ConcurrentHashMap源码分析(一)
本篇博客的目录:
前言
一:ConcurrentHashMap简介
二:ConcurrentHashMap的内部实现
三:总结
前言:HashMap很多人都熟悉吧,它是我们平时编程中高频率出现的一种集合,用于封装key、value这种形式的数据。项目中也很多用到它,之前我的博客也有介绍HashMap的源码,它的内部数据结构。那么我们再往前走一步,考虑一下多线程的环境,我们知道HashMap是非线程安全的,那么到了多线程的环境,怎么办?或许有人会说用HashTable啊,它就是线程安全的。或者还可以用Collection.synchronized(Map map)将一个普通的map变成线程安全的。这样的实现是可以,但是它存在一个显著的缺点就是效率问题,HashTable打开jdk源码可以看到它的底层实现还依赖于HashMap,只不过每个方法前都加上了synchronized关键字,这样做最大的一个问题就是效率。synchronized是阻塞的,当一个线程访问这个方法的内部的时候。其他线程只能阻塞等待。那么如何解决这个问题呢?ConcurrentHashMap采用了高明的做法,它的内部机制是分段锁,采用分段的机制,能有效的避免阻塞的问题,那么本篇博客就来一探ConcurrentHashMap究竟,看它是如何实现分段锁的。
一:ConcurrentHashMap简介
ConcurrentHashMap位于java.util.concurrent并发包中,继承自AbstractMap<K,V>:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable
我们来看一下它的UML图,如下:
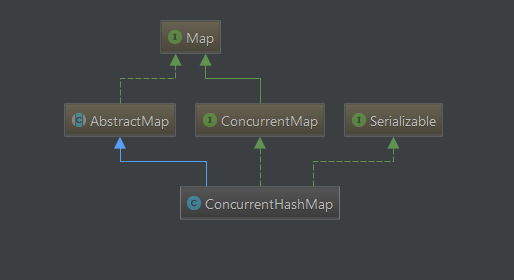
可以看出concurrentHashMap继承自Map,又分别实现了AbstractMap和ConcurrentMao接口,并且实现了serizlizable序列化接口。从这一点可以知道它具备了Map的特点,比如常用的put、get、remove方法等等它都具备。
它的内部结构图主要如下:其中可以看到它的内部是由一个个segment<K,V>组成的segments,而segment<K,V>中又维持着一个table数组,这个数组又是由HashEntry<K,V>对象组成的,也就是我们平时我们put进去的key、value都是在这个table数组中存放着。segment也就是前言中提到的分段,它将一个个键值存放在不同的Segment中,这样当线程对其访问是相互独立的,互不受影响,这样就间接的避免了并发的问题。熟悉的基本结构,我们来走进它的源码,剖析一下它的底层实现吧:
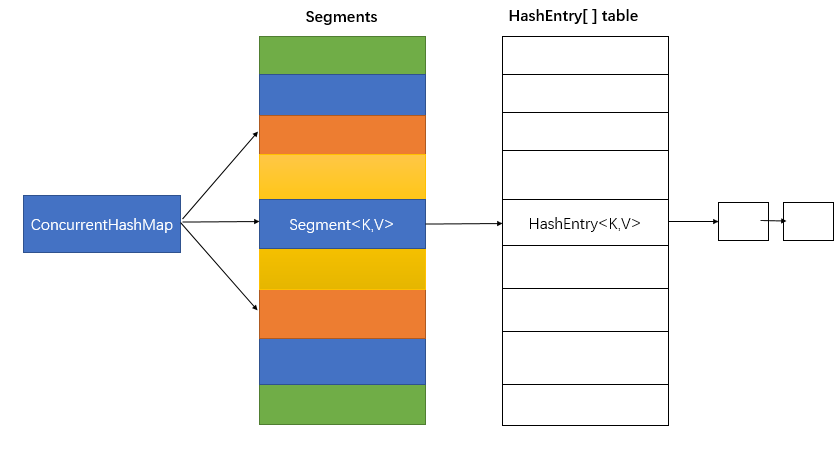
二:concurrentHashMap的内部实现
2.1:ConcurrentHashMap的成员变量
private static final long serialVersionUID = 7249069246763182397L;
static final int DEFAULT_INITIAL_CAPACITY = 16;//默认的初始化容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认的加载因子
static final int DEFAULT_CONCURRENCY_LEVEL = 16;//默认的并发级别
static final int MAXIMUM_CAPACITY = 1 << 30;//最大的容量
static final int MAX_SEGMENTS = 1 << 16;//最大的片组数
static final int RETRIES_BEFORE_LOCK = 2;//上锁前重试次数
final int segmentMask;//段掩码
final int segmentShift;//段偏移量
final Segment<K,V>[] segments;//分段数组
transient Set<K> keySet;//键集合
transient Set<Map.Entry<K,V>> entrySet;//键值对集合
transient Collection<V> values;//值集合
其中可以看到很多是final修饰的,final的作用就是为了保证它不被修改,维护一个常量的好处就是这个值是固定的,至于具体数据比如为什么加载因子是16而不是15,这都是通过科学计算过来的,这里不作深究。还有很多是transient修饰的,它的作用就是保证了不会被序列化。它封装了一个segments数组,其中的每一个元素就是上图中画到的Segment<K,V>了。下面我们来看看Segment,它在concurrentHashMap中是以内部类的形式出现的:
2.2:segment的实现
static final class Segment<K,V> extends ReentrantLock implements Serializable {//分段部分,也是基于键值对形式的
private static final long serialVersionUID = 2249069246763182397L;//序列号id
transient volatile int count;//计数
transient int modCount;//修改次数
transient int threshold;//扩容临界值
transient volatile HashEntry<K,V>[] table;//HashEntry数组
final float loadFactor;//加载因子
可以看到segment继承自ReentrantLock,它内部维持着一个HashEntry数组,注意到这个这个数组是用volatile修饰的。关于volatile,它的作用主要有两个①:当线程在工作内存中将数据修改的时候,它会迫使该变量数据同步到共享内存里,这样其他线程可以立马看到这个值的变化。以至于不会出现数据更新不及时这种问题。②:防止cpu指令重排序,防止过度优化,导致的线程同步问题。table的主要作用用于封装我们的key、value键值对。还有几个用于全局维护的变量,譬如修改次数、计数等等。说到这里,我们再来看一个很重要的方法:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
这个方法是根据hash值去segments数组中找到具体的子节点,我们只到map再放入数组中不可避免的会出现一个哈希冲突的问题。这个问题蛮令人头疼的,而一个设计良好的map的会采用优秀的算法,让数据均匀散落在数组中,避免出现不用的hash值对应同一个节点,那么就会在此节点上形成一个链表,而一旦这样,我们在调用get方法的时候会出现额外的性能消耗,这都是设计者不愿看到的,所以采用了这个算法,提出了分段偏移量(segmentShift)和分段掩码(segmentMask)的概念,经过hash与分段偏移量进行三位运算,再加上&与分段掩码的计算,从而高效的在segments中找到其中的位置。
我们再顺藤摸瓜,来看看HashEntry的实现:
2.3:HashEntry的实现
static final class HashEntry<K,V> {//HashEntry内部对象,用于封装键值对
final K key;//键
final int hash;//hash值
volatile V value;//值
final HashEntry<K,V> next;//指向下一个键值映射对象
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {//构造方法
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
可以看到它其实是一个数组+链表的结构,里面有一个next指针指向下一个节点。熟悉HashMap的童鞋都知道,它是数组+链表的结构,之所以是这样的结构,主要的目的是为了解决Hash冲突。而HashEntry,也是同样的目的。这个在下面的源码分析中很容易看出来。
2.4:concurrentHashMap的构造方法
public ConcurrentHashMap(int initialCapacity, float loadFactor) {//构造初始化容量和加载因子
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {//构造初始化容量
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);//调用默认的三个参数的构造方法
}
public ConcurrentHashMap() {//无参构造方法
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);//调用默认的三个参数的构造方法,构造进去默认的初始化容量、默认的加载因子、默认的并发级别
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {//用map作为参数形成构造方法
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);//调用putAll方法
}
public ConcurrentHashMap(int initialCapacity, //ConcurrentHashMap的构造方法,构造初始化容量、加载因子、并发级别
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)//如果加载因子小于0或者初始化容量小于0或者并发级别小于0
throw new IllegalArgumentException();//抛出参数违法异常
if (concurrencyLevel > MAX_SEGMENTS)//如果并发级别大于最大的分段锁数
concurrencyLevel = MAX_SEGMENTS;//把并发级别设置为最大分段锁数
// Find power-of-two sizes best matching arguments
int sshift = 0;//设置偏移量0
int ssize = 1;//设置数组大小默认为1
while (ssize < concurrencyLevel) {//如果大小小于并发级别
++sshift;//偏移量+1
ssize <<= 1;//size大小乘以2
}
segmentShift = 32 - sshift;//片段偏移量等于32减去设置的偏移量
segmentMask = ssize - 1;//分段掩码等于size-1
this.segments = Segment.newArray(ssize);//构造分段,用传入的ssize去创建新的数组返回ConcurrentHashMap的成员变量
if (initialCapacity > MAXIMUM_CAPACITY)//如果初始化容量大于最大的容量
initialCapacity = MAXIMUM_CAPACITY;//将最大容量设置为初始化容量
int c = initialCapacity / ssize;//设置一个值为初始化容量除以大小
if (c * ssize < initialCapacity)//如果这个值乘以ssize小于初始化容量
++c;//c进行+1操作
int cap = 1;//定义一个cap为1
while (cap < c)//判断cap和c的值,如果c大于1
cap <<= 1;//cap乘以2
for (int i = 0; i < this.segments.length; ++i)//遍历循环其中的分段
this.segments[i] = new Segment<K,V>(cap, loadFactor);//利用cap和加载因子计算出最合适的片组长度
}
一共有四个构造方法,其中前3个调用的都是最后一个,由上面的代码可知segments数组的长度ssize通过concurrencyLevel计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14,15或16,ssize都会等于16,即容器里锁的个数也是16。注意concurrencyLevel的最大大小是65535,意味着segments数组的长度最大为65536,对应的二进制是16位。初始化segmentShift和segmentMask。这两个全局变量在定位segment时的哈希算法里需要使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与hash运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的,后面的测试中我们可以看到这点。segmentMask是哈希运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。初始化每个Segment。输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment。
三:总结
本篇博客主要介绍了concurrentHashMap的结构、成员变量、构造方法,让我们对concrrent有一个大概的认识,这个集合在高并发的容器中使用频率是非常高的,对此我们算有了一个基本的认识。而下一篇博客将会对其的并发访问,put、get方法做一定深入的研究,详情请看ConcurrentHashMap源码分析(二)。
ConcurrentHashMap源码分析(一)的更多相关文章
- Hashtable、ConcurrentHashMap源码分析
Hashtable.ConcurrentHashMap源码分析 为什么把这两个数据结构对比分析呢,相信大家都明白.首先二者都是线程安全的,但是二者保证线程安全的方式却是不同的.废话不多说了,从源码的角 ...
- ConcurrentHashMap 源码分析
ConcurrentHashMap 源码分析 1. 前言 终于到这个类了,其实在前面很过很多次这个类,因为这个类代码量比较大,并且涉及到并发的问题,还有一点就是这个代码有些真的晦涩,不好懂.前前 ...
- 死磕 java集合之ConcurrentHashMap源码分析(三)
本章接着上两章,链接直达: 死磕 java集合之ConcurrentHashMap源码分析(一) 死磕 java集合之ConcurrentHashMap源码分析(二) 删除元素 删除元素跟添加元素一样 ...
- 并发-ConcurrentHashMap源码分析
ConcurrentHashMap 参考: http://www.cnblogs.com/chengxiao/p/6842045.html https://my.oschina.net/hosee/b ...
- ConcurrentHashMap源码分析(1.8)
0.说明 1.ConcurrentHashMap跟HashMap,HashTable的对比 2.ConcurrentHashMap原理概览 3.ConcurrentHashMap几个重要概念 4.Co ...
- java基础系列之ConcurrentHashMap源码分析(基于jdk1.8)
1.前提 在阅读这篇博客之前,希望你对HashMap已经是有所理解的,否则可以参考这篇博客: jdk1.8源码分析-hashMap:另外你对java的cas操作也是有一定了解的,因为在这个类中大量使用 ...
- 死磕 java集合之ConcurrentHashMap源码分析(一)
开篇问题 (1)ConcurrentHashMap与HashMap的数据结构是否一样? (2)HashMap在多线程环境下何时会出现并发安全问题? (3)ConcurrentHashMap是怎么解决并 ...
- 多线程高并发编程(10) -- ConcurrentHashMap源码分析
一.背景 前文讲了HashMap的源码分析,从中可以看到下面的问题: HashMap的put/remove方法不是线程安全的,如果在多线程并发环境下,使用synchronized进行加锁,会导致效率低 ...
- [JUC-5]ConcurrentHashMap源码分析JDK8
在学习之前,最好先了解下如下知识: 1.ReentrantLock的实现和原理. 2.Synchronized的实现和原理. 3.硬件对并发支持的CAS操作及JVM中Unsafe对CAS的实现. 4. ...
随机推荐
- Oracle_insert_delete_update
Oracle_insert_delete_update --复制表格的结构 create table temp as (select * from emp where 1=2); select * f ...
- Linux环境JDK安装
Java的编程离不开jdk,今天本文主要讲下Linux下的JDK安装与配置 1.卸载Linux自带的JDK #检测jdk安装包 [root@localhost ~]# rpm -qa | grep j ...
- DEDECMS万能标签{dede:sql}使用教程详解
http://www.dede58.com/a/dedebq/2015/0226/1737.html 1.首页在后台单页文档管理里添加一个单页文档,内容编辑框输入你要的内容生成. 2.在需要调用单页文 ...
- destoon标签
http://blog.csdn.net/oYuHuaChen/article/details/54601509 ------------
- Linux IO时事检测工具iostat
Linux IO时事检测工具iostat iostat命令用于检测linux系统io设备的负载情况,运行iostat将显示自上次运行该命令以后的统计信息.用户可以通过指定统计的次数和时间来获得所需的统 ...
- 动态添加div及对应的js、css文件
动态添加div及对应的js.css文件 在近期的项目开发中需要在首页中添加很多面板型的div,直接加载代码显得很繁琐,于是利用js封装一个动态添加div及其对应css文件和js文件的方法供大家参考使用 ...
- 【故障】MySQL主从同步故障-Slave_SQL_Running: No
转自:http://www.linuxidc.com/Linux/2014-02/96945.htm 故障现象:进入slave服务器,运行:mysql> show slave status\G ...
- spring bean中子元素lookup-method和replaced-method
lookup-method 示例: 步骤一:定义一个Car类 package org.hope.spring.bean.lookup; public class Car { private Strin ...
- 递归演示程序(swift)
//: Playground - noun: a place where people can play import UIKit var str = "Hello, playground& ...
- HttpClient方式调用接口的实例
使用HttpClient的方式调用接口的实例. public class TestHttpClient { public static void main(String[] args) { // 请求 ...