广义线性模型 R--glm函数
R语言glm函数学习:
【转载时请注明来源】:http://www.cnblogs.com/runner-ljt/
Ljt
作为一个初学者,水平有限,欢迎交流指正。
glm函数介绍:
glm(formula, family=family.generator, data,control = list(...))
family:每一种响应分布(指数分布族)允许各种关联函数将均值和线性预测器关联起来。
常用的family:
binomal(link='logit') ----响应变量服从二项分布,连接函数为logit,即logistic回归
binomal(link='probit') ----响应变量服从二项分布,连接函数为probit
poisson(link='identity') ----响应变量服从泊松分布,即泊松回归
control:控制算法误差和最大迭代次数
glm.control(epsilon = 1e-8, maxit = 25, trace = FALSE)
-----maxit:算法最大迭代次数,改变最大迭代次数:control=list(maxit=100)
glm函数使用:
>
> data<-iris[1:100,]
> samp<-sample(100,80)
> names(data)<-c('sl','sw','pl','pw','species')
> testdata<-data[samp,]
> traindata<-data[-samp,]
>
> lgst<-glm(testdata$species~pl,binomial(link='logit'),data=testdata)
Warning messages:
1: glm.fit:算法没有聚合
2: glm.fit:拟合機率算出来是数值零或一
> summary(lgst) Call:
glm(formula = testdata$species ~ pl, family = binomial(link = "logit"),
data = testdata) Deviance Residuals:
Min 1Q Median 3Q Max
-1.836e-05 -2.110e-08 -2.110e-08 2.110e-08 1.915e-05 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -83.47 88795.25 -0.001 0.999
pl 32.09 32635.99 0.001 0.999 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1.1085e+02 on 79 degrees of freedom
Residual deviance: 1.4102e-09 on 78 degrees of freedom
AIC: 4 Number of Fisher Scoring iterations: 25 >
注意在使用glm函数就行logistic回归时,出现警告:
Warning messages:
1: glm.fit:算法没有聚合
2: glm.fit:拟合機率算出来是数值零或一
同时也可以发现两个系数的P值都为0.999,说明回归系数不显著。
第一个警告:算法不收敛。
由于在进行logistic回归时,依照极大似然估计原则进行迭代求解回归系数,glm函数默认的最大迭代次数 maxit=25,当数据不太好时,经过25次迭代可能算法 还不收敛,所以可以通过增大迭代次数尝试解决算法不收敛的问题。但是当增大迭代次数后算法仍然不收敛,此时数据就是真的不好了,需要对数据进行奇异值检验等进一步的处理。
>
> lgst<-glm(testdata$species~pl,binomial(link='logit'),data=testdata,control=list(maxit=100))
Warning message:
glm.fit:拟合機率算出来是数值零或一
> summary(lgst) Call:
glm(formula = testdata$species ~ pl, family = binomial(link = "logit"),
data = testdata, control = list(maxit = 100)) Deviance Residuals:
Min 1Q Median 3Q Max
-1.114e-05 -2.110e-08 -2.110e-08 2.110e-08 1.162e-05 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -87.18 146399.32 -0.001 1
pl 33.52 53808.49 0.001 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1.1085e+02 on 79 degrees of freedom
Residual deviance: 5.1817e-10 on 78 degrees of freedom
AIC: 4 Number of Fisher Scoring iterations: 26 >
如上,通过增加迭代次数,解决了第一个警告,此时算法收敛。
但是第二个警告仍然存在,且回归系数P=1,仍然不显著。
第二个警告:拟合概率算出来的概率为0或1
首先,这个警告是什么意思?
我们先来看看训练样本的logist回归结果,拟合出的每个样本属于'setosa'类的概率为多少?
>
>lgst<-glm(testdata$species~pl,binomial(link='logit'),data=testdata,control=list(maxit=100))
>p<-predict(lgst,type='response')
>plot(seq(-2,2,length=80),sort(p),col='blue')
>
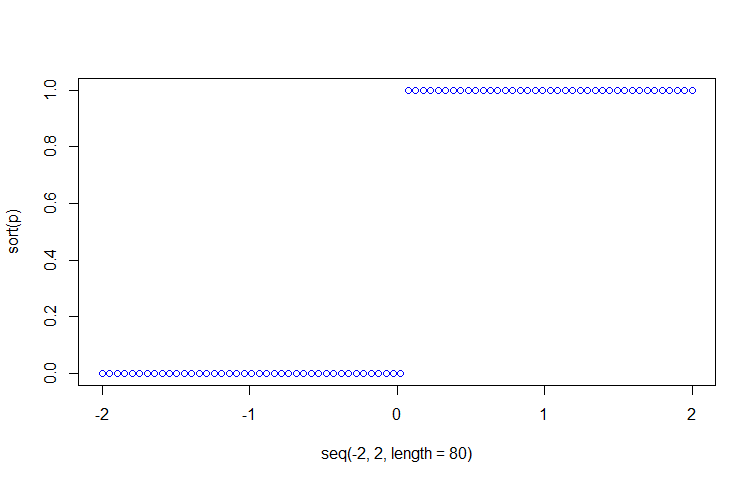
可以看出训练样本为'setosa'类的概率不是几乎为0,就是几乎为1,并不是我们预想中的logistic模型的S型曲线,这就是第二个警告的意思。
那么问题来了,为什么会出现这种情况?
(以下内容只是本人参考一些解释的个人理解)
这种情况的出现可以理解为一种过拟合,由于数据的原因,在回归系数的优化搜索过程中,使得分类的种类属于某一种类(y=1)的线性拟合值趋于大,分类种类为另一 类(y=0)的线性拟合值趋于小。
由于在求解回归系数时,使用的是极大似然估计的原理,即回归系数在搜索过程中使得似然函数极大化:
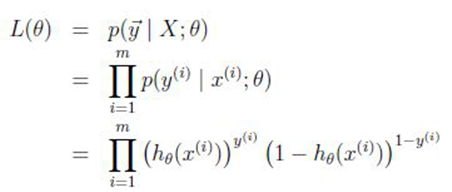
所以在搜索过程中偏向于使得y=1的h(x)趋向于大,而使得y=0的h(x)趋向于小。
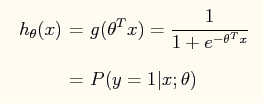
即系数Θ使得 Y=1类的 -ΘTX 趋向于大,使得Y=0类的 -ΘTX 趋向于小。而这样的结果就会导致P(y=1|x;Θ)-->1 ; P(y=0|x;Θ)-->0 .
那么问题又来了,什么样的数据会导致这样的过拟合产生呢?
先来看看上述logistic回归中种类为setosa和versicolor的样本pl值的情况。(横轴代表pl值,为了避免样本pl数据点叠加在一起,增加了一个无关的y值使样本点展开)
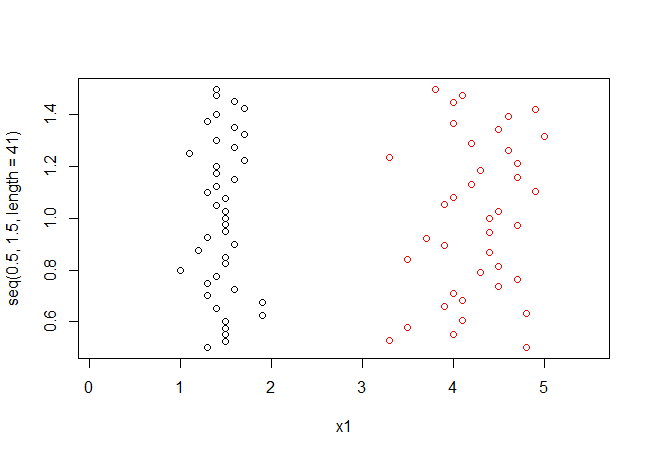
可以看出两类数据明显的完全线性可分。
故在回归系数搜索过程中只要使得一元线性函数h(x)的斜率的绝对值偏大,就可以实现y=1类的h(x)趋向大,y=0类的h(x)趋向小。
所以当样本数据完全可分时,logistic回归往往会导致过拟合的问题,即出现第二个警告:拟合概率算出来的概率为0或1。
出现了第二个警告后的logistic模型进行预测时往往是不适用的,对于这种线性可分的样本数据,其实直接使用规则判断的方法则简单且适用(如当pl<2.5时则直接判断为setosa类,pl>2.5时判断为versicolor类)。
以下,对于不完全可分的二维训练数据展示logistic回归过程。
>
> data<-iris[51:150,]
> samp<-sample(100,80)
> names(data)<-c('sl','sw','pl','pw','species')
> testdata<-data[samp,]
> traindata<-data[-samp,]
>
> lgst<-glm(testdata$species~sw+pw,binomial(link='logit'),data=testdata)
> summary(lgst) Call:
glm(formula = testdata$species ~ sw + pw, family = binomial(link = "logit"),
data = testdata) Deviance Residuals:
Min 1Q Median 3Q Max
-1.82733 -0.16423 0.00429 0.11512 2.12846 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -12.915 5.021 -2.572 0.0101 *
sw -3.796 1.760 -2.156 0.0310 *
pw 14.735 3.642 4.046 5.21e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 110.85 on 79 degrees of freedom
Residual deviance: 24.40 on 77 degrees of freedom
AIC: 30.4 Number of Fisher Scoring iterations: 7 >#画拟合概率曲线图
> p<-predict(lgst,type='response')
> plot(seq(-2,2,length=80),sort(p),col='blue')
>
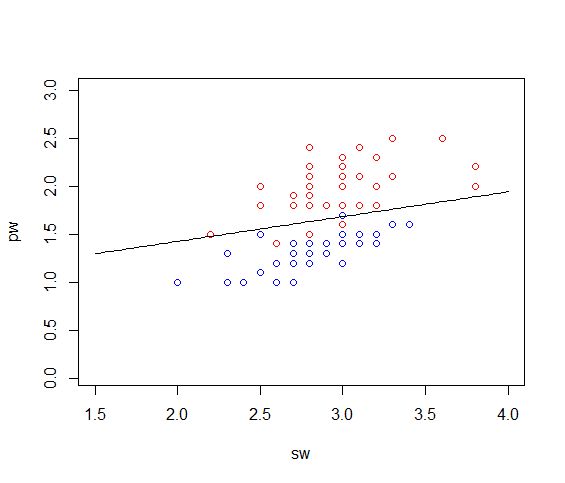
>#画训练样本数据散点图
>a<-testdata$species=='versicolor'
> x1<-testdata[a,'sw']
> y1<-testdata[a,'pw']
> x2<-testdata[!a,'sw']
> y2<-testdata[!a,'pw']
> summary(testdata$sw)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.700 2.900 2.881 3.100 3.800
> summary(testdata$pw)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 1.300 1.600 1.672 2.000 2.500
>
> plot(x1,y1,xlim=c(1.5,4),ylim=c(.05,3),xlab='sw',ylab='pw',col='blue')
> points(x2,y2,col='red')
>
> #画分类边界图,即画h(x)=0.5的图像
> x3<-seq(1.5,4,length=100)
> y3<-(3.796/14.735)*x3+13.415/14.735
> lines(x3,y3)
拟合概率曲线图:
(基本上符合logistic模型的S型曲线)

训练样本散点图及分类边界:
(画logistic回归的分类边界即画曲线h(x)=0.5)
广义线性模型 R--glm函数的更多相关文章
- 第三章 广义线性模型(GLM)
广义线性模型 前面我们举了回归和分类得到例子.在回归的例子中,$y \mid x;\theta \sim N(u,\sigma ^{2})$,在分类例子中,$y\mid x;\theta \sim ...
- 广义线性模型(GLM)
一.广义线性模型概念 在讨论广义线性模型之前,先回顾一下基本线性模型,也就是线性回归. 在线性回归模型中的假设中,有两点需要提出: (1)假设因变量服从高斯分布:$Y={{\theta }^{T}}x ...
- CS299笔记:广义线性模型
指数分布族 我们称一类分布属于指数分布族(exponential family distribution),如果它的分布函数可以写成以下的形式: \[ \begin{equation} p(y;\et ...
- 广义线性模型(Generalized Linear Model)
广义线性模型(Generalized Linear Model) http://www.cnblogs.com/sumai 1.指数分布族 我们在建模的时候,关心的目标变量Y可能服从很多种分布.像线性 ...
- R语言实战(八)广义线性模型
本文对应<R语言实战>第13章:广义线性模型 广义线性模型扩展了线性模型的框架,包含了非正态因变量的分析. 两种流行模型:Logistic回归(因变量为类别型)和泊松回归(因变量为计数型) ...
- 广义线性模型 GLM
Logistic Regression 同 Liner Regression 均属于广义线性模型,Liner Regression 假设 $y|x ; \theta$ 服从 Gaussian 分布,而 ...
- R语言-广义线性模型
使用场景:结果变量是类别型,二值变量和多分类变量,不满足正态分布 结果变量是计数型,并且他们的均值和方差都是相关的 解决方法:使用广义线性模型,它包含费正太因变量的分析 1.Logistics回归( ...
- [读书笔记] R语言实战 (十三) 广义线性模型
广义线性模型扩展了线性模型的框架,它包含了非正态的因变量分析 广义线性模型拟合形式: $$g(\mu_\lambda) = \beta_0 + \sum_{j=1}^m\beta_jX_j$$ $g( ...
- 从广义线性模型(GLM)理解逻辑回归
1 问题来源 记得一开始学逻辑回归时候也不知道当时怎么想得,很自然就接受了逻辑回归的决策函数--sigmod函数: 与此同时,有些书上直接给出了该函数与将 $y$ 视为类后验概率估计 $p(y=1|x ...
随机推荐
- 自定义View总结2
自定义控件: 1.组合控件:将系统原生控件组合起来,加上动画效果,形成一种特殊的UI效果 2.纯粹自定义控件:继承自系统的View,自己去实现view效果 优酷菜单: 1.系统原生的旋转和位置动画并没 ...
- 安卓框架——SlidingMenu使用技巧
SlidingMenu的一些常用属性 原文转载http://blog.csdn.net/zwl5670/article/details/48274109 [java] view plain copy ...
- Rxjava +Retrofit 你需要掌握的几个技巧,Retrofit缓存,RxJava封装,统一对有无网络处理,异常处理, 返回结果问题
本文出处 :Tamic 文/ http://blog.csdn.net/sk719887916/article/details/52132106 Rxjava +Rterofit 需要掌握的几个技巧 ...
- 数组中的数分为两组,让给出一个算法,使得两个组的和的差的绝对值最小,数组中的数的取值范围是0<x<100,元素个数也是大于0, 小于100 。
比如a[]={2,4,5,6,7},得出的两组数{2,4,6}和{5,7},abs(sum(a1)-sum(a2))=0: 比如{2,5,6,10},abs(sum(2,10)-sum(5,6))=1 ...
- Hazelcast集群原理分析
简介 hazelcast其中一个很重要的应用就是可以将多个应用服务器组成一个分布式环境的应用,形成一个cluster.这个cluster可以选举出一个master来对外工作.而cluster中的各台服 ...
- ROS探索总结(十六)——HRMRP机器人的设计
1. HRMRP简介 HRMRP(Hybrid Real-time Mobile Robot Platform,混合实时移动机器人平台)机器人是我在校期间和实验室的其他小伙伴一起从零开 ...
- Android播放在线音乐文件
Android播放在线音频文件 效果图: 源码下载地址: http://download.csdn.net/detail/q4878802/9020687 添加网络权限: <uses-permi ...
- 3.2、Android Studio在物理设备中运行APP
当你构建一个Android应用时,在发布给用户之前,在物理设备上测试一下你的应用是非常必要的. 你可以使用Android设备作为运行.调试和测试应用的环境.包含在SDK中的工具让你在编译完成后在设备中 ...
- [ExtJS5学习笔记]第十一节 Extjs5MVVM模式下系统登录实例
本文地址:http://blog.csdn.net/sushengmiyan/article/details/38815923 实例代码下载地址: http://download.csdn.net/d ...
- 深入解剖unsigned int 和 int
就如同int a:一样,int 也能被其它的修饰符修饰.除void类型外,基本数据类型之前都可以加各种类型修饰符,类型修饰符有如下四种: 1.signed----有符号,可修饰char.int.Int ...