Python Selenium 之数据驱动测试
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据。可以将测试脚本与测试数据分离,使得测试脚本在不同数据集合下高度复用。不仅可以增加复杂条件场景的测试覆盖,还可以极大减少测试脚本的编写与维护工作。
下面将使用Python下的数据驱动模式(ddt)库,结合unittest库以数据驱动模式创建百度搜索的测试。
ddt库包含一组类和方法用于实现数据驱动测试。可以将测试中的变量进行参数化。
可以通过python自带的pip命令进行下载并安装:pip install ddt . 更多关于ddt的信息可以参考:
https://pypi.org/project/ddt/
一个简单的数据驱动测试
为了创建数据驱动测试,需要在测试类上使用@ddt装饰符,在测试方法上使用@data装饰符。@data装饰符把参数当作测试数据,参数可以是单个值、列表、元组、字典。对于列表,需要用@unpack装饰符把元组和列表解析成多个参数。
下面实现百度搜索测试,传入搜索关键词和期望结果,代码如下:
import unittest
from selenium import webdriver
from ddt import ddt, data, unpack @ddt
class SearchDDT(unittest.TestCase):
'''docstring for SearchDDT'''
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com") # specify test data using @data decorator
@data(('python', 'PyPI'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value) search_button = self.driver.find_element_by_id('su')
search_button.click() tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag) def tearDown(self):
self.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
在test_search()方法中,search_value与expected_result两个参数用来接收元组解析的数据。当运行脚本时,ddt把测试数据转换为有效的python标识符,生成名称为更有意义的测试方法。结果如下:

使用外部数据的数据驱动测试
如果外部已经存在了需要的测试数据,如一个文本文件、电子表格或者数据库,那也可以用ddt来直接获取数据并传入测试方法进行测试。
下面将借助外部的CSV(逗号分隔值)文件和EXCLE表格数据来实现ddt。
通过CSV获取数据
同上在@data装饰符使用解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
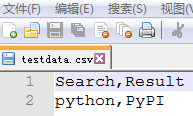
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、CSV文件名。调用CSV库去读取文件并返回一行数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import csv, unittest
from selenium import webdriver
from ddt import ddt, data, unpack def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
data_file = open(file_name, "r")
# create a CSV Reader from CSV file
reader = csv.reader(data_file)
# skip the headers
next(reader, None)
# add rows from reader to list
for row in reader:
rows.append(row)
return rows @ddt
class SearchCSVDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com") # get test data from specified csv file by using the get_data funcion
@data(*get_data('testdata.csv'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value) search_button = self.driver.find_element_by_id('su')
search_button.click() tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag) def tearDown(self):
self.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
通过Excel获取数据
测试中经常用Excle存放测试数据,同上在也可以使用@data装饰符来解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
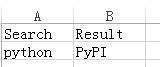
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、EXCEL文件名。调用xlrd库去读取文件并返回数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import xlrd, unittest
from selenium import webdriver
from ddt import ddt, data, unpack def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
book = xlrd.open_workbook(file_name)
# get the frist sheet
sheet = book.sheet_by_index(0)
# iterate through the sheet and get data from rows in list
for row_idx in range(1, sheet.nrows): #iterate 1 to maxrows
rows.append(list(sheet.row_values(row_idx, 0, sheet.ncols)))
return rows @ddt
class SearchEXCLEDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com") # get test data from specified excle spreadsheet by using the get_data funcion
@data(*get_data('TestData.xlsx'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value) search_button = self.driver.find_element_by_id('su')
search_button.click() tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag) def tearDown(self):
self.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
与上面读取CVS文件一样,测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
如果想从数据库的库表中获取数据,同样也需要一个get_data()方法,并且通过DB相关的库来连接数据库、SQL查询来获取测试数据。
Python Selenium 之数据驱动测试的更多相关文章
- Python Selenium 之数据驱动测试的实现
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据.可以将测 ...
- Selenium WebDriver 数据驱动测试框架
Selenium WebDriver 数据驱动测试框架,以QQ邮箱添加联系人为示例,测试框架结构如下图,详细内容请阅读吴晓华编著<Selenium WebDiver 实战宝典>: Obje ...
- 开源you-get项目爬虫,以及基于python+selenium的自动测试利器
写在前面 爬虫和自动测试,对于python来说是最合适不过也是最擅长的. 开源的项目也很多,例如you-get项目https://github.com/soimort/you-get.盗链和爬虫神器. ...
- python selenium中如何测试360等基于chrome内核的浏览器
转自:https://blog.csdn.net/five3/article/details/50013159 直接上代码,注意是基于chrome内核的浏览器,基于ie的请替换其中的chrome方法为 ...
- Python&Selenium 关键字驱动测试框架之数据文件解析
摘要:在关键字驱动测试框架中,除了PO模式以及一些常规Action的封装外,一个很重要的内容就是读写EXCEL,在团队中如何让不会写代码的人也可以进行自动化测试? 我们可以将自动化测试用例按一定的规格 ...
- python selenium自动化(二)自动化注册流程
需求:使用python selenium来自动测试一个网站注册的流程. 假设这个网站的注册流程分为三步,需要提供比较多的信息: 在这个流程里面,需要用户填入信息.在下拉菜单中选择.选择单选的radio ...
- python for selenium 数据驱动测试
# -*- coding:utf-8 -*- """ 数据驱动测试,从 csv 文件中读取数据 """ from selenium impo ...
- Python+Selenium笔记(十二):数据驱动测试
(一) 前言 通过使用数据驱动测试,实现对输入值和预期结果的参数化.(例如:输入数据和预期结果可以直接读取Excel文档的数据) (二) ddt 使用ddt执行数据驱动测试,ddt库可以将测试 ...
- Python+Selenium+Unittest+Ddt+HTMLReport分布式数据驱动自动化测试框架结构
1.Business:公共业务模块,如登录模块,可以把登录模块进行封装供调用 ------login_business.py from Page_Object.Common_Page.login_pa ...
随机推荐
- mysql 查询select语句汇总
数据准备: 创建表: create table students( id int unsigned primary key auto_increment not null, name varchar( ...
- spring cloud eureka显示ip
eureka.instance.preferIpAddress=trueeureka.instance.instance-id=${spring.cloud.client.ipAddress}:${s ...
- python基础——列表推导式
python基础--列表推导式 1 列表推导式定义 列表推导式能非常简洁的构造一个新列表:只用一条简洁的表达式即可对得到的元素进行转换变形 2 列表推导式语法 基本格式如下: [expr for va ...
- 一大波 Android 刘海屏来袭,全网最全适配技巧!
一.序 Hi,大家好,我是承香墨影! Apple 一直在引领设计的潮流,自从 iPhone X 发布之后,"刘海屏" 就一直存在争议.不过不管你怎样,Android 也要跻入 &q ...
- 个人网站建设(适合Java初学者)(一)
概述 作为一个在八本学校在校生,没有实验室,也没有项目可做.一直想做一个个人博客,一年前学完javaweb之后做了一个简单的博客,ui惨不忍睹就算了,还有各种bug.酝酿了很久,寒假用了将近一个月时间 ...
- [C#]200 行代码使用 C# 实现区块链
文章原文来自:Code your own blockchain in less than 200 lines of Go!,原始文章是通过 Go 语言来实现自己的区块链的,这里我们参照该文章来使用 C ...
- 妙用 scale 与 transfrom-origin,精准控制动画方向
上次发完 不可思议的纯 CSS 导航栏下划线跟随效果 这篇文章之后,很多朋友找我讨论,感叹 CSS 的奇妙. 然后昨天,群里一位朋友问到了一个和这个效果比较类似的效果,问如何 将下面这个动画的下划线效 ...
- [LeetCode] Single Element in a Sorted Array 有序数组中的单独元素
Given a sorted array consisting of only integers where every element appears twice except for one el ...
- SpringMVC 自定义类型转换器
先准备一个JavaBean(Employee) 一个Handler(SpringMVCTest) 一个converters(EmployeeConverter) 要实现的输入一个字符串转换成一个emp ...
- NC二次开发常用的表
常用的表: 收费清单:pr_cr_receivables 会计月份: bd_accperiodmonth 20180416