MySQL认识索引
什么是索引?
索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能
非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引的原理
索引原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
磁盘IO与预读
前面提到了访问磁盘,那么这里先简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS(Million Instructions Per Second)的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行约450万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。下图是计算机硬件延迟的对比图,供大家参考:

考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
认识key
认识mysql中的key:
index key 普通索引,能够加速查询,辅助索引
unique key 唯一 + 索引,辅助索引
primary key 唯一 + 非空 + 聚集索引
主键作为条件的查询如果能够让索引生效那么效率总是更高
foreign key 本身没有索引的,但是它关联的外表中的字段是unique索引
primary key 和unique 标识的字段不需要再添加索引
直接就可以利用索引加速查询
能用unique的时候尽量不用index
unique除了是索引之外还能做唯一约束,如果做了唯一约束
b+树就更健康
索引 : 实际上就是一个搜索表时使用的目录
聚集索引 : 叶子节点内直接存储行内容
只有innodb存储引擎才有聚集索引
主键
辅助索引 : 叶子节点中的数字指向数据的具体地址
innodb中和myisam中都可以存在
innodb 对应2个文件 表结构 数据 + 索引
myisam 对应3个文件 表结构 纯数据 辅助索
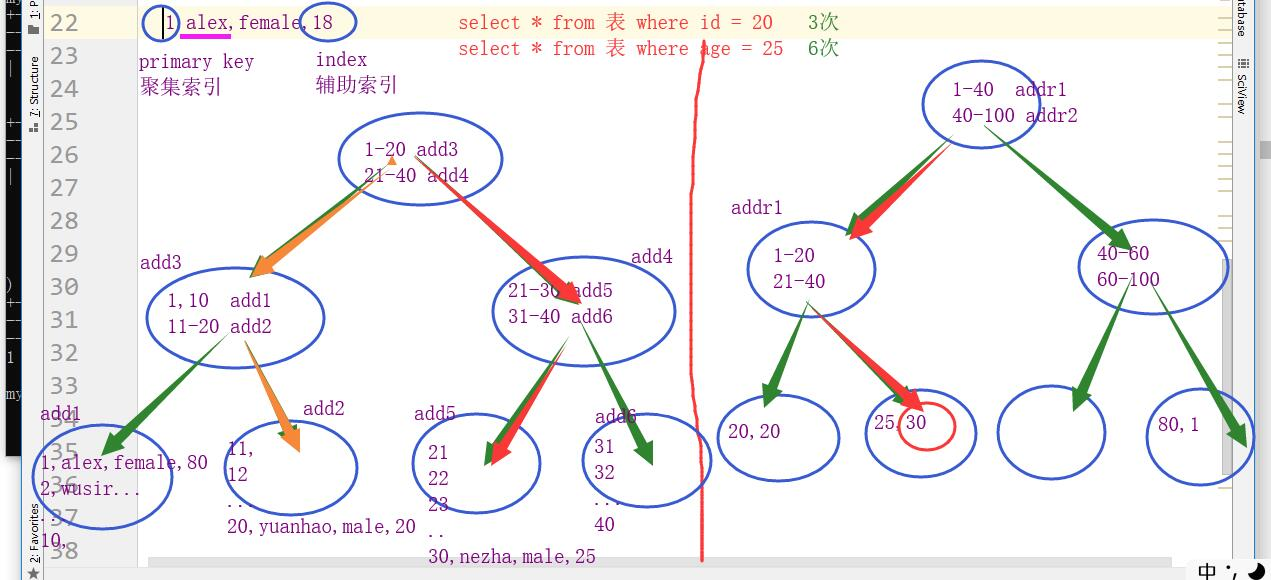
聚集索引和辅助索引
id name gender age
1 alex male 18
primary key index
聚集索引 辅助索引 创建普通索引
create index 索引名 on 表名(字段名)
desc 表名;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | MUL | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
show create table 表名;
| employee | CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`sex` enum('male','female') NOT NULL DEFAULT 'male',
`age` int(11) DEFAULT NULL,
`dep_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ind_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 |
结论:
聚集索引:叶子节点直接存储行内容,健康的树查询速度快仅需3次IO;(select * from 表名 where id = 20;),用聚集索引查找内容;
辅助索引:叶子节点中的数字指向数据的内存地址,我们通过用辅助索引查找到数据的内存地址后需要回表到聚集索引,拿着数据的内存地址找到真实的数据,需要6次IO;
注意:如果我们在创建表结构的时候没有创建主键(聚集索引),那么mysql会自动的帮我们创建一个主键,这个主键我们是看不到的,因为只有主键才是聚集索引,那么我们以后查询表中的数据都是通过辅助索引查询的,因为辅助索引比聚集索引遇到的IO多,查询速度更慢些,所以一般我们在创建表结构的时候都是自定义主键,这样能更好的利用聚集索引的优势;
MySQL认识索引的更多相关文章
- 【夯实Mysql基础】MySQL性能优化的21个最佳实践 和 mysql使用索引
本文地址 分享提纲: 1.为查询缓存优化你的查询 2. EXPLAIN 你的 SELECT 查询 3. 当只要一行数据时使用 LIMIT 1 4. 为搜索字段建索引 5. 在Join表的时候使用相当类 ...
- MySQL中索引和优化的用法总结
1.什么是数据库中的索引?索引有什么作用? 引入索引的目的是为了加快查询速度.如果数据量很大,大的查询要从硬盘加载数据到内存当中. 2.InnoDB中的索引原理是怎么样的? InnoDB是Mysql的 ...
- MySQL 联合索引详解
MySQL 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c ...
- Mysql复合索引
当Mysql使用索引字段作为条件时,如果该索引是复合索引,必须使用该索引中的第一个字段作为条件才能保证系统使用该索引,否则该索引不会被使用,并且应尽可能地让索引顺序和字段顺序一致
- 如何正确建立MYSQL数据库索引
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型. 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytabl ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- MySQL创建索引语法
1.介绍: 所有mysql索引列类型都可以被索引,对来相关类使用索引可以提高select查询性能,根据mysql索引数,可以是最大索引与最小索引,每种存储引擎对每个表的至少支持16的索引.总索引长度为 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- Mysql中索引的 创建,查看,删除,修改
创建索引 MySQL创建索引的语法如下: ? 1 2 3 CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON ...
- mysql 联合索引(转)
http://blog.csdn.net/lmh12506/article/details/8879916 mysql 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中 ...
随机推荐
- DaemonSet和StatefulSet
DaemonSet 的使用 通过该控制器的名称我们可以看出它的用法:Daemon,就是用来部署守护进程的,DaemonSet用于在每个Kubernetes节点中将守护进程的副本作为后台进程运行,说白了 ...
- 使用Harbor搭建Docker私有仓库
ip:192.168.0.145 环境设置 防火墙,selinux等,可以使用本章开头的那个shell脚本 其他主机的hosts文件也都添加上 ip hub.aaa.com windows系统的hos ...
- FLEX AIR 读写安卓本地文件
1. 目标: 将字节流图片保存在安卓本地路径,如 "/data/mypppd/"下, file = File.documentsDirectory.resolvePath(&qu ...
- phpspider爬虫框架的使用
这几天使用PHP的爬虫框架爬取了一些数据,发现还是挺方便的,先上爬虫框架的文档 phpspider框架文档 使用方法其实在文档中写的很清楚而且在demo中也有使用示例,这里放下我自己的代码做个笔记 & ...
- 使用LaTeX和KnitR自动生成报告
扩展名为.Rnw(Rtex)的文件就是包含了R代码的LaTeX文档.编译的时候,先用Rscript调用Knitr处理,生成.TeX文档,然后用pdfLaTeX/XeLaTeX编译成PDF. 最方便的编 ...
- Java攻城狮面试题录:笔试篇(1)
1.作用域public,private,protected,以及不写时的区别答:区别如下:不写时默认为friendly 2.ArrayList和Vector的区别,HashMap和Hashtable的 ...
- 【Day3】3.提取商城分类结构
import re with open('index.html','r',encoding='utf-8') as f: html = re.sub('\n','',f.read()) section ...
- js获取div基础元素
1.js获取div元素 clientHeight 获取对象的高度,不计算任何边距.边框.滚动条,但包括该对象的补白. clientLeft 获取 offsetLeft 属性和客户区域的实际左边之间的距 ...
- python Pillow 图片处理模块,好强大有没有
python Pillow 图片处理模块,好强大有没有 Pillow 需要给 python 另外安装 第一个用法:https://www.cnblogs.com/ibingshan/p/1105739 ...
- Pycharm建立web2py项目
web2py是一种免费的,开源的web开发框架,用于敏捷地开发安全的,数据库驱动的web应用:web2p采用Python语言编写,并且可以使用Python编程.web2py是一个完整的堆栈框架,也就是 ...