XGBoost的优点
1. Gradient boosting(GB)
Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题 残差和负梯度也是相同的。
残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量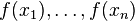 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
2. Gradient boosting Decision Tree(GBDT)
GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,
GBDT实际的核心问题变成怎么基于 使用CART回归树生成
使用CART回归树生成 ?
?
3. Xgboost
xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。
从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
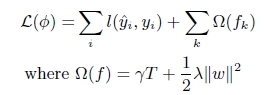
(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次的loss:
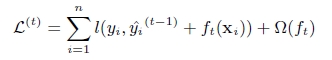
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
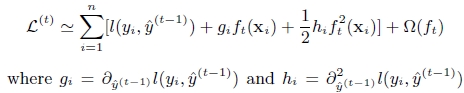
(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,XGBoost的并行是在特征粒度上的,XGBoost预先对特征的值进行排序,然后保存为block结构
xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关
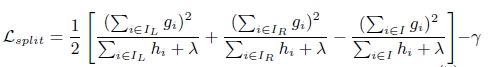
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
4)xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率
5)列抽样。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
凡是这种循环迭代的方式必定有停止条件,什么时候停止呢:
(1)当引入的分裂带来的增益小于一个阀值的时候,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有点预剪枝的意思(其实我这里有点疑问的,一般后剪枝效果比预剪枝要好点吧,只不过复杂麻烦些,这里大神请指教,为啥这里使用的是预剪枝的思想,当然Xgboost支持后剪枝),阈值参数为γγ 正则项里叶子节点数T的系数(大神请确认下);
(2)当树达到最大深度时则停止建立决策树,设置一个超参数max_depth,这个好理解吧,树太深很容易出现的情况学习局部样本,过拟合;
(3)当样本权重和小于设定阈值时则停止建树,这个解释一下,涉及到一个超参数-最小的样本权重和min_child_weight,和GBM的 min_child_leaf 参数类似,但不完全一样,大意就是一个叶子节点样本太少了,也终止同样是过拟合;
XGBoost的优点的更多相关文章
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- Python机器学习笔记:XgBoost算法
前言 1,Xgboost简介 Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器.因为Xgboost是一种提升树模型,所以它是将许多 ...
- 一文读懂机器学习大杀器XGBoost原理
http://blog.itpub.net/31542119/viewspace-2199549/ XGBoost是boosting算法的其中一种.Boosting算法的思想是将许多弱分类器集成在一起 ...
- 说说xgboost算法
xgboost算法最近真是越来越火,趁着这个浪头,我们在最近一次的精准营销活动中,也使用了xgboost算法对某产品签约行为进行预测和营销,取得了不错的效果.说到xgboost,不得不说它的两大优势, ...
- XGboost学习总结
XGboost,全称Extrem Gradient boost,极度梯度提升,是陈天奇大牛在GBDT等传统Boosting算法的基础上重新优化形成的,是Kaggle竞赛的必杀神器. XGboost属于 ...
- 集成学习之Boosting —— XGBoost
集成学习之Boosting -- AdaBoost 集成学习之Boosting -- Gradient Boosting 集成学习之Boosting -- XGBoost Gradient Boost ...
- XGBoost、LightGBM、Catboost总结
sklearn集成方法 bagging 常见变体(按照样本采样方式的不同划分) Pasting:直接从样本集里随机抽取的到训练样本子集 Bagging:自助采样(有放回的抽样)得到训练子集 Rando ...
- 史上最详细的XGBoost实战
史上最详细的XGBoost实战 0. 环境介绍 Python 版 本: 3.6.2 操作系统 : Windows 集成开发环境: PyCharm 1. 安装Python环境 安装Python 首先,我 ...
- Boosting算法总结(ada boosting、GBDT、XGBoost)
把之前学习xgb过程中查找的资料整理分享出来,方便有需要的朋友查看,求大家点赞支持,哈哈哈 作者:tangg, qq:577305810 一.Boosting算法 boosting算法有许多种具体算法 ...
随机推荐
- 2.安装阿里yum源
1.删除自带的yum源:#cd /etc/yum.repos.d/#rm -rf * 2.配置远程yum源:wget -O /etc/yum.repos.d/CentOS-Base.repo ht ...
- Java多线程(九):生产者消费者模型
生产者消费者模型 生产者:生产任务的个体: 消费者:消费任务的个体: 缓冲区:是生产者和消费者之间的媒介,对生产者和消费者解耦. 当 缓冲区元素为满,生产者无法生产,消费者继续消费: 缓冲区元素为空, ...
- 排查RabbitMQ安装错误
1.注册表中是否有 HKEY_LOCAL_MACHINE\SOFTWARE\Ericsson\Erlang\ErlSrv\1.1\RabbitMQ 此项.(须有) 2.安装目录是否存在中文.(不可有 ...
- 关于SpringBoot的自动配置和启动过程
一.简介 Spring Boot简化了Spring应用的开发,采用约定大于配置的思想,去繁从简,很方便就能构建一个独立的.产品级别的应用. 1.传统J2EE开发的缺点 开发笨重.配置繁多复杂.开发效率 ...
- 【转】Fetch超时设置和终止请求
原文链接:https://www.cnblogs.com/yfrs/p/fetch.html 1.基本使用 Fetch 是一个新的端获取资源的接口,用于替换笨重繁琐XMLHttpRequest.它有了 ...
- C++ STL 之 list
#include <list> #include <iostream> using namespace std; // 打印list元素 void PrintList(list ...
- hadoop中hive的属性
1.在hive中是可以删除文件的: hive> dfs -rm -R /u2.txt > ; Deleted /u2.txt 2.hive 中的default数据库 <propert ...
- redis __详解 (转载自作者:孤独烟 出处: http://rjzheng.cnblogs.com/)
https://www.cnblogs.com/rjzheng/p/9096228.html [原创]分布式之redis复习精讲 引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲> ...
- MySQL数据库常见问题1:关于 “ MySQL Installer is running in Community mode ” 的解决办法
现象: MYSQL在安装完成后,系统能正常运行,但是第二天出现了如下一个提示框,如下图: 给个人人都看得懂的如下图: 解决办法: 这个是新版本MySQL服务自带的一个定时任务,每天23: ...
- uuid:全局唯一标识符
uuid1:IEEE 802 MAC地址 import uuid ''' UUID1值使用主机的MAC地址计算.uuid模块使用getnode函数来获取当前系统的MAC值 ''' print(uuid ...