Hadoop单节点启动分布式伪集群
emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已。
配置HDFS
1. 安装好一台hadoop,可以参考这篇博客。
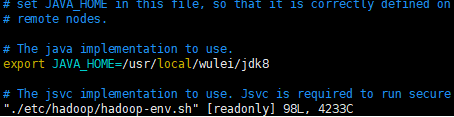
2. 在hadoop目录下编辑文件指定java环境变量 vim ./etc/hadoop/hadoop-env.sh
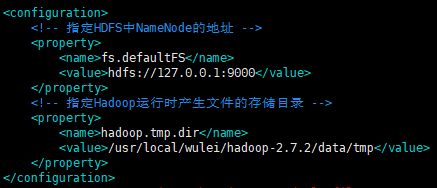
3.指定hdfs存储位置和地址 vim etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/wulei/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
core-site.xml
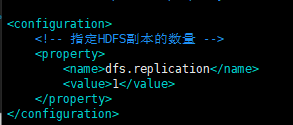
4. 指定hdsf副本数量 vim etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
hdfs-site.xml
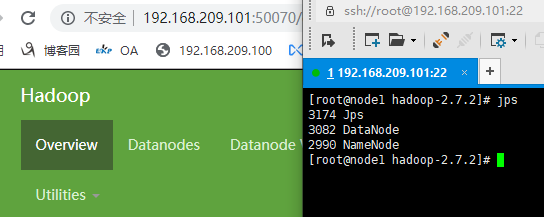
启动集群
(a)格式化NameNode(第一次启动时格式化会生成刚刚指定的data目录,以后就不要总格式化。格式化会让集群找不到已往数据datanode启动失败,所以一定要先删除data文件夹和log文件夹,然后再格式化)
[root@node1 hadoop-2.7.2]# bin/hdfs namenode -format
(b)启动NameNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
jps查看节点启动状态
配置YARN
1.指定环境变量 vim etc/hadoop/yarn-env.sh

2.配置环境变量 vim etc/hadoop/mapred-env.sh

3.配置(node1是当前主机名,可以 vim /etc/hosts 指定) vim etc/hadoop/yarn-site.xml
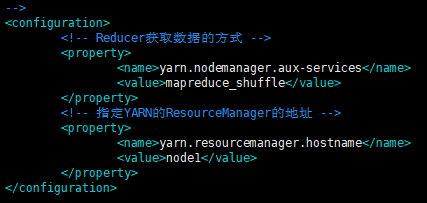
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
yarn-site.xml
4.将mapred-site.xml.template重新命名为 mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo vim etc/hadoop/mapred-site.xml <configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml

启动集群
1. 启动前必须保证NameNode和DataNode已经启动
[root@node1 hadoop-2.7.2]# jps
12133 NameNode
12203 DataNode
12303 Jps
2. 启动ResourceManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-resourcemanager-node1.out
3. 启动NodeManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
12609 NodeManager
12371 ResourceManager
12133 NameNode
12203 DataNode
12750 Jps
[root@node1 hadoop-2.7.2]#
Hadoop单节点启动分布式伪集群的更多相关文章
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
- Kafka 单节点多Kafka Broker集群
Kafka 单节点多Kafka Broker集群 接前一篇文章,今天搭建一下单节点多Kafka Broker集群环境. 配置与启动服务 由于是在一个节点上启动多个 Kafka Broker实例,所以我 ...
- redhat6.5 redis单节点多实例3A集群搭建
在进行搭建redis3M 集群之前,首先要明白如何在单节点上完成redis的搭建. 单节点单实例搭建可以参看这个网:https://www.cnblogs.com/butterflies/p/9628 ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- Zookeeper集群搭建(单机多节点,伪集群,docker-compose集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Zookeeper详解-伪分布式和集群搭建(八)
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- zookeeper的单实例和伪集群部署
原文链接: http://gudaoyufu.com/?p=1395 zookeeper工作方式 ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现 ...
- hadoop 2.5.1单机安装部署伪集群
环境:ubuntu 14.04 server 64版本 hadoop 2.5.1 jdk 1.6 部署的步骤主要参考了http://blog.csdn.net/greensurfer/article/ ...
随机推荐
- TCP输入 之 tcp_rcv_established
概述 tcp_rcv_established用于处理已连接状态下的输入,处理过程根据首部预测字段分为快速路径和慢速路径: 1. 在快路中,对是有有数据负荷进行不同处理: (1) 若无数据,则处理输入a ...
- SRS之SrsConfig类
1. 类定义 1.1 SrsConfig 类 /** * the config service provider. * for the config supports reload, so never ...
- Git客户端TortoiseGit下载、安装及汉化
本篇经验将和大家介绍Git客户端TortoiseGit下载.安装及汉化的方法,希望对大家的工作和学习有所帮助! TortoiseGit下载和安装 1 TortoiseGit是Windows下最好用 ...
- cygwin下make指令不存在 & cmd也能用make的配置方法
最近做毕设需要使用Mask R-CNN,就配置了相关环境,在安装pycocotools时要make,于是决定用cygwin来做.但在路径下make时出现了问题: bash错误:make指令不存在.一番 ...
- AutoItLibrary测试Windows GUI
AutoItLibrary库关键字 AutoItLibrary 的对象操作大体上有几大主要部分,Window 操作.Control 操作.Mouse 操作.Process操作.Run 操作.Reg 操 ...
- 微信小程序之生成二维码
最近项目中涉及到小程序的生成二维码,很是头疼,经过多次摸索,整理出了自己的一些思想方法,如有不足,欢迎指正. 首先完全按照小程序的结构依次填坑. pages--index.wxml <view ...
- WPF Visifire 图表控件
Visifire WPF 图表控件 破解 可能用WPF生成过图表的开发人员都知道,WPF虽然本身的绘图能力强大,但如果每种图表都自己去实现一次的话可能工作量就大了, 尤其是在开发时间比较紧的情况下.这 ...
- C++数据结构之哈希表
哈希表的定义:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方.键可以对应多个值(即哈希冲突),值根据相应的hash公式存入对应的键中. 哈希函数的构造要求 ...
- 工具类 分页工具类PageParamBean
自己编写的分页工具类,根据不同的数据库类型,生成对应的分页sql信息,分享给大家,希望大家共勉,工具类有些地方,大家可能不需要,请根绝自己的需要进行修改使用,核心逻辑都在,如果大家觉得有什么不妥,欢迎 ...
- Redis 几个类型常用命令
Redis 字符串(String) 下表列出了常用的 redis 字符串命令: 序号 命令及描述1 SET key value 设置指定 key 的值2 GET key 获取指定 key 的值.3 G ...