spark_rdd 一波怼完面试官系列
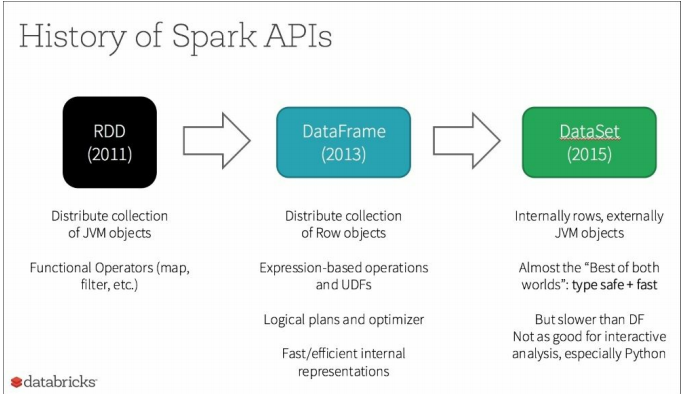
Resilient Distributed dataset , 弹性分布式数据集。
分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。
RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。
RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,
下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。
这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。大的集合,将所有数据都加载到内存中,方便进行多次重用。
第一,它是分布式的,可以分布在多台机器上,进行计算。
第二,它是弹性的,在计算处理过程中,机器的内存不够时,它会和硬盘进行数据交换,某种程度上会减低性能,但是可以确保计算得以继续进行。
特性
RDD是分布式只读且已分区集合对象。
这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。
具有自动容错、位置感知调度和可伸缩性,而容错性是最难实现的,大多数分布式数据集的容错性有
两种方式:数据检查点和记录数据的更新。对于大规模数据分析系统,数据检查点操作成本很高,
主要原因是大规模数据在服务器之间的传输带来的各方面的问题,相比记录数据的更新,RDD 也只支持粗粒度的转换,
也就是记录如何从其它 RDD 转换而来(即 Lineage),以便恢复丢失的分区。
其特性为:
1数据存储结构不可变
2支持跨集群的分布式数据操作
3可对数据记录按key进行分区
4提供了粗粒度的转换操作
5数据存储在内存中,保证了低延迟性
RDD的好处
1RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,
对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
2RDD的不变性,可以实现类Hadoop MapReduce的推测式执行。
3RDD的数据分区特性,可以通过数据的本地性来提高性能,这与Hadoop MapReduce是一样的。
4RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能会有大的下降但不会差于现在的MapReduce。
RDD编程接口
对于RDD,有两种类型的动作,一种是Transformation,一种是Action。它们本质区别是:
Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的
Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
Transformations转换操作,返回值还是一个 RDD,如 map、 filter、 union;
Actions行动操作,返回结果或把RDD持久化起来,如 count、 collect、 save。
RDD依赖关系
窄依赖(Narrow Dependencies)
一个父RDD分区最多被一个子RDD分区引用,表现为一个父RDD的分区;
对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区,如map、filter、union等操作则产生窄依赖;
宽依赖(Wide Dependencies)
一个子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区,如groupByKey等操作则产生宽依赖操作;
RDD数据存储管理
RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的。逻辑上RDD的每个分区叫一个Partition。
在Spark的执行过程中,RDD经历一个个的Transfomation算子之后,最后通过Action算子进行触发操作。
逻辑上每经历一次变换,就会将RDD转换为一个新的RDD,RDD之间通过Lineage产生依赖关系,这个关系在容错中有很重要的作用。
变换的输入和输出都是RDD。 RDD会被划分成很多的分区分布到集群的多个节点中。分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存存储
这是很重要的优化,以防止函数式数据不变性(immutable)导致的内存需求无限扩张。
有些RDD是计算的中间结果,其分区并不一定有相应的内存或磁盘数据与之对应,如果要迭代使用数据,可以调cache()函数缓存数据。
上图中,RDD1含有5个分区(p1、 p2、 p3、 p4、 p5),分别存储在4个节点(Node1、 node2、 Node3、 Node4)中。
RDD2含有3个分区(p1、 p2、 p3),分布在3个节点(Node1、 Node2、 Node3)中。
在物理上,RDD对象实质上是一个元数据结构,存储着Block、 Node等的映射关系,以及其他的元数据信息。
一个RDD就是一组分区,在物理数据存储上,RDD的每个分区对应的就是一个Block,Block可以存储在内存,当内存不够时可以存储到磁盘上。
每个Block中存储着RDD所有数据项的一个子集,暴露给用户的可以是一个Block的迭代器(例如,用户可以通过mapPartitions获得分区迭代器进行操作),
也可以就是一个数据项(例如,通过map函数对每个数据项并行计算)。在后面章节具体介绍数据管理的底层实现细节。
如果是从HDFS等外部存储作为输入数据源,数据按照HDFS中的数据分布策略进行数据分区,HDFS中的一个Block对应Spark的一个分区。
同时Spark支持重分区,数据通过Spark默认的或者用户自定义的分区器决定数据块分布在哪些节点。
例如,支持Hash分区(按照数据项的Key值取Hash值,Hash值相同的元素放入同一个分区之内)和Range分区(将属于同一数据范围的数据放入同一分区)等分区策略。
RDD有四种创建方式,如下:
1、从Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、HBase)输入(如HDFS)创建。
2、从父RDD转换得到新的RDD。
3、调用SparkContext()方法的parallelize,将Driver上的数据集并行化,转化为分布式的RDD。
4、更改RDD的持久性(persistence),例如cache()函数。默认RDD计算后会在内存中清除。通过cache()函数将计算后的RDD缓存在内存中。
RDD的两种操作算子
对于RDD可以有两种计算操作算子:Transformation(变换)与Action(行动)。
1、Transformation(变化)算子
Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个RDD的转换操作不是马上执行,需要等到有Actions操作时才真正触发运算。
2、Action(行动)算子
Action算子会触发Spark提交作业(Job),并将数据输出到Spark系统。
算子的分类:
1、Value数据类型的Transformation算子,这种变换算子不触发提交作业,针对处理的数据项是Value型的数据。
处理数据类型为Value型的Transformation算子可以根据RDD变换算子的输入分区与输出分区关系分为以下几种类型:
1、输入分区与输出分区一对一型。
2、输入分区与输入分区多对一型。
3、输入分区与输出分区多对多型。
4、输出分区为输入分区子集型。
5、一种特殊的输入与输出分区一对一的算子类型,即Cache型。Cache。
2、Key-Value数据类型的Transformation算子,这种变换算子不触发提交作业,针对处理的数据项是Key-Value型的数据对。
处理数据类型为Key-Value型的算子,大致分为以下几种类型:
1、输入分区与输出分区一对一型。
2、聚集(单个RDD聚集/多个RDD聚集)。
3、连接(对两个需要连接的RDD进行cogroup函数操作的Join/左外连接或右外连接(在Join的基础上进行))。
3、Action算子,这类算子会触发SparkContext提交Job作业。
本质上在Actions算子中通过SparkContext执行提交作业的runJob操作,触发了RDD DAG(有向无环图)的执行。根据Action算子的输出空间将Action算子分为以下几种类型:
1、无输出(对RDD中每个元素都应用f函数操作,不返回RDD和Array,而是返回Unit。即foreach。)。
2、HDFS(调用saveAsTextFile函数将数据输出存储到HDFS中;saveAsObjectFile将分区中的固定长度一组元素组成的一个Array然后将这个Array序列化,映射为Key-Value的元素写入HDFS为SequenceFile格式的文件)。
3、Scala集合和数据类型(collect;collectAsMap;reduceByKeyLocally;lookup;count;top;reduce;folt;aggregate)。spark_rdd 一波怼完面试官系列的更多相关文章
- 手撕面试官系列(一):spring108道面试题合集
前言 想必各位程序员已经开始准备金九银十的秋招了,创建这个这个系列文章的目的就是为了帮助大家解决面试的问题,系列文章将会一直更新,大家如果觉得不错可以关注我并转发,让更多程序兄弟看到~接下来我们进入正 ...
- 手撕面试官系列(六):并发+Netty+JVM+Linux面试专题
并发面试专题 (面试题+答案领取方式见侧边栏) 现在有 T1.T2.T3 三个线程,你怎样保证 T2 在 T1 执行完后执行,T3 在 T2 执行完后执行? 在 Java 中 Lock 接口比 syn ...
- 吊打面试官系列:Redis 性能优化的 13 条军规大全
1.缩短键值对的存储长度 键值对的长度是和性能成反比的,比如我们来做一组写入数据的性能测试,执行结果如下: 从以上数据可以看出,在 key 不变的情况下,value 值越大操作效率越慢,因为 Redi ...
- 手撕面试官系列(二):开源框架面试题Spring+SpringMVC+MyBatis
文章首发于今日头条:https://www.toutiao.com/i6712324863006081549/ 前言 跳槽时时刻刻都在发生,但是我建议大家跳槽之前,先想清楚为什么要跳槽.切不可跟风,看 ...
- JS十种经典排序算法,纯动画演示,学会了怼死面试官!
十种常见排序算法可以分为两大类: 非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序. 线性时间非比较类排序:不通过比较来决定 ...
- 手撕面试官系列(十一):BAT面试必备之常问85题
JVM专题 (面试题+答案领取方式见侧边栏) Java 类加载过程? 描述一下 JVM 加载 Class 文件的原理机制? Java 内存分配. GC 是什么? 为什么要有 GC? 简述 Java ...
- 手撕面试官系列(十):面试必备之常问Dubbo29题+MySQL55题
Dubbo专题 (面试题+答案领取方式见侧边栏) 1.Dubbo 支持哪些协议,每种协议的应用场景,优缺点?2.Dubbo 超时时间怎样设置?3.Dubbo 有些哪些注册中心?4.Dubbo 集群的负 ...
- 手撕面试官系列(九):分布式限流面试专题 Nginx+zookeeper
Nginx专题 (面试题+答案领取方式见侧边栏) 1.请解释一下什么是 Nginx?2.请列举 Nginx 的一些特性.3.请列举 Nginx 和 Apache 之间的不同点4.请解释 Nginx 如 ...
- 手撕面试官系列(八):分布式通讯ActiveMQ+RabbitMQ+Kafka面试专题
ActiveMQ专题 (面试题+答案领取方式见主页) 什么是 ActiveMQ? ActiveMQ 服务器宕机怎么办? 丢消息怎么办? 持久化消息非常慢. 消息的不均匀消费. 死信队列. Active ...
随机推荐
- 学习笔记:CentOS7学习之十八:Linux系统启动原理及故障排除
目录 学习笔记:CentOS7学习之十八:Linux系统启动原理及故障排除 18.1 centos6系统启动过程及相关配置文件 18.1.1 centos6系统启动过程 18.1.2 centos6启 ...
- Linux Shell中的变量声明和一些特殊变量
在SHELL中定义变量比较直接,无类型区别,不需要像Java那样定义好是String还是int等. 声明变量需要遵守或者注意的几点: 变量名和等号之间不能有空格. 变量名首字符必须为字母. 变量名里可 ...
- 删除重复信息且要保留一条的(roacle的rowid另类用法)
由于表的主键失效了(disable),导致导入了一些主键重复的数据,想保留唯一的一条, 最后发现其实可以用rowid来实现,不知道算不算是rowid的另类用法. delete /*+ parallel ...
- TCP的socket连接
package newtest; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStre ...
- 数据结构C++实现-第一章 绪论
1.1 计算机与算法 1.1.3 起泡排序 void bubbleSort(int a[], int n) { for(bool sorted=false; !sorted; --n) { sorte ...
- Kindergarten(网络流解法)
题意:http://acm.hdu.edu.cn/showproblem.php?pid=2458 问你二分图的最大团是多大. #define IOS ios_base::sync_with_stdi ...
- python — lambda表达式与内置函数
目录 1 lambda表达式 (匿名函数) 2 内置函数 1 lambda表达式 (匿名函数) 用于表示简单的函数 lambda表达式,为了解决简单函数的情况: def func(a1,a2): == ...
- Python面向对象中的继承、多态和封装
Python面向对象中的继承.多态和封装 一.面向对象的三大特性 封装:把很多数据封装到⼀个对象中,把固定功能的代码封装到⼀个代码块, 函数,对象, 打包成模块. 这都属于封装思想. 继承:⼦类可以⾃ ...
- 关于泛型擦除的知识(来源于csdn地址:https://blog.csdn.net/briblue/article/details/76736356)
泛型,一个孤独的守门者. 大家可能会有疑问,我为什么叫做泛型是一个守门者.这其实是我个人的看法而已,我的意思是说泛型没有其看起来那么深不可测,它并不神秘与神奇.泛型是 Java 中一个很小巧的概念,但 ...
- Inno Setup CreateProcess 失败:代码 740(Inno Setup打包的程序提升为管理员权限)
原文参考 https://www.cnblogs.com/SnailProgramer/p/4243666.html http://blog.csdn.net/x356982611/article/d ...