pandas数据处理基础——筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构)。
本文为了方便理解会与excel或者sql操作行或列来进行联想类比
1.重新索引:reindex和ix
上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号。列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子。
1.1 Series
比方说:data=Series([4,5,6],index=['a','b','c']),行索引为a,b,c。
我们用data.reindex(['a','c','d','e'])修改索引后则输出:

可以理解成我们用reindex设了索引后,根据索引去原来data里面匹配对应的值,没匹配上的就是NaN。
1.2 DataFrame
(1)行索引修改:DataFrame行索引同Series
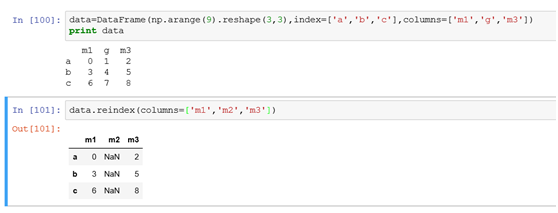
(2)列索引修改:列索引用reindex(columns=['m1','m2','m3']),用参数columns来指定对列索引进行修改。修改逻辑类似行索引,也是相当于用新列索引去匹配原来的数据,没匹配上的置NaN
例:
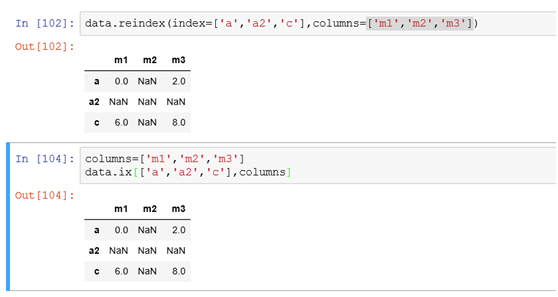
(3)同时对行和列索引进行修改可以用
2.丢弃指定轴上的列(通俗的说法就是删除行或者列):drop
通过索引进行选择删除哪一行或者哪一列
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如

- obj['b']相当于select * from tb where xid='b'
- obj['b','a','c']相当于select * from tb where xid in ('a','b','c'),且结果按照b ,a ,c 的顺序排列后进行展示,这是与sql的区别
- obj[0:1]和obj['a':'b']的区别如下:
#前者是不包含末端,后者是包含了末端

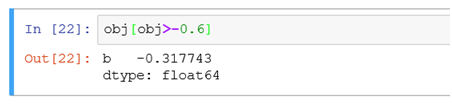
(2)按照值的大小进行筛选obj[obj>-0.6]相当于在obj数据中找出值比-0.6大的记录进行展示
3.2 DataFrame
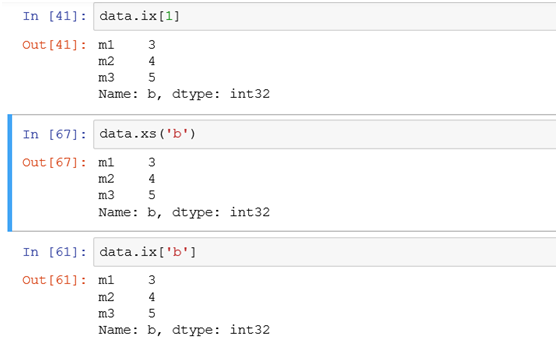
(1)选择单行用ix或者xs:
如筛选索引为b的那条行记录用以下三种方式
(2)选择多行:
筛选索引为a,b的两条行记录的方式
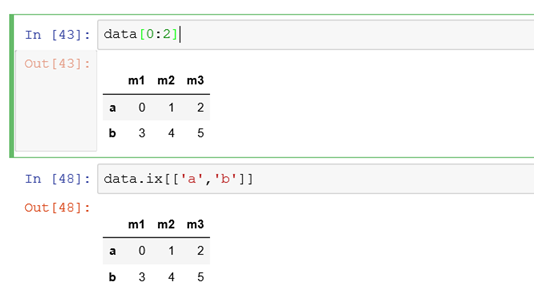
#以上不能直接写成data[['a','b']]
data[0:2]表示从第一行到第二行的记录。第一行默认从0开始数,不包含末端的2。
(3)选择单列
筛选m1列的所有行记录数据
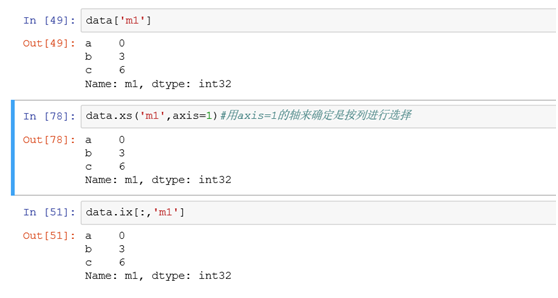
(4)选择多列
筛选m1,m3两个列,所有行记录的数据

ix[:,['m1','m2']]前面的:表示所有的行都筛选进来。
(5)根据值的大小条件筛选行或者列
如筛选出某一列值大于4的所有记录相当于select * from tb where 列名>4
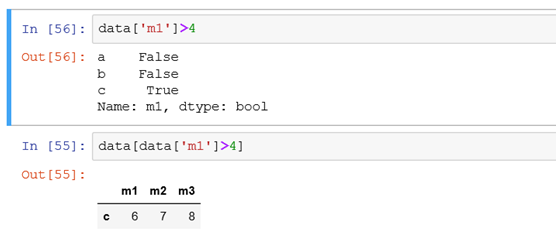
(6)如果筛选某列值大于4的所有记录,且只需展示部分列的情况时

行用条件进行筛选,列用[0,2]筛选第一列和第三列的数据
pandas数据处理基础——筛选指定行或者指定列的数据的更多相关文章
- css3实现超出文本指定行数(指定文本长度)用省略号代替
测试代码: <!DOCTYPE html> <html> <head> <meta name="viewport" content=&qu ...
- pandas数据处理基础——基础加减乘除的运算规则
上周公司对所有员工封闭培训了一个星期,期间没收手机,基本上博客的更新都停止了,尽管培训时间不长,但还是有些收获,不仅来自于培训讲师的,更多的是发现自己与别人的不足,一个优秀的人不仅仅是自己专业那块的精 ...
- linux提取指定行至指定位置
grep查找ERROR,定位位置 awk打印到指定行数 sed打印到文本末尾 awk打印到文本末尾 方法一 #!/bin/csh -f if(-f errorlog.rpt) then rm -rf ...
- shell awk读取文件中的指定行的指定字段
1.awk功能和实用形式 awk指定读取文件中的某一行的某个字段 awk 可以设置条件来输出文件中m行到n行中每行的指定的k字段,使用格式如下 awk 'NR==m,NR==n {pr ...
- 使用sed替换指定文件指定行的指定文本
下面是将85行的127.0.0.1替换为192.168.10.108 sed -i '85{s/127.0.0.1/192.168.10.108/}' /etc/zabbix/zabbix_agent ...
- Pandas数据处理实战:福布斯全球上市企业排行榜数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用. 本文通过实例操作来介绍用pandas进行数据整理. 照例先说下我的运行环境,如下: w ...
- POI读取指定Excel中行与列的数据
import org.apache.poi.xssf.usermodel.XSSFCell; import org.apache.poi.xssf.usermodel.XSSFRow; import ...
- pandas 一行文本拆多行,一列拆多列
https://zhuanlan.zhihu.com/p/28337202 一列拆多列: http://blog.csdn.net/qq_22238533/article/details/761875 ...
- sql 多行转多列,多行转一列合并数据,列转行
下面又是一种详解:
随机推荐
- Microsoft Dynamics CRM2011 更换Logo
之前操作过但没做过记录,这里记录下以防以后有需要时记不起来还有迹可循 IE收藏栏的图标,在网站根目录下的的/favicon.ico CRM网页中的Logo,替换/_imgs/crmmastheadlo ...
- GDAL书籍中删除数据勘误(C#语言)
GDAL书籍中关于C#版本删除数据的时候,不能完全删除数据,由于我对C#不了解导致代码有点问题,非常感谢@Bingoyin指出并给出修改方案.此外对于栅格图像的删除.重命名,矢量数据的删除和重命名都有 ...
- Mybatis3.4.0不支持mybatis-spring1.2.5及以下版本
今天将工程的Mybatis的版本由3.3.0升级到3.4.0导致程序运行错误,使用的mybatis-spring版本是1.2.3,错误内容如下,最后发现是SpringManagedTransactio ...
- shell入门之流程控制语句
1.case 脚本: #!/bin/bash #a test about case case $1 in "lenve") echo "input lenve" ...
- Java-IO之BufferedInputStream(缓冲输入流)
BufferedInputStream是缓冲输入流,继承于FilterInputStream,作用是为另一个输入流添加一些功能,本质上是通过一个内部缓冲数组实现的.例如,在新建某输入流对应的Buffe ...
- Java --Annotation学习心得体会及笔记
相对于注释这种给程序员看的信息: 注解,就是给程序看的解释性的语言,其作用就相当于配置文件的存在.其存在的意义在于以下几点: 优点: 方便的使程序员看到相关项的关联位置及关联方式等信息. 缺点: 由于 ...
- 软件测试进阶(一)A/B测试终极指南
A/B测试终极指南 A/B测试不是一个时髦名词.现在很多有经验的营销和设计工作者用它来获得访客行为信息,来提高转换率.然而,A/B测试与SEO不同的是,人们都不太知道如何进行网站分析和可用性分析.他们 ...
- 【一天一道LeetCode】#125. Valid Palindrome
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- UNIX环境高级编程——线程
线程包含了表示进程内执行环境必需的信息,其中包括进程中标示线程的线程ID.一组寄存器值.栈.调度优先级和策略.信号屏蔽字.errno变量以及线程私有数据. 进程的所有信息对该进程的所有线程都是共享的, ...
- 【一天一道LeetCode】#92. Reverse Linked List II
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Reverse ...