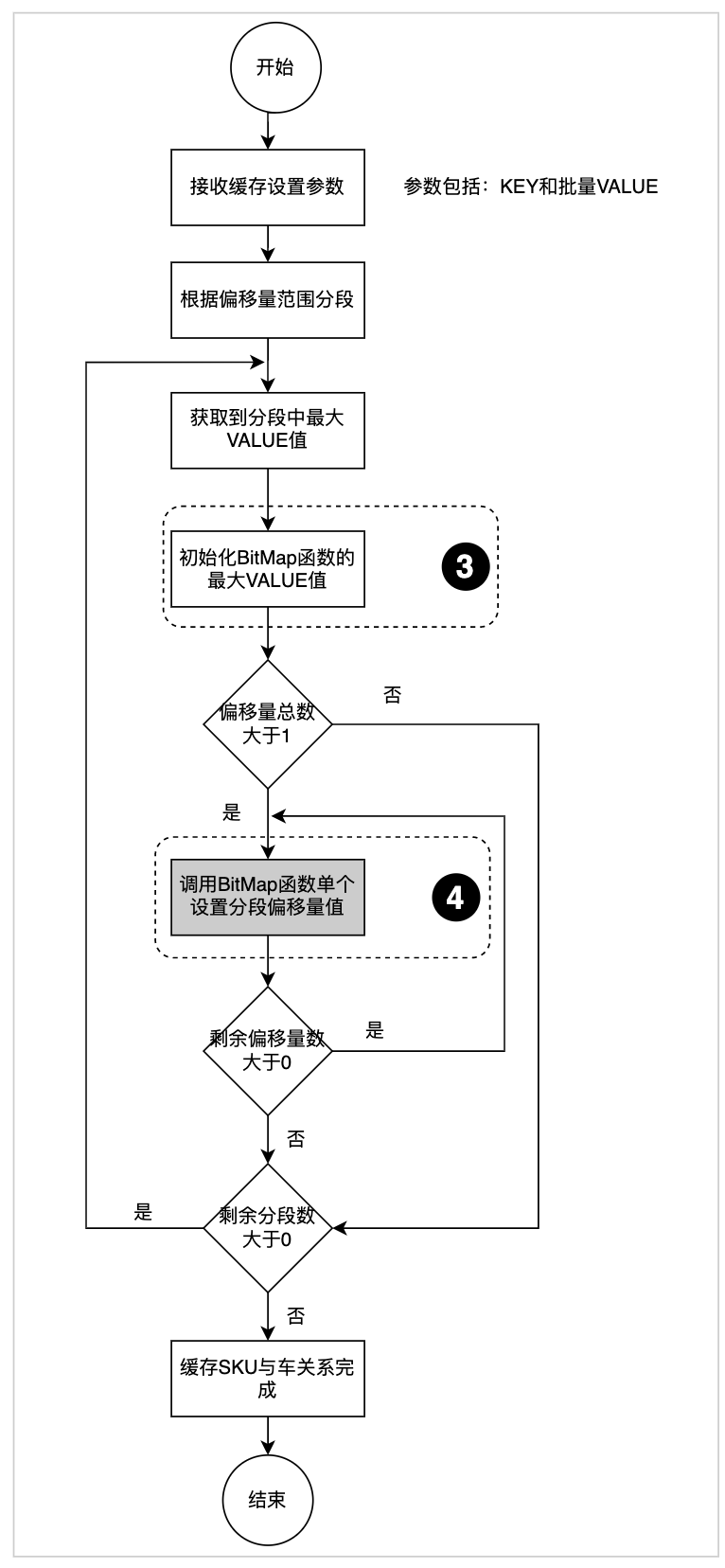
图3.3.1缓存数据关系流程
位置3:设置分段最大的偏移量,保证后续新增偏移量不再扩容空间。
位置4:设置分段较小的偏移量。
全量车型ID是定长7位的数字,如果用它作为偏移量将消耗内存巨大,所以采用对应自增ID作为偏移量。最终在bitmap缓存的商品SKU与车的适配关系缓存结构如下图:
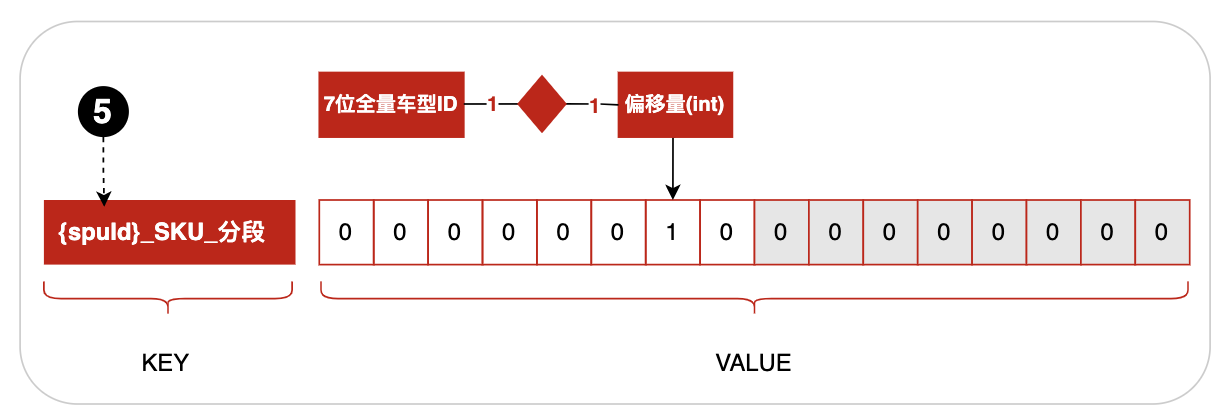
3.3.2商品与车缓存结构图
位置5:spuId用{}括起来表示缓存路由(Lua脚本中同一次请求,数据必须在缓存同一个分片上,否则会丢失数据)。POP商品spuId是SKU的产品ID,自营商品spuId是SKU的MainSkuId。
备注:
1、自营商品MainSkuId可能发生变化,所以我们接入了商品变化MQ消息,实时调整SKU与车适配关系的存储位置。
2、京东商详页面中每个不同的规格/型号分别对应不同的SKU,但是它们都对应同一个SpuId或者MainSkuId。
4.缓存架构设计
商品与车的关系数据量每天都在不断增长,要求缓存架构设计,需要支持集群横向/纵向扩容和来满足业务发展以及高可用性。整个缓存架构体系主要有前端、京东养车商品与车关系层和存储三部分组成。
“商品与车关系缓存架构”层核心包括:1、“集群路由”层,实现了集群横向扩容,保证数据量增涨的时候,缓存容量也能跟上。2、“分片路由”层,保证搜索的底层数据的分片相同,避免数据丢失。
“存储”层核心包括:1、实现了缓存压缩,参见3.3压缩商品与车关系缓存。2、单元化实现跨区域灾备,保障大促系统稳定性。具体商品与车关系缓存架构如下:
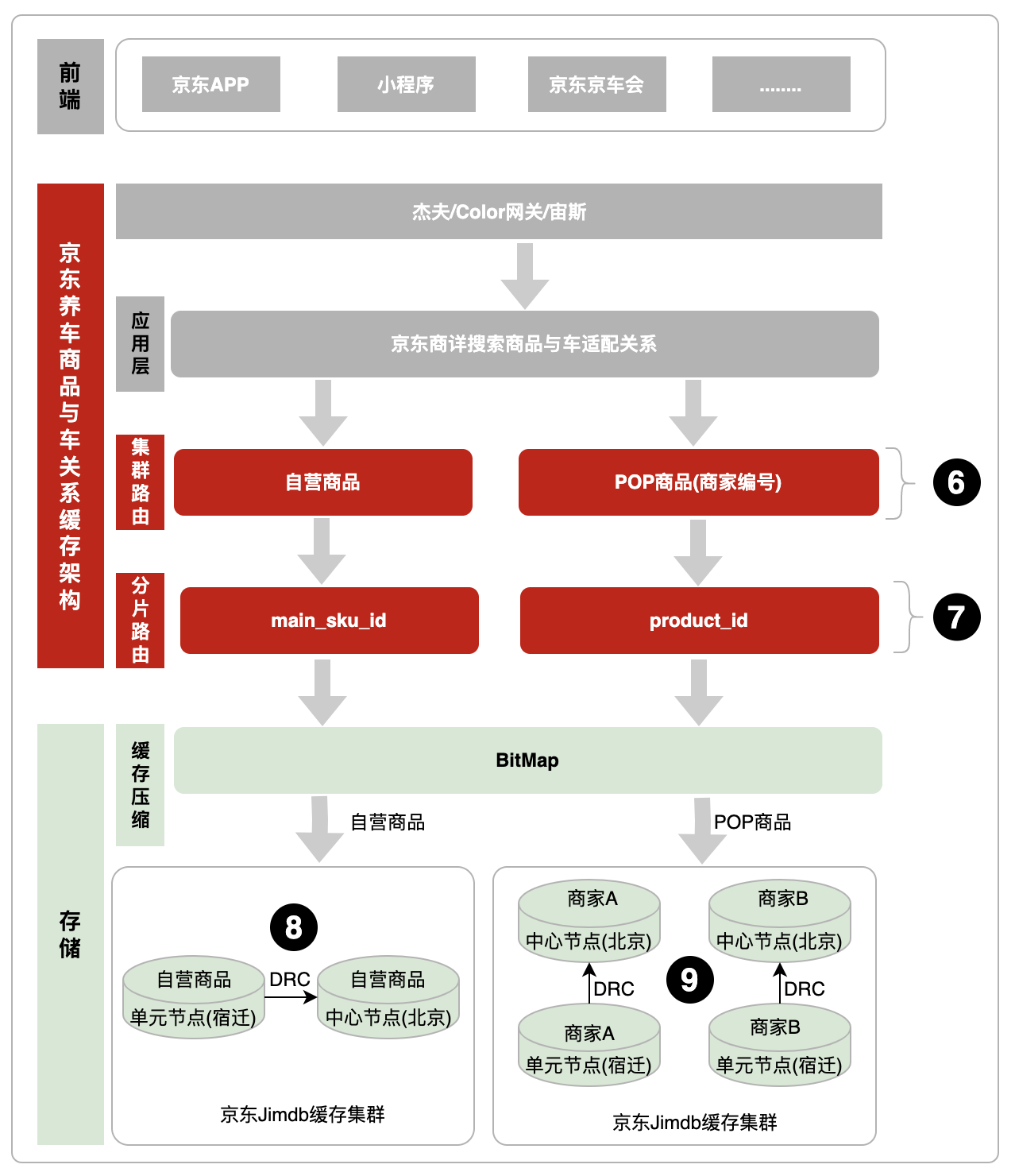
4.1商品与车关系缓存架构图
位置6:集群路由,通过商品类型或者商品编号(POP商品)路由到不同缓存集群,便于横向扩展,每个集群单分片限制,解决分片超过限制问题。
位置7:分片路由,保障Lua脚本搜索数据的底层数据集群分片相同,避免数据丢失。其中自营商品和POP商品的路由分别是main_sku_id和product_id。
位置8:自营商品缓存集群,单元化实现跨区域灾备,采用自研DRC(Data Replication Center)数据同步机制。
位置9:POP商品缓存集群,通过商家编号拆分为两个子集群。
5.高性能搜索
基于BitMap(位图)缓存的商品与车关系数据,商详调用接口的内部实现采用了Lua脚本来降低网络开销,保障整个接口的性能。以下是搜索接口的流程图:
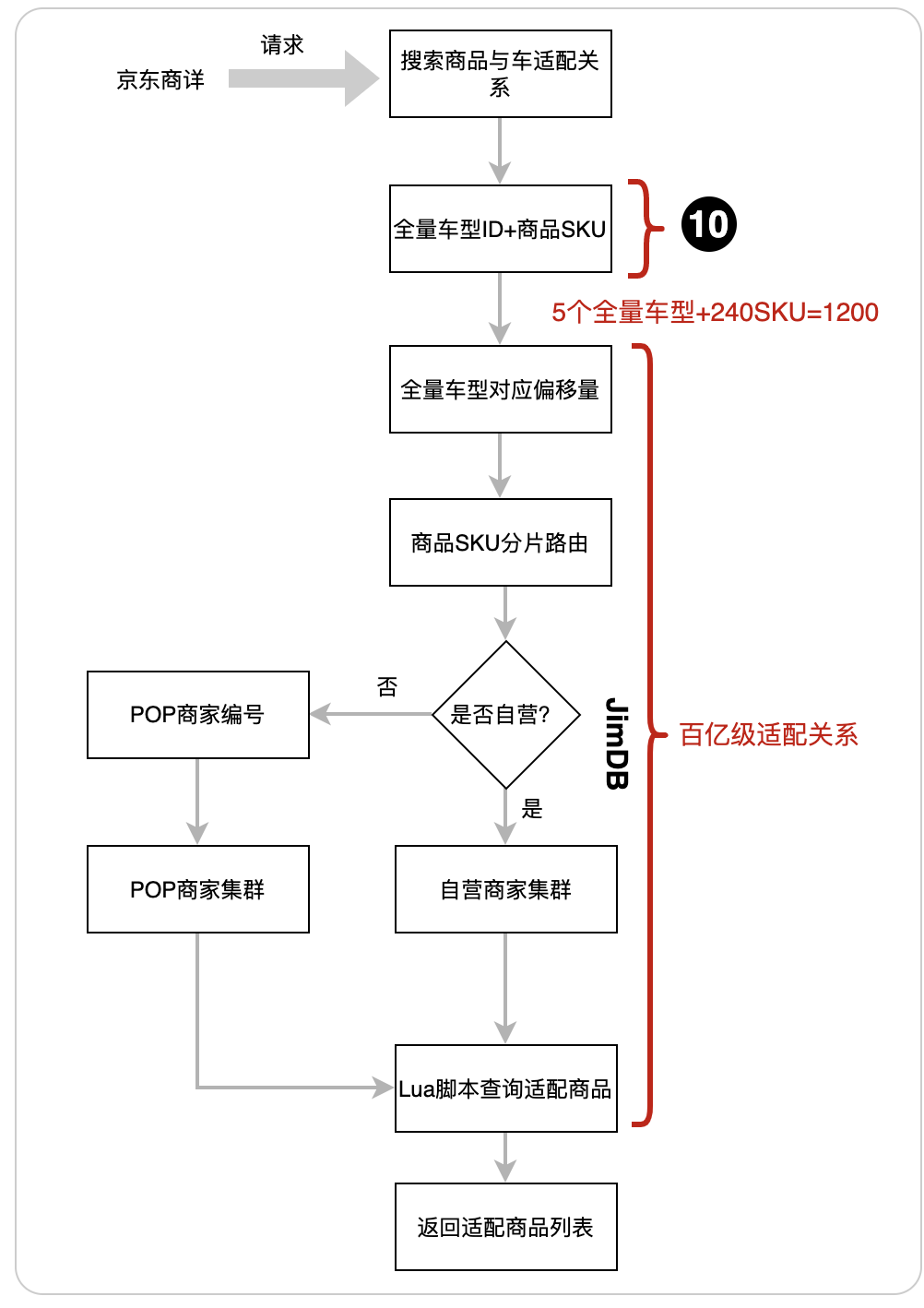
5.1商详搜索商品与车适配关系流程图
位置10:商详调用接口的时候,要传两个参数。第1个参数是全量车型ID列表,大约5个全量车型ID。第2个参数是商品SKU列表,SKU的数量极限超过200个。最后全量车型ID与商品SKU组合为上千个商品与车的关系后,再到百亿级适配关系去搜索看是否匹配的。如果不匹配返回适配商品,反之则返回不适配。
Lua脚本减少了应用服务器与缓存服务器的交互,降低了网络开销的时间,达到提升搜索服务的性能。以下是Lua脚本具体代码:

5.2商详搜索商品与车适配关系Lua代码
基于以上缓存设计和Lua脚本的使用,整个接口T999小于13ms。具体的接口性能监控如下图:
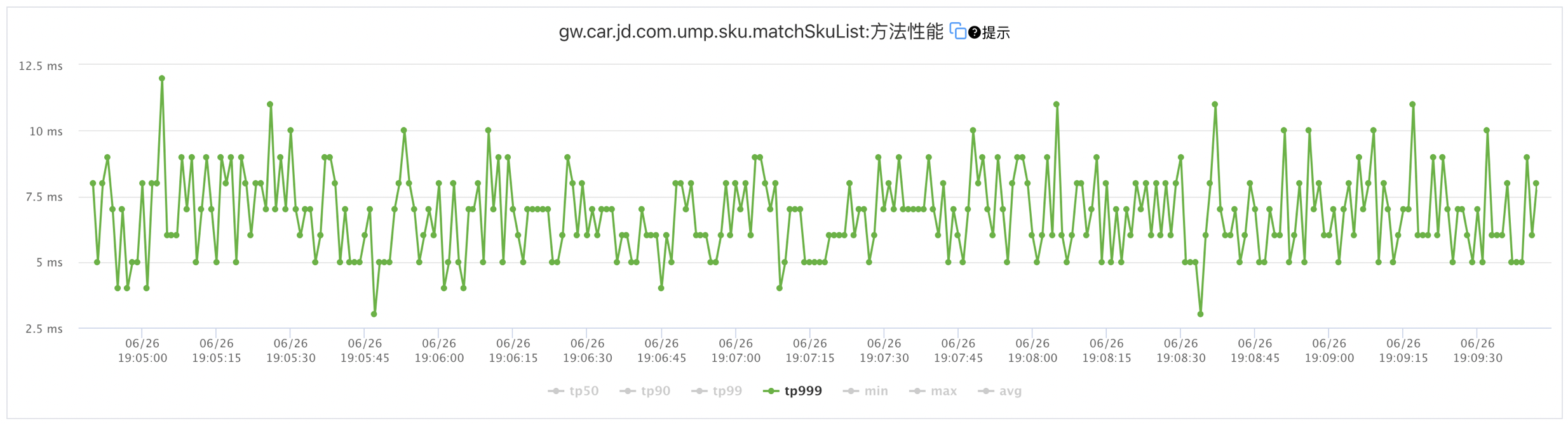
5.3商详搜索商品与车适配关系接口性能
6.总结
整个缓存结构设计的时候,使用BitMap(位图)来存储数据。解析SDS的内部存储流程,通过存储流程机制避开预分配空间节点,最大限度的利用缓存空间,避免资源浪费。采用Lua脚本来实现数据的适配搜索,降低网络开销,进一步提升接口的性能。希望此文对大家后续设计类似场景有一定的帮助和启发。
作者:京东零售 张强
内容来源:京东云开发者社区
京东APP百亿级商品与车关系数据检索实践的更多相关文章
- cassandra百亿级数据库迁移实践
迁移背景 cassandra集群隔段时间出现rt飙高的问题,带来的影响就是请求cassandra短时间内出现大量超时,这个问题发生已经达到了平均两周一次的频率,已经影响到正常业务了.而出现这些问题的原 ...
- 百亿级小文件存储,JuiceFS 在自动驾驶行业的最佳实践
自动驾驶是最近几年的热门领域,专注于自动驾驶技术的创业公司.新造车企业.传统车厂都在这个领域投入了大量的资源,推动着 L4.L5 级别自动驾驶体验能尽早进入我们的日常生活. 自动驾驶技术实现的核心环节 ...
- Redis百亿级Key存储方案(转)
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- Redis百亿级Key存储方案
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- 支撑百亿级应用的 NewSQL
支撑百亿级应用的 NewSQL https://zhuanlan.zhihu.com/newsql/ 项目背景 初次接触 TiDB,是通过同程网首席架构师王晓波先生的分享,当时同程网正在使开发和数据库 ...
- [NewLife.XCode]分表分库(百亿级大数据存储)
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量 ...
- [NewLife.XCode]百亿级性能
NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和 ...
- 转:亿级Web系统的高容错性实践(好博文)
亿级Web系统的高容错性实践 亿级Web系统的高容错性实践 背景介绍 大概三年前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,当时,作为开发的我,7*24小时地没 ...
- 亿级Web系统的高容错性实践
亿级Web系统的高容错性实践 背景介绍 大概三年前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,当时,作为开发的我,7*24小时地没日没夜处理告警,周末和凌晨也经 ...
- 【转】百亿级实时大数据分析项目,为什么不用Hadoop?
百亿数量级的大数据项目,软硬件总体预算只有30万左右,需求是进行复杂分析查询,性能要求多数分析请求达到秒级响应. 遇到这样的项目需求,预算不多的情况,似乎只能考虑基于Hadoop来实施. ...
随机推荐
- Vue 的下拉刷新指令
loadmore: { //自定义指令: 下拉加载 bind(el, binding) { let p = 0; let t = 0; let down = true; el.addEventList ...
- python之自动化连连看脚本-第二关下移-小记
(如想转载,请联系博主或贴上本博地址) 参考前一篇基础上,做出第二关下移逻辑判断,写的比较啰嗦. 下移和第一关不动基础代码是一样的.需要注意同列下移和不同列下移2种情况,同列下移需要注意相邻的2个和不 ...
- [ABC284F] ABCBAC(字符串哈希)
思路 这里我们要注意以下几点: 字符串哈希自然溢出(\(\pmod 2^64\))会被卡,会\(WA~5\)个点 注意有模数的时候不要用\(unsigned\ long \ long\)类型 代码 # ...
- 微信小程序中如何识别银行卡和身份证
识别银行卡云函数card2/index.js: const cloud = require('wx-server-sdk') cloud.init({ env: cloud.DYNAMIC_CURRE ...
- 201971010110-高杨 实验三 结对项目—《{0-1}KP 实例数据集算法实验平台》项目报告
项目内容 项目 内容 班级博客链接 https://edu.cnblogs.com/campus/xbsf/2019nwnucs 作业要求 https://edu.cnblogs.com/campus ...
- idea中执行“npm/yarn”命令,提示'node/yarn' 不是内部或外部命令,也不是可运行的程序
问题:idea中执行"npm/yarn"命令,提示'node/yarn' 不是内部或外部命令,也不是可运行的程序.但是在本地打开cmd 是可以运行npm/yarn命令的 解决方法: ...
- 帝国CMS安全方案
一.帝国CMS介绍 帝国CMS是一款主流的网站内容管理系统,因其系统结构科学合理,功能强大,操作简单,拥有海量用户.和其他CMS一样,安全漏洞也是其无法避免的问题.虽然官方不断发布补丁.升级版本,但安 ...
- Java8 lambda常用操作
参考博客:https://www.cnblogs.com/hmy-1365/p/12923435.html
- 小白都能看懂得Xxl-job安装教程
大家好,我是咔咔 不期速成,日拱一卒 一.背景 在平时的业务场景中,经常有一些场景需要使用定时任务,比如: 某个时间点发送优惠券 发送短信等等. 批量处理数据:批量统计上个月的账单,统计上个月销售数据 ...
- 2019徐州网络赛 M Longest subsequence 序列自动机
题目链接https://nanti.jisuanke.com/t/41395 题意:给两个字符串,s和t,在s中求字典序严格大于t的最长子序列. 思路:分类讨论即可.先建个s的序列自动机. 1 如果有 ...