大数据技术之HBase原理与实战归纳分享-上
@
概述
定义
HBase 官网地址 https://hbase.apache.org/
HBase 官网文档 https://hbase.apache.org/book.html
HBase GitHub源码地址 https://github.com/apache/hbase
Apache HBase是以HDFS为数据存储分布式的、可伸缩的Hadoop NoSQL数据库。最新版本为2.5.0
HBase支持对大数据进行随机、实时的读写访问,可以在商用硬件集群上托管非常大的表——数十亿行X数百万列。Apache HBase是一个开源的、分布式的、版本化的、非关系数据库,模仿了谷歌开发的Bigtable结构化数据的分布式存储系统,与Bigtable利用了谷歌文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS的基础上提供了类似Bigtable的功能。
特点
- 可扩展性。
- 读写严格一致。
- 自动和可配置的表分片。
- regionserver之间的自动故障转移支持。
- 使用Apache HBase表支持Hadoop MapReduce作业。
- 易于使用Java API进行客户端访问。
- 块缓存和Bloom过滤器用于实时查询。
- 通过服务器端过滤器下推查询谓词。
- Thrift网关和一个支持XML、Protobuf和二进制数据编码选项的rest Web服务。
- 可扩展的基于jruby (JIRB)的shell。
- 支持通过Hadoop指标子模块导出指标。
数据模型
概述
- HBase的设计理念依据Coogle 的BigTable论文,论文中说到Bigtable 是一个稀疏的,分布式的,持久的多维排序map。
- 映射由行键,列键和时间戳索引;映射中的每一个值都是一个未解释的字节数组。
- HBase数据模型和BigTable的对应关系如下
- HBase 使用于 BigTable非常相似的数据模型,用户将数据行存储在带标签的表中,数据行具有可排序的键和任意数量的列。
- 该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列
HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map 指代非关系型数据库的 key-Value 结构。
逻辑结构
HBase 可以用于存储多种结构的数据,以 JSON 为例:
{
"row_key1":{
"personal_info":{
"name":"zhangsan",
"city":"北京",
"phone":"131********"
},
"office_info":{
"tel":"010-1111111",
"address":"atguigu"
}
},
"row_key11":{
"personal_info":{
"city":"上海",
"phone":"132********"
},
"office_info":{
"tel":"010-1111111"
}
},
"row_key2":{
......
}
逻辑结构存储数据稀疏,数据存储多维,不同的行具有不同的列。数据存储整体有序,按照RowKey的字典序排列,RowKey为Byte数组,示例如下:
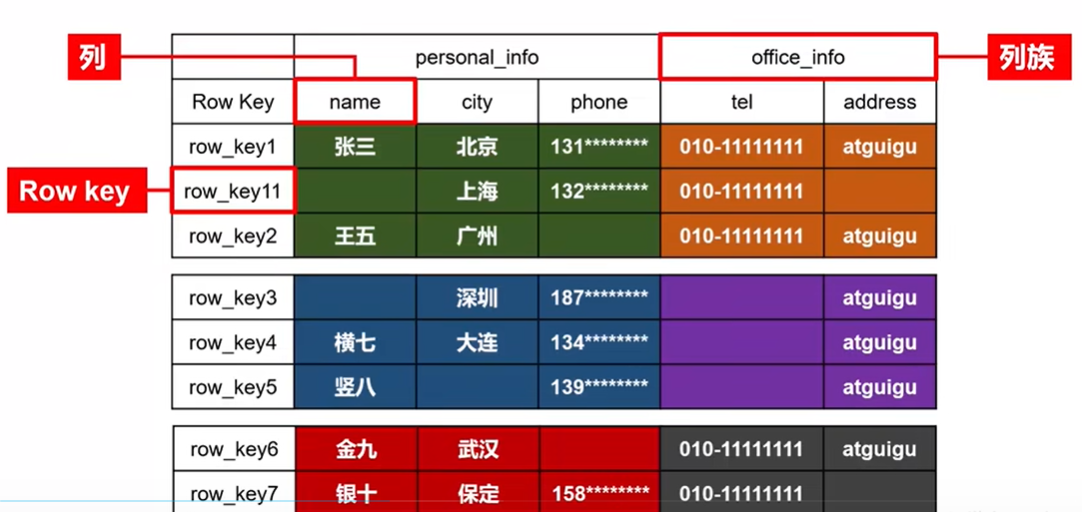
物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不储存。
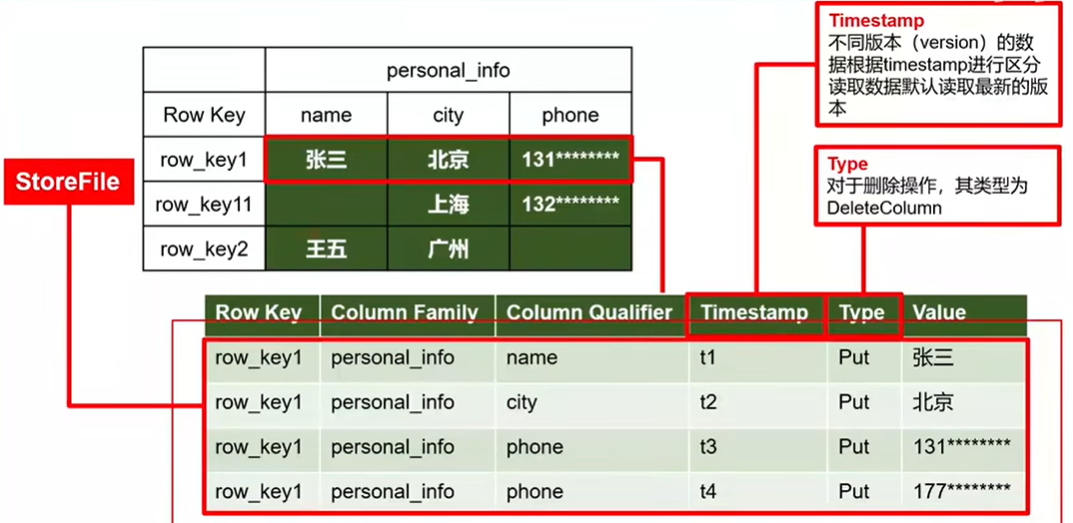
数据模型
- Name Space:命名空间,类似于关系型数据库的 database 概念,每个命名空间下有多个表。HBase 两个自带的命名空间,分别是 hbase 和default,hbase 中存放的是 HBase 内置的表,default表是用户默认使用的命名空间。
- Table:类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需指定。因此和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
- Row:HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
- Column:HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
- Time Stamp:用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段, 其值为写入 HBase 的时间。
- Cell:由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数据全部是字节码形式存储。
应用场景
- 对象存储:比如一些app的海量的图片、网页、新闻等对象,可以存储在HBase中,有些病毒公司的病毒库也可以存储在HBase中。
- 时空数据:主要是轨迹、气象网格之类
- 比如滴滴打车的轨迹数据主要存在HBase之中。
- 另外大数据量的车联网企业,数据也都是存在HBase中。
- 比如互联网出行,智慧物流与外卖递送,传感网与实时GIS等场景。
- 时序数据:时序数据就是分布在时间上的一系列数值。
- HBase之上有OpenTSDB模块,可以满足时序类场景的需求。
- 比如我们有很多的设备、传感器,产生很多数据,如果规模不是特别大的厂家有几千个风机,每个风机有几百个指标,那么就会有一百万左右的时序数据,如果用采样每一秒会产生一百万个时间点,如果用传统数据库,那么每一秒会产生一百万次,持续地往MQ做一百万次,它会崩裂。并且查询也是个大问题,除了多维查询以外,我们还会额外地增加时间纬度,查看一段时间的数据。这时候HBase很好了满足了时序类场景的需求。
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase上。用户画像有用户数据量大,用户标签多,标签统计维度不确定等特点,适合HBase特性的发挥。
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上。
- Feed流:是RSS中用来接收该信息来源更新的接口,简单的说就是持续更新并呈现给用户的内容。比如微信朋友圈中看到的好友的一条条状态,微博看到的你关注的人更新的内容,App收到的一篇篇新文章的推送,都算是feed流。
- NewSQL:HBase上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。从NoSQL到NewSQL,Phoenix或许是新的趋势。
基础架构
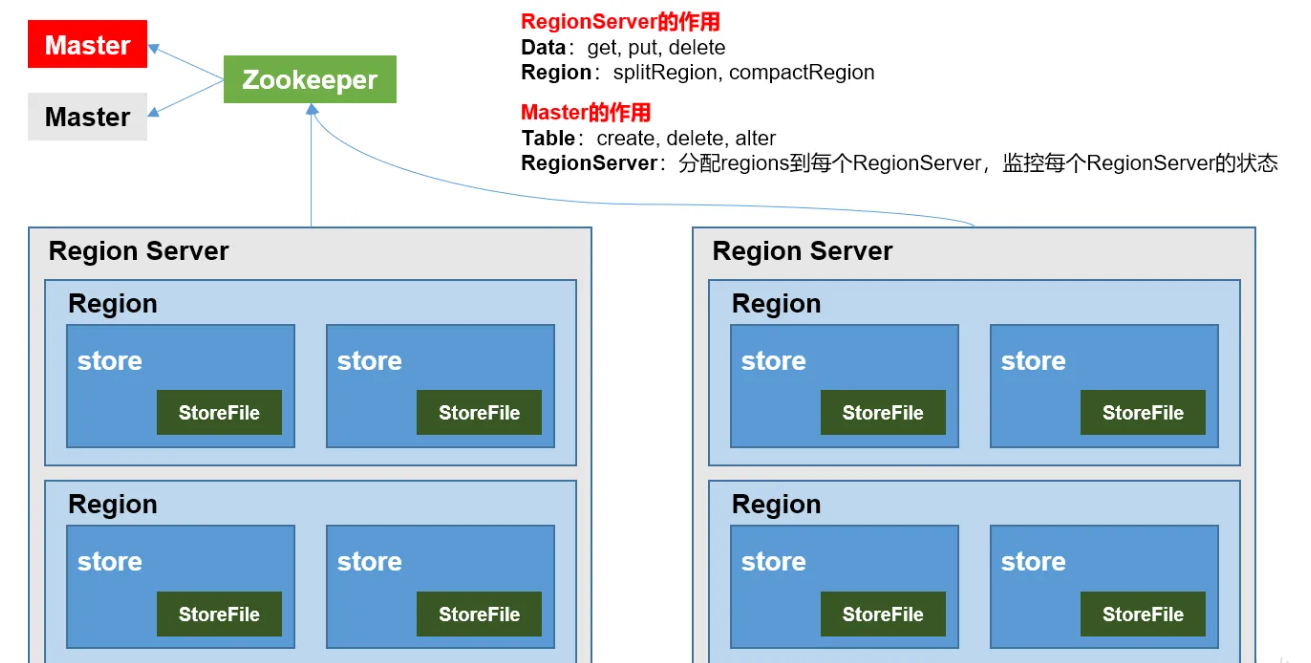
组成角色包含如下几个部分:
- Master:实现类为 HMaster,负责监控集群中所有的 RegionServer 实例。
- 主要作用如下:
- 管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行
- 监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
- 管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行。
- 监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
- 通过启动多个后台线程监控实现上述功能:
- LoadBalancer 负载均衡器:周期性监控 region 分布在 regionServer 上面是否均衡,由参数 hbase.balancer.period 控 制周期时间,默认 5 分钟。
- CatalogJanitor 元数据管理器:定期检查和清理 hbase:meta 中的数据。meta 表内容在进阶介绍。
- MasterProcWAL master 预写日志处理器:把 master 需要执行的任务记录到预写日志 WAL 中,如果 master 宕机,让 backupMaster 读取日志继续干。
- 主要作用如下:
- Region Server:Region Server 实现类为 HRegionServer,主要作用如下:
- 负责数据 cell 的处理,例如写入数据 put,查询数据 get 等。
- 拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
- Zookeeper:HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储 有 meta 表的位置信息。 HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper 的压力。
- HDFS:HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
安装
前置条件
- Zookeeper(使用前面文章已部署集群)
- HDFS(使用前面文章已部署集群)
部署
# 下载最新版本HBase
wget --no-check-certificate https://dlcdn.apache.org/hbase/2.5.0/hbase-2.5.0-bin.tar.gz
# 解压
tar -xvf hbase-2.5.0-bin.tar.gz
# 进入目录
cd hbase-2.5.0
# 配置环境变量
vim /etc/profile
export HBASE_HOME=/home/commons/hbase-2.5.0
export PATH=$HBASE_HOME/bin:$PATH
# 将配置文件分发到另外两台节点上
scp /etc/profile hadoop2:/etc/
scp /etc/profile hadoop3:/etc/
# 在三台上执行环境变量生成命令
source /etc/profile
# 修改conf目录下配置文件hbase-env.sh,
vim conf/hbase-env.sh
# false 取消 不需要自己管理实例 用zookeeper
export HBASE_MANAGES_ZK=false
# 声明JAVA_HOME
export JAVA_HOME=/home/commons/jdk8
# HBase的jar包和Hadoop的jar包有冲突,导致服务没有起来,报错如object is not an instance of declaring class可以配置这个
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
- 修改conf目录下配置文件vim conf/hbase-site.xml
##修改,
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
##去掉
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
##增加
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop2:9000/hbase</value>
<!--8020这个端口号,要跟hadoop的NameNode一样-->
<description>The directory shared by RegionServers.
</description>
</property>
- 修改regionservers配置vim conf/regionservers
hadoop1
hadoop2
hadoop3
- 将Hadoop的配置文件core-site.xml和hdfs-site.xml拷贝到HBase的conf目录下
cp /home/commons/hadoop/etc/hadoop/core-site.xml conf/
cp /home/commons/hadoop/etc/hadoop/hdfs-site.xml conf/
- 分发HBase目录到其他两个节点上
scp -r /home/commons/hbase-2.5.0 hadoop2:/home/commons
scp -r /home/commons/hbase-2.5.0 hadoop3:/home/commons
启动服务
# 单点启动
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
# 群启
bin/start-hbase.sh
# 停止服务
bin/stop-hbase.sh
群启后查看服务进程
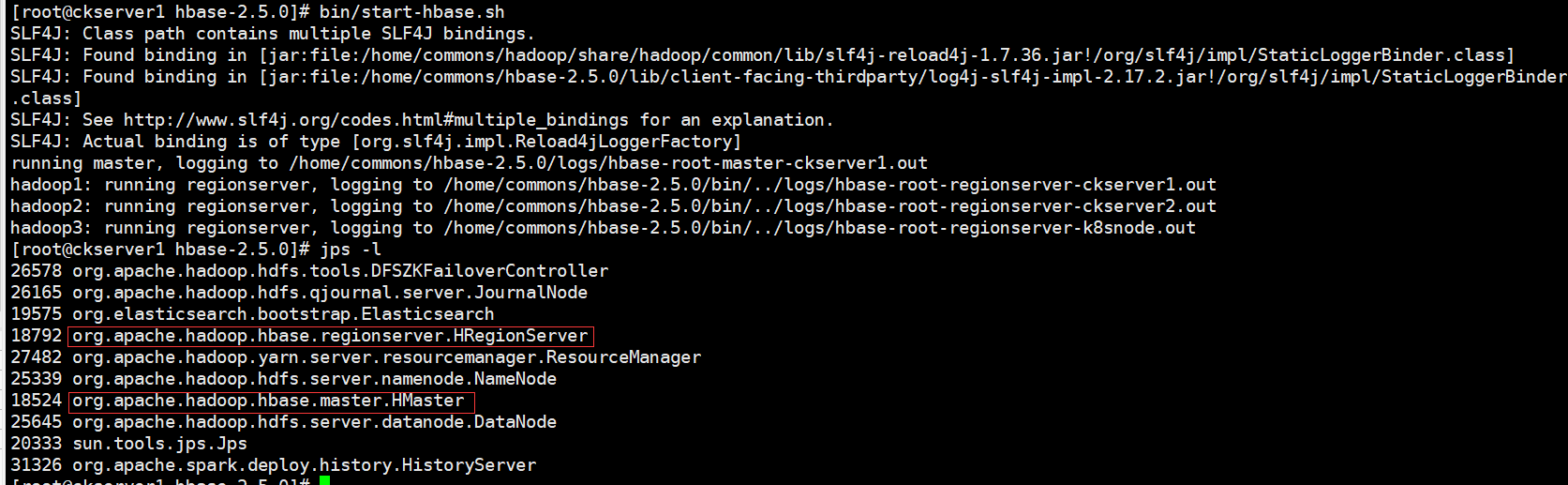
启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面, http://hadoop1:16010
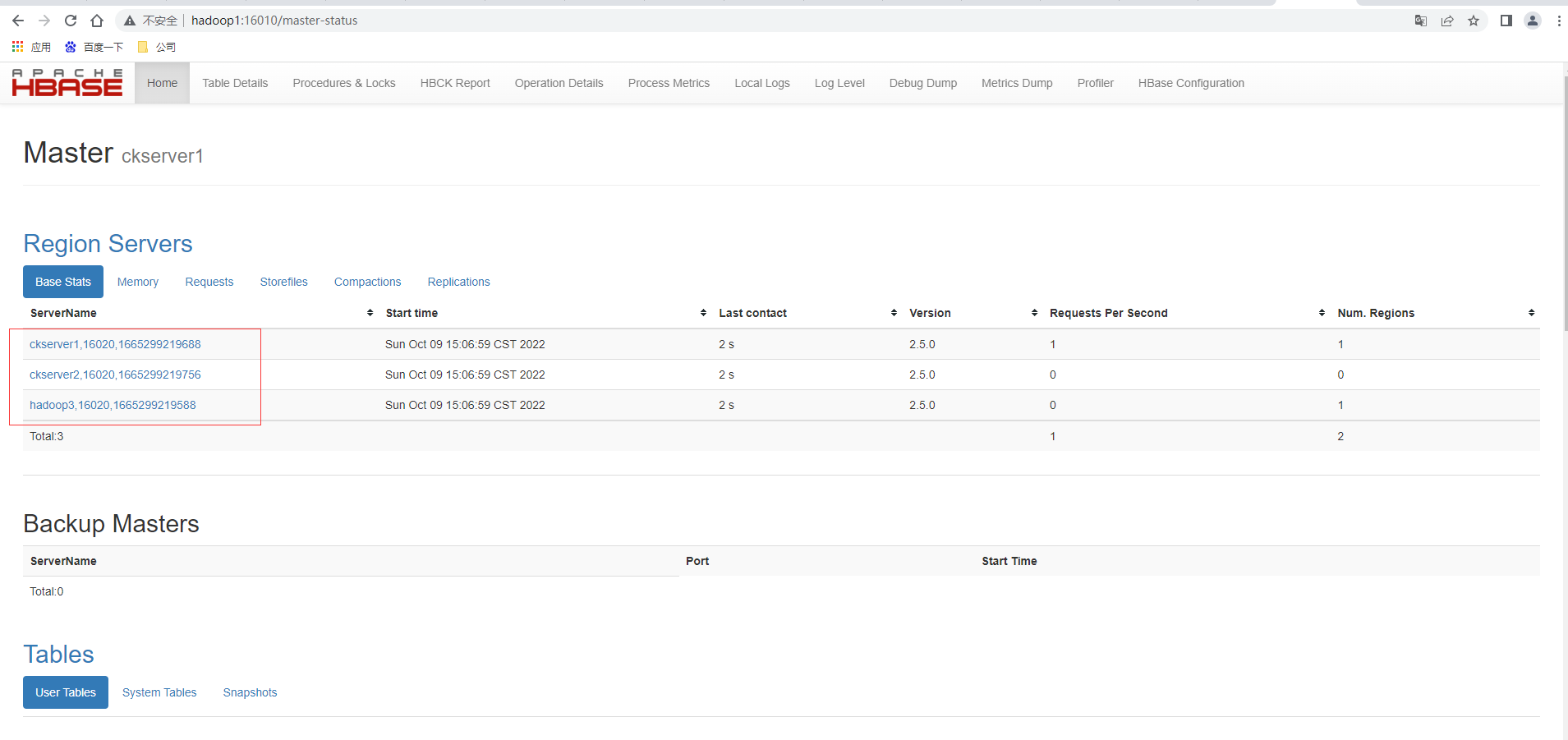
高可用
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载, 如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不 会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
# 先关闭上面启动的HBase集群
bin/stop-hbase.sh
# 在 conf 目录下创建 backup-masters 文件
touch conf/backup-masters
# 在 backup-masters 文件中配置高可用 HMaster 节点
echo hadoop2 > conf/backup-masters
# 将conf/backup-masters scp 到其他节点
scp /home/commons/hbase-2.5.0/conf/backup-masters hadoop2:/home/commons/hbase-2.5.0/conf
scp /home/commons/hbase-2.5.0/conf/backup-masters hadoop3:/home/commons/hbase-2.5.0/conf
# 重启 hbase
bin/start-hbase.sh
群启后查看服务进程,发现多了一个master进程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EteyEUXe-1665312413397)(image-20221009125044450.png)]
打开页面测试另一台master显示其为备用的Master,主master还是ckserver1也即是hadoop1,查看http://hadoop2:16010
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IePncDF4-1665312413398)(image-20221009125144397.png)]
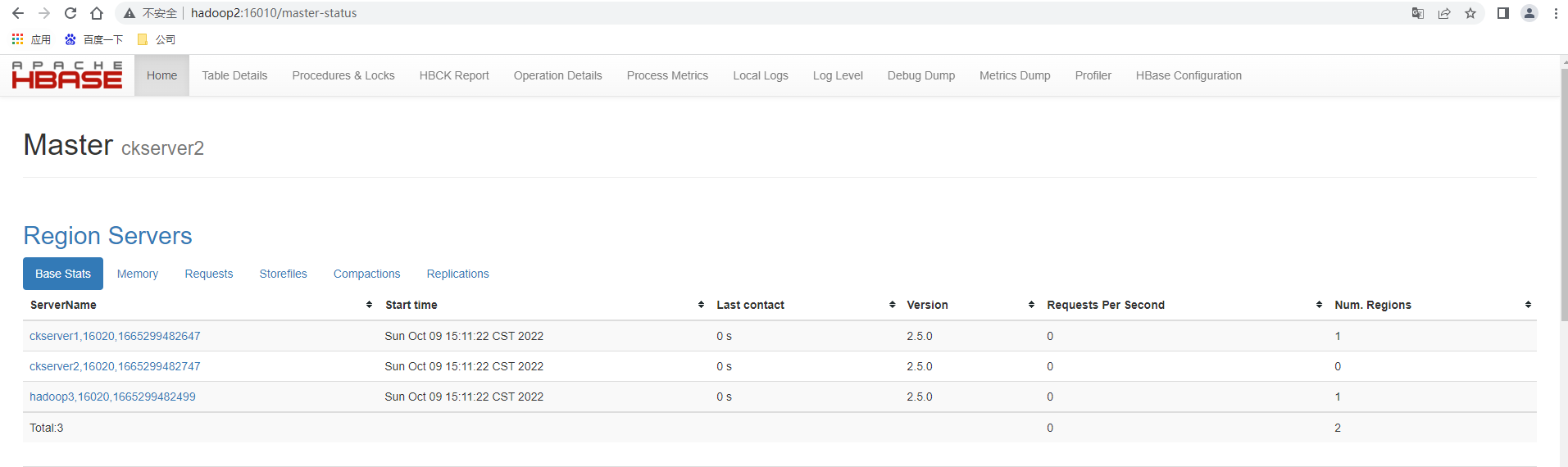
手动kill -9 杀死ckserver1也即是hadoop1上的HMaster进程,再次查看http://hadoop2:16010,发现主master已经成功的切换为ckserver2也即是hadoop2
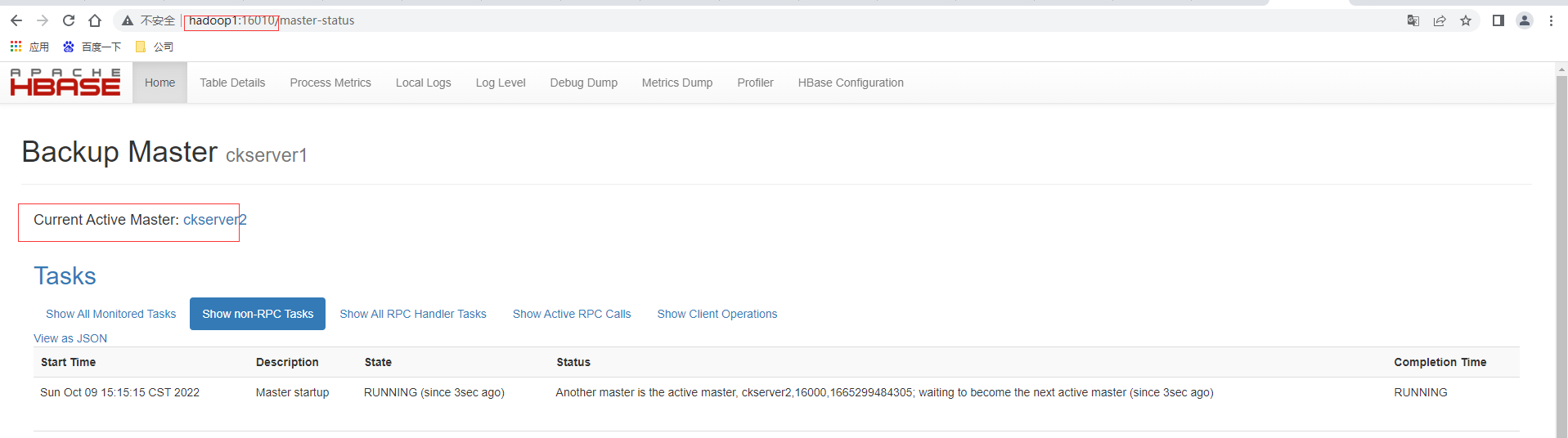
然后再单独启动ckserver1也即是hadoop1上的HMaster,执行bin/hbase-daemon.sh start master,这时访问http://hadoop1:16010,发现hadoop1为备用master。
Shell操作
基础操作
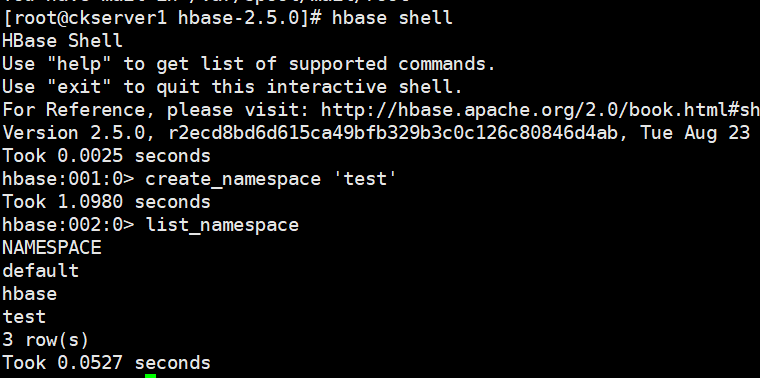
# 进入 HBase 客户端命令行hbase shell# 查看帮助命令够展示 HBase 中所有能使用的命令,主要使用的命令有 namespace 命令空间相关, DDL 创建修改表格,DML 写入读取数据。help
命令空间
# 使用特定的 help 语法能够查看命令如何使用。help 'create_namespace'# 创建命名空间 testcreate_namespace 'test'# 查看所有的命名空间list_namespace
DDL
# 创建表,在test命名空间中创建表格 student,两个列族。info 列族数据维护的版本数为 5 个, 如果不写默认版本数为 1。create 'test:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}# 如果创建表格只有一个列族,没有列族属性,可以简写。如果不写命名空间,使用默认的命名空间 default。create 'student1','info'# 查看表查看表有两个命令:list 和 describe,list:查看所有的表名,describe:查看一个表的详情listdescribe 'student1'
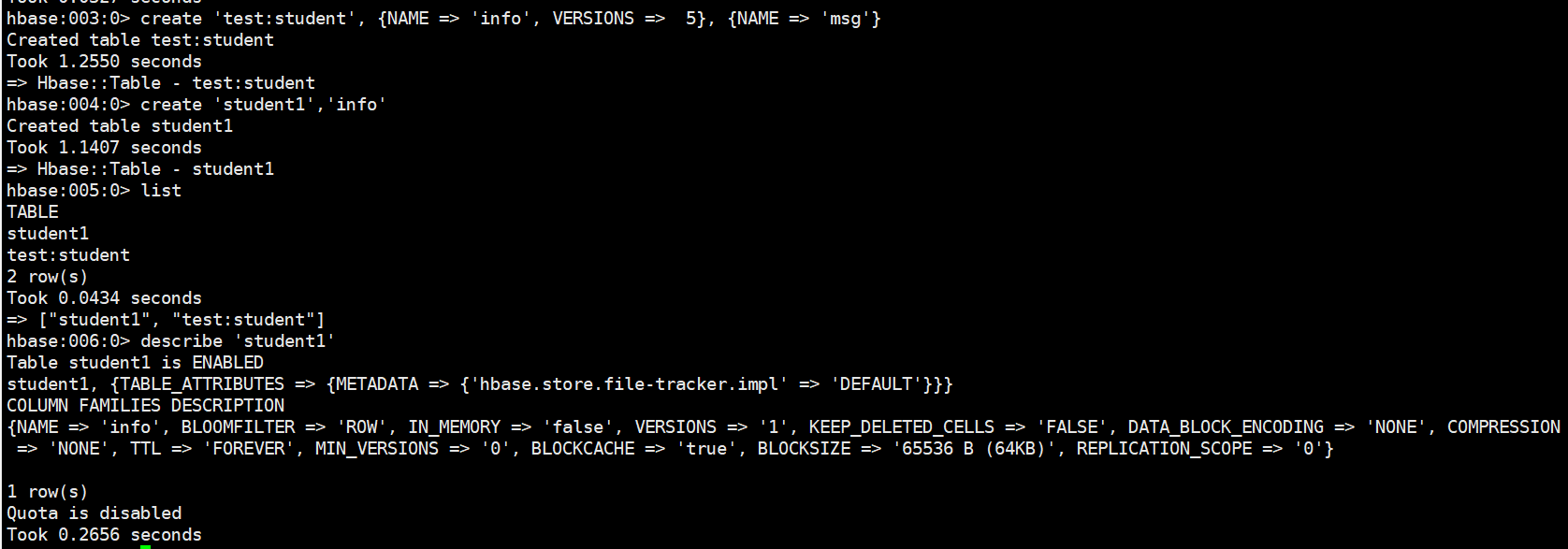
# 修改表表名创建时写的所有和列族相关的信息,都可以后续通过 alter 修改,包括增加删除列族。增加列族和修改信息都使用覆盖的方法alter 'student1', {NAME => 'f1', VERSIONS => 3} # 删除信息使用特殊的语法alter 'student1', NAME => 'f1', METHOD => 'delete' hbase:016:0> alter 'student1', 'delete' => 'f1'# shell 中删除表格,需要先将表格状态设置为不可用。disable 'student1' drop 'student1'
DML
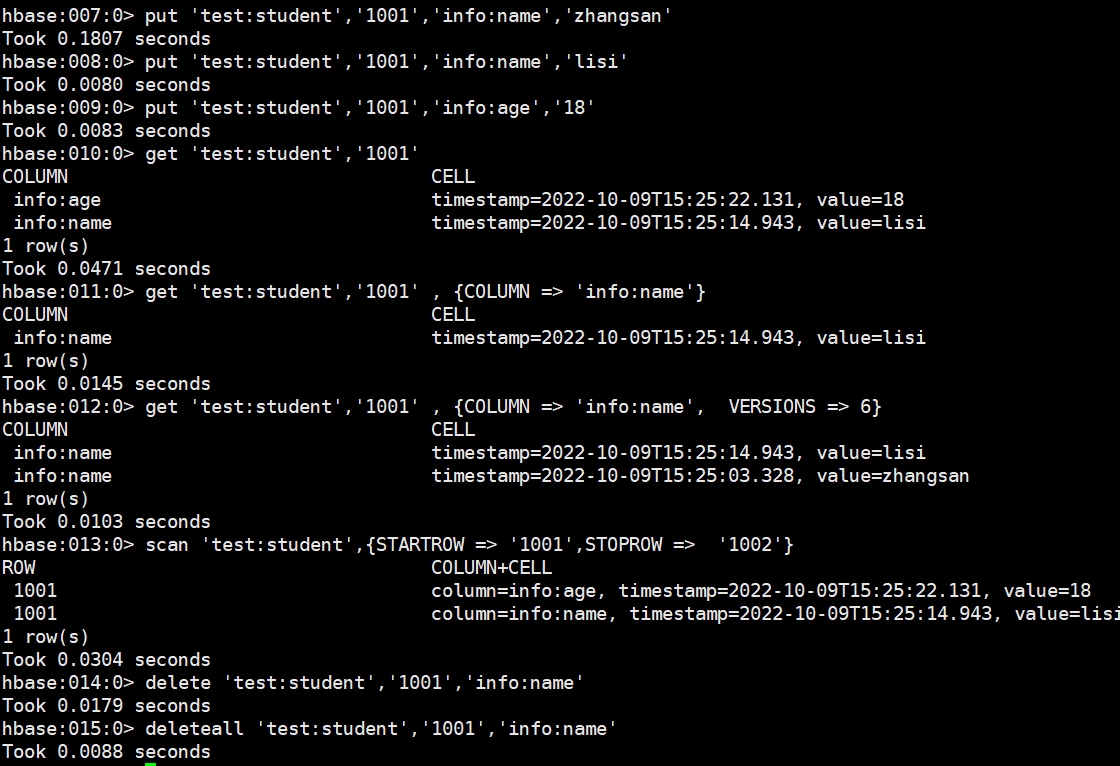
# 写入数据在 HBase 中如果想要写入数据,只能添加结构中最底层的 cell。可以手动写入时间戳指 定 cell 的版本,推荐不写默认使用当前的系统时间,如果重复写入相同 rowKey,相同列的数据,会写入多个版本进行覆盖。put 'test:student','1001','info:name','zhangsan' put 'test:student','1001','info:name','lisi' put 'test:student','1001','info:age','18' #读取数据,读取数据的方法有两个:get 和 scan。get最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell。get 'test:student','1001' get 'test:student','1001' , {COLUMN => 'info:name'} # 也可以修改读取 cell 的版本数,默认读取一个。最多能够读取当前列族设置的维护版本数。get 'test:student','1001' , {COLUMN => 'info:name', VERSIONS => 6} # scan 是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和 stopRow 来控制读取的数据,默认范围左闭右开。scan 'test:student',{STARTROW => '1001',STOPROW => '1002'} # 删除数据,删除数据的方法有两个:delete 和 deleteall;delete 表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本。delete 'test:student','1001','info:name'deleteall 'test:student','1001','info:name'
**本人博客网站 **IT小神 www.itxiaoshen.com
大数据技术之HBase原理与实战归纳分享-上的更多相关文章
- 大数据技术之HBase原理与实战归纳分享-中
@ 目录 底层原理 Master架构 RegionServer架构 Region/Store/StoreFile/Hfile之间的关系 写流程 写缓存刷写 读流程 文件合并 分区 JAVA API编程 ...
- 大数据技术之HBase原理与实战归纳分享-下
@ 目录 整合Phoenix 定义 为何要使用 安装 SHELL操作 表的映射 简易JDBC示例 二级索引 二级索引配置文件 全局索引 包含索引 本地索引(local index) HBase与 Hi ...
- 大数据技术之HBase
第1章 HBase简介 1.1 什么是HBase HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储. 官方 ...
- 【大数据技术】HBase介绍
1.HBase简介1.1 Hbase是什么HBase是一种构建在HDFS之上的分布式.面向列.多版本.非关系型的数据库,是Google Bigtable 的开源实现. 在需要实时读写.随机访问超大规模 ...
- 《大数据技术应用与原理》第二版-第三章分布式文件系统HDFS
3.1分布式文件 HDFS默认一个块的大小是64MB,与普通文件不同的是如果一个文件小于数据块的大小,它并不占用整个数据块的存储空间. 主节点又叫名称节点:另一个叫从节点又叫数据节点.名称节点负责文件 ...
- 【大数据技术】HBase与Solr系统架构设计
如何在保证存储量的情况下,又能保证数据的检索速度. HBase提供了完善的海量数据存储机制,Solr.SolrCloud提供了一整套的数据检索方案. 使用HBase搭建结构数据存储云,用来存储海量数据 ...
- 大数据技术之_08_Hive学习_05_Hive实战之谷粒影音(ETL+TopN)+常见错误及解决方案
第10章 Hive实战之谷粒影音10.1 需求描述10.2 项目10.2.1 数据结构10.2.2 ETL原始数据10.3 准备工作10.3.1 创建表10.3.2 导入ETL后的数据到原始表10.3 ...
- 《大数据技术应用与原理》第二版-第二章大数据处理架构Hadoop
2.1概述 Hadoop是Apache旗下的开源分布式计算平台,是基于Java开发的,具有很好的跨平台特性,其中核心文件是MapReduce和HDFS,而HDFS是根据谷歌文件系统GFS开源实现,是面 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
随机推荐
- 别再用 System.currentTimeMillis 统计耗时了,太 Low,试试 Spring Boot 源码在用的 StopWatch吧,够优雅!
大家好,我是二哥呀! 昨天,一位球友问我能不能给他解释一下 @SpringBootApplication 注解是什么意思,还有 Spring Boot 的运行原理,于是我就带着他扒拉了一下这个注解的源 ...
- python 日志类
简介 在所有项目中必不可少的一定是日志记录系统,python为我们提供了一个比较方便的日志模块logging,通常,我们都会基于此模块编写一个日志记录类,方便将项目中的日志记录到文件中. loggin ...
- 承上启下继往开来,Python3上下文管理器(ContextManagers)与With关键字的迷思
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_217 在开发过程中,我们会经常面临的一个常见问题是如何正确管理外部资源,比如数据库.锁或者网络连接.稍不留意,程序将永久保留这些资 ...
- 内网渗透之Windows认证(二)
title: 内网渗透之Windows认证(二) categories: 内网渗透 id: 6 key: 域渗透基础 description: Windows认证协议 abbrlink: d6b7 d ...
- C#静态类、静态成员、静态方法
一.作用 静态类和非静态类重要的区别是在于静态类不能被实例化,也就是说不能使用 new 关键字创建静态类类型的变量,防止程序员写代码来实例化该静态类或者在类的内部声明任何实例字段或方法. 用于存放不 ...
- @Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
@Autowired注解是spring用来支持依赖注入的核心利器之一,但是我们或多或少都会遇到required a single bean, but 2 were found(2可能是其他数字)的问题 ...
- PerfView专题 (第六篇):如何洞察 C# 中 GC 的变化
一:背景 在洞察 GC 方面,我觉得市面上没有任何一款工具可以和 PerfView 相提并论,这也是为什么我会在 WinDbg 之外还要学习这么一款工具的原因,这篇我们先简单聊聊 PerfView 到 ...
- 如何自定义一个Collector
Collectors类提供了很多方便的方法,假如现有的实现不能满足需求,我们如何自定义一个Collector呢? Collector接口提供了一个of方法,调用该方法就可以实现定制Collecto ...
- Excel 查找函数(二):VLOOKUP
函数讲解 [语法]VLOOKUP(lookup_value, table_array, col_index_num, [range_lookup]) [参数]函数一个有四个参数,其中有三个必填参数:一 ...
- 自动化选课(Python + selenium
前几天听到朋友说自己选课事情,突发奇想想要搞这样一个东西,但是由于各种原因只做到以下的完成度,具体的情况也会在解释的最后留下.这个只适用于曲师大的教务系统,因为用的这个系统来进行的一个调试,对于其 ...