谣言检测()——《Debunking Rumors on Twitter with Tree Transformer》
论文信息
论文标题:Debunking Rumors on Twitter with Tree Transformer
论文作者:Jing Ma、Wei Gao
论文来源:2020,COLING
论文地址:download
论文代码:download
1 Introduction
出发点:Existing conversation-based techniques for rumor detection either just strictly follow tree edges or treat all the posts fully-connected during feature learning.
创新点:Propose a novel detection model based on tree transformer to better utilize user interactions in the dialogue where post-level self-attention plays the key role for aggregating the intra-/inter-subtree stances.
例子:以 PLAN 模型为例子——一种帖子之间全连接的例子
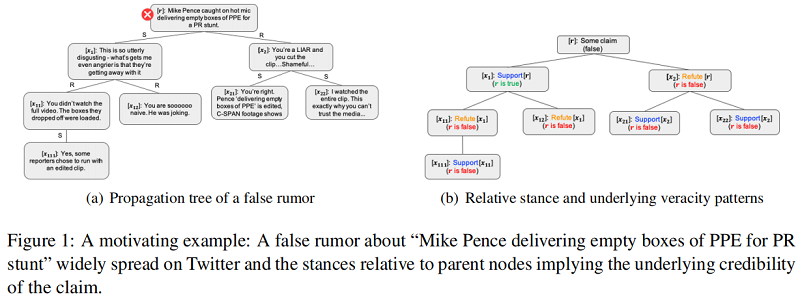
结论:Post 之间全连接的模型只适合浅层模型,并不适合深层模型,这是由于 Post 一般只和其 Parent 相关吗,全连接导致 Post 之间的错误连接加重。
2 Tree Transformer Model
2.1 Token-Level Tweet Representation
Transformer encoder 框架:
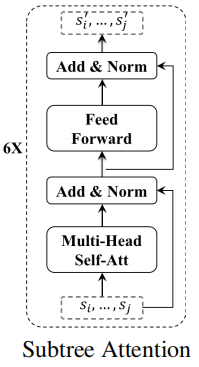
给定一条表示为 word sequence $x_{i}=\left(w_{1} \cdots w_{t} \cdots w_{\left|x_{i}\right|}\right)$ 的推文,每个 $w_{t} \in \mathbb{R}^{d}$ 是一个 $d$ 维向量,可以用预先训练的单词嵌入初始化。我们使用多头自注意网络(MH-SAN)将每个 $w_{i}$ 映射到一个固定大小的隐藏向量中。MH-SAN 的核心思想是共同关注来自不同位置的不同表示子空间的单词。更具体地说,MH-SAN 首先将输入字序列 $x_i$ 转换为具有不同线性投影的多个子空间:
其中,$\left\{Q_{i}^{h}, K_{i}^{h}, V_{i}^{h}\right\}$ 分别为 query、key 和 value representations,$\left\{W_{Q}^{h}, W_{K}^{h}, W_{V}^{h}\right\} $ 表示与第 $h$ 个头关联的参数矩阵。然后,应用 attention function 来生成输出状态。
$O_{i}^{h}=\operatorname{softmax}\left(\frac{Q_{i}^{h} \cdot K_{i}^{h^{\top}}}{\sqrt{d_{h}}}\right) \cdot V_{i}^{h} \quad\quad\quad(2)$
其中,$\sqrt{d_{h}}$ 是 放缩因子,$d_{h}$ 表示第 $h$ 个头的子空间的维数。最后,表示的输出可以看作是所有头 $O_{i}=\left[O_{i}^{1}, O_{i}^{2}, \cdots, O_{i}^{n}\right] \in \mathbb{R}^{\left|x_{i}\right| \times d}$ 的连接,$n$ 为头数,然后是一个归一化层(layerNorm)和前馈网络(FFN)。
$\begin{array}{l}B_{i}=\operatorname{layerNorm}\left(O_{i} \cdot W_{B}+O_{i}\right) \\H_{i}=\operatorname{FFN}\left(B_{i} \cdot W_{S}+B_{i}\right)\end{array} \quad\quad\quad(3)$
其中 $H_{i}=\left[h_{1} ; \ldots ; h_{\left|x_{i}\right|}\right] \in \mathbb{R}^{\left|x_{i}\right| \times d}$ 是表示 tweet $x_i$ 中所有单词的矩阵,$W_{B}$ 和 $W_{h}$ 包含 transformation 的权值。最后,我们通过 maxpooling 所有相关 words 的向量,得到了 $x_i$ 的表示:
$s_{i}=\max -\operatorname{pooling}\left(h_{1}, \ldots, h_{\left|x_{i}\right|}\right) \quad\quad\quad(4)$
其中,$s_{i} \in \mathbb{R}^{1 \times d}$ 为 $d$ 维向量,$|\cdot|$ 为单词数。
2.2 Post-Level Tweet Representation
(1) posts are generally short in nature thus the stance expressed in each node is closely correlated with the responsive context;
(2) posts in the same subtree direct at the individual opinion expressed in the root of the subtree.
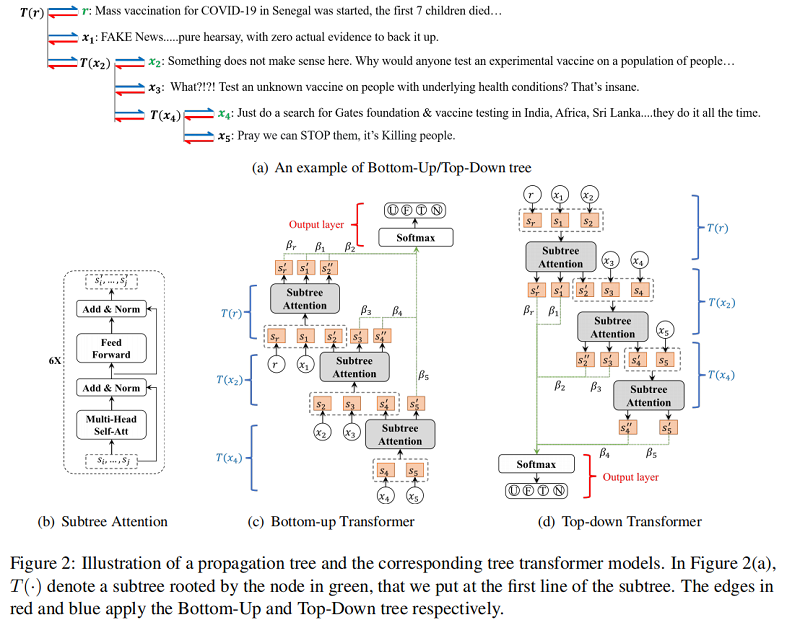
Figure 2(c) 说明了本文的 tree transformer 结构,它 cross-check 从底部子树到上部子树的 post。具体来说,给定一个有根于 $x_j$ 的子树,假设 $\mathcal{V}(j)=\left\{x_{j}, \ldots, x_{k}\right\}$ 表示子树中的节点集合,即 $x_j$ 及其直接响应节点。然后,我们在 $\mathcal{V}(j)$ 上应用一个 post-level subtree attention(a transformer-based block as shown in Figure 2(b)),以得到 $\mathcal{V}(j)$ 中每个节点的细化表示:
$\left[s_{j}^{\prime} ; \ldots ; s_{k}^{\prime}\right]=\operatorname{TRANS}\left(\left[s_{j} ; \ldots ; s_{k}\right], \Theta_{T}\right) \quad\quad\quad(5)$
其中,$TRANS (\cdot)$ 是具有如 Eq. 2-4 中所示的相似形式的 transform function,$\Theta_{T}$ 包含了 transformer 的参数。因此,$s_{*}^{\prime}$ 是基于子树的上下文得到的 $s_{*}$ 的细化表示。请注意,每个节点都可以被视为不同子树中的父节点或子节点,例如,在 Figure 2(a) 中,$x_{2}$ 可以是 $T\left(x_{2}\right)$ 的父节点,也可以是 $T(r)$ 的子节点。因此,一部分的节点在我们的 from bottom subtree to upper subtree 模型中结果两次层次细化:(1)通过与父节点相比来捕获立场 stance,(2) 通过关注邻居节点来获得较低权重的不准确信息,例如,一个父母支持一个错误的声明可能会细化如果大多数响应驳斥父节点。
Top-down transformer 的方向与 bottom-up transformer 相反,沿着信息传播的方向,其架构如 Figure 2 (d) 所示。同样的,其学习到的表示也通过捕获立场和自我纠正上下文信息得到增强。
2.3 The overall Model
为了共同捕获整个树中表达的观点,我们利用一个注意力层来选择具有准确信息的重要帖子,这是基于细化的节点表示而获得的。这将产生:
$\begin{array}{l}\alpha_{i}=\frac{\exp \left(s_{i}^{\prime} \cdot \mu^{\top}\right)}{\sum\limits_{j} \exp \left(s_{j}^{\prime} \cdot \mu^{\top}\right)} \\\tilde{s}=\sum\limits_{i} \alpha_{i} \cdot s_{i}^{\prime}\end{array}\quad\quad\quad(6)$
其中,$s_{i}^{\prime}$ 由 Bottom-Up Transformer 或 Top-Down Transformer 得到,$\mu \in \mathbb{R}^{1 \times d}$ 是注意力机制的参数。这里的 $\alpha_{i}$ 是节点 $x_i$ 的注意权值,用于生成整个树的表示 $\tilde{s}$。最后,我们使用一个全连接的输出层来预测谣言类上的概率分布。
$\hat{y}=\operatorname{softmax}\left(V_{o} \cdot \tilde{s}+b_{o}\right) \quad\quad\quad(7)$
其中,$V_{o}$ 和 $b_{o}$ 是输出层中的权值和偏差。
此外,还有一种直接的方法可以将 Bottom-Up transformer 与 Top-Down transformer 的树表示连接起来,以获得更丰富的树表示,然后将其输入上述的 $softmax (\cdot)$ 函数进行谣言预测。
我们所有的模型都经过训练,以最小化预测的概率分布和地面真实值的概率分布之间的平方误差:
$L(y, \hat{y})=\sum_{n=1}^{N} \sum_{c=1}^{C}\left(y_{c}-\hat{y}_{c}\right)^{2}+\lambda\|\Theta\|_{2}^{2} \quad\quad\quad(8)$
其中 $y_{c}$ 是 ground-truth label ,$\hat{y}_{c}$ 是类C的预测概率,$N$ 是训练的树数,C 是类的数量,$\|.\|_{2}$ 是所有模型参数 $\Theta$ 上的 $L_{2}$ 正则化项,$\lambda$ 是权衡系数。
3 Experiments
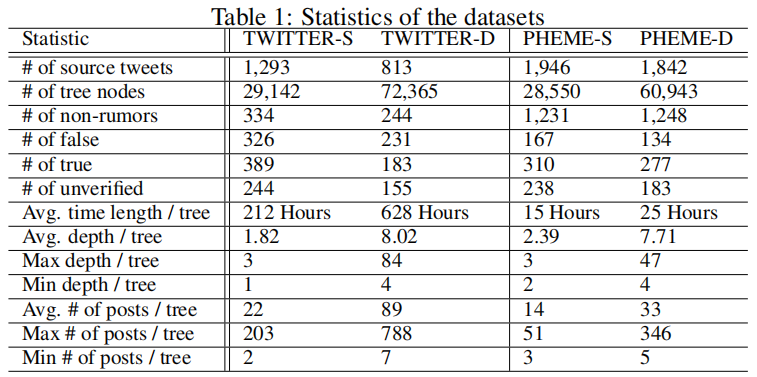
使用 TWITTER 和 PHEME 数据集进行实验,按照传播树深度将两个数据集划分为 TWITTER-S (PHEME-S)和 TWITTER-D (PHEME-D) 一共4个数据集,下表展示数据集的统计情况:
Experiment
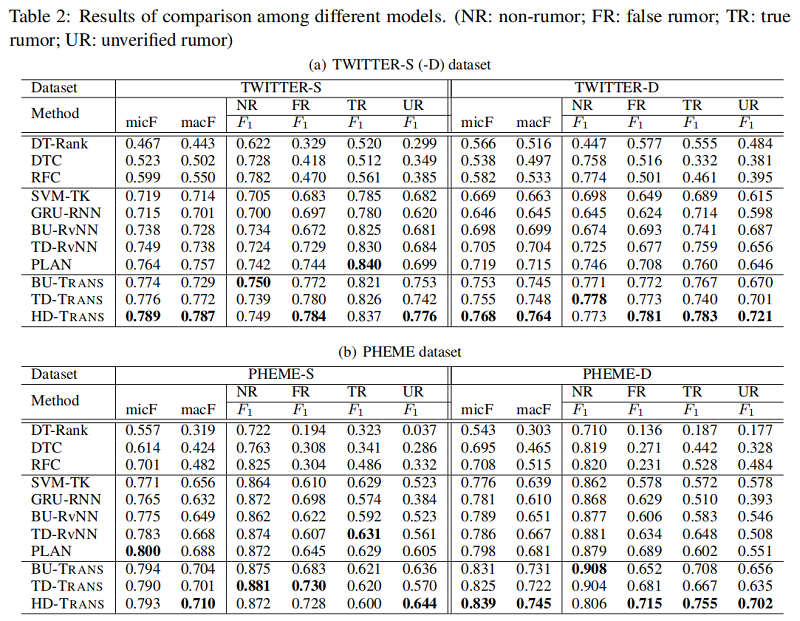
Early Rumor Detection Performance
谣言检测()——《Debunking Rumors on Twitter with Tree Transformer》的更多相关文章
- 谣言检测——《MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection》
论文信息 论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection论文作者:Jiaqi Zheng, ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- 谣言检测(ClaHi-GAT)《Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks》
论文信息 论文标题:Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks论文作者:Erx ...
- 谣言检测(PSIN)——《Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media》
论文信息 论文标题:Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media论 ...
- 谣言检测(PLAN)——《Interpretable Rumor Detection in Microblogs by Attending to User Interactions》
论文信息 论文标题:Interpretable Rumor Detection in Microblogs by Attending to User Interactions论文作者:Ling Min ...
- 谣言检测(RDEA)《Rumor Detection on Social Media with Event Augmentations》
论文信息 论文标题:Rumor Detection on Social Media with Event Augmentations论文作者:Zhenyu He, Ce Li, Fan Zhou, Y ...
- 谣言检测()《Rumor Detection with Self-supervised Learning on Texts and Social Graph》
论文信息 论文标题:Rumor Detection with Self-supervised Learning on Texts and Social Graph论文作者:Yuan Gao, Xian ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 谣言检测——(PSA)《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》
论文信息 论文标题:Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks论文作者:Jiayin ...
随机推荐
- .net core3.1 abp学习开始(一)
vs版本 2019,链接数据库使用Navicat,数据库MySql abp的官网:https://aspnetboilerplate.com/,我们去Download这里下载一个模板,需要选好Targ ...
- git常见问题及解决方法
简介 由于在git使用过程中会出现各种各样的问题,因此本文将常见的问题记录下来并提供相应的解决方案,方便后续查找. git pull问题: There is no tracking informati ...
- ebook下载 | 《 企业高管IT战略指南——企业为何要落地DevOps》
"当下,企业DevOps转型不仅是IT部门的事情,更是企业高管必须关注的焦点.DevOps是一项需要自上而下推动的变革运动,只有从顶层实施,才能获得成功.本书将介绍企业高管必须了解的,Dev ...
- 老板加薪!看我做的WPF Loading!!!
老板加薪!看我做的WPF Loading!!! 控件名:RingLoading 作者:WPFDevelopersOrg 原文链接: https://github.com/WPFDevelopersOr ...
- 它把RabbitMQ的复杂全屏蔽了,我朋友用它后被老板一夜提拔为.NET架构师
本文技术源自外企,并已在多个世界500强大型项目开发中运用. 本文适合有初/中级.NET知识的同学阅读.(支持.NET/.NET Framework/.NET Core) RabbitMQ作为一款主流 ...
- Web 前端实战:JQ 实现下拉菜单
实现过程 实现一个简易的鼠标悬停菜单项显示其子项的下拉框控件.将用到 CSS 绝对定位.流式布局.动画等:JQuery 鼠标移入和移出事件.DOM 查找.效果图如下: HTML 结构: <div ...
- systemd之导致内核 crash
本文主要讲解linux kernel panic系列其中一种情况: Attempted to kill init! exitcode=0x0000000b 背景:linux kernel 的panic ...
- java数组---多维数组
多维数组 多维数组可以看成是数组的数组 比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组. 二维数组 public static void main(String[] args) { ...
- 「题解报告」P3354
P3354 题解 题目传送门 一道很恶心的树形dp 但是我喜欢 题目大意: 一片海旁边有一条树状的河,入海口有一个大伐木场,每条河的分叉处都有村庄.建了伐木场的村庄可以直接处理木料,否则要往下游的伐木 ...
- Ubuntu locale设置
/bin/bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8) 解决方法: 1 sudo locale-gen &q ...