【Python3爬虫】常见反爬虫措施及解决办法(一)
这一篇博客,是关于反反爬虫的,我会分享一些我遇到的反爬虫的措施,并且会分享我自己的解决办法。如果能对你有什么帮助的话,麻烦点一下推荐啦。
一、UserAgent
import requests url = "http://www.baidu.com"
res = requests.get(url)
代码很简单,就是一个发送请求的代码。运行之前打开Fiddler,然后运行代码,在Fiddler中找到我们发送的请求,就可以看到有如下内容:

这时候我们的UserAgent字段的值就是python-requests/2.18.4,很显然这不是一个浏览器的UserAgent,而这样的UserAgent很容易就被识别出来,所以我们在编写爬虫的时候一定要注意添加UserAgent。然后对于一些网站,如果我们一直使用同一个UserAgent去访问,频率高了之后也会被ban掉,这个时候就需要使用随机的UserAgent了。
解决办法:
1.收集整理常见的UserAgent以供使用
ua_list =
["Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"MQQBrowser/25 (Linux; U; 2.3.3; zh-cn; HTC Desire S Build/GRI40;480*800)",
"Mozilla/5.0 (Linux; U; Android 2.3.3; zh-cn; HTC_DesireS_S510e Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (SymbianOS/9.3; U; Series60/3.2 NokiaE75-1 /110.48.125 Profile/MIDP-2.1 Configuration/CLDC-1.1 ) AppleWebKit/413 (KHTML, like Gecko) Safari/413",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Mobile/8J2",
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/534.51.22 (KHTML, like Gecko) Version/5.1.1 Safari/534.51.22",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; SAMSUNG; OMNIA7)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; XBLWP7; ZuneWP7)",
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 60; Windows NT 5.1; SV1; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)"]
2.使用第三方库--fake_useragent
使用方法如下:
from fake_useragent import UserAgent ua = UserAgent()
for i in range(3):
print(ua.random)
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
# Mozilla/5.0 (X11; Linux i686; rv:21.0) Gecko/20100101 Firefox/21.0
二、IP
对于一些网站来说,如果某个IP在单位时间里的访问次数超过了某个阈值,那么服务器就会ban掉这个IP了,它就会返回给你一些错误的数据。一般来说,当我们的IP被ban了,我们的爬虫也就无法正常获取数据了,但是用浏览器还是可以正常访问,但是如果用浏览器都无法访问,那就真的GG了。很多网站都会对IP进行检测,比如知乎,如果单个IP访问频率过高就会被封掉。
解决办法:
使用代理IP。网上有很多免费代理和付费代理可供选择,免费代理比如:西刺代理、快代理等等,付费代理比如:代理云、阿布云等等。除此之外,我们还可以建一个属于自己的代理池以供使用,这里可以参考下我的上一篇博客。
三、Referer防盗链
防盗链主要是针对客户端请求过程中所携带的一些关键信息来验证请求的合法性,而防盗链又有很多种,比如Referer防盗链、时间戳防盗链等等,这里只讲Referer防盗链。Referer用于告知服务器该请求是从哪个页面链接过来的,比如我们先打开少司命的百度百科:
然后打开开发者工具,再查看右侧的图片,能找到如下内容,这里Referer字段就表明我们是从什么页面跳转过去的:

但是如果我们直接在浏览器中输入url查看图片的话,是没有Referer的:

这里本来有一个例子的,就是妹子图:https://www.mzitu.com,不过现在无法访问了。这个网站的图片就使用了Referer防盗链,如果我们的爬虫没有携带符合要求的Referer字段,就会被识别出来。虽然我们请求的链接是没有问题的,但是因为没有Referer字段,它就不会把真正的图片返回给我们。
解决办法:
在请求头headers中添加Referer字段以及相应的值。
四、在html中动手脚
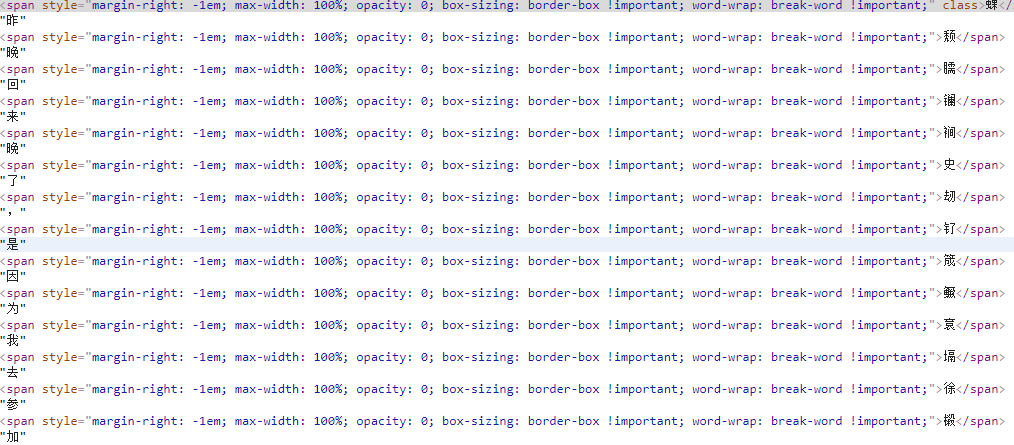
首先我不得不佩服那些前端工程师们,为了反爬虫真是想了不少办法,比如JS加密啊JS混淆啊,真是搞得人头大。不过我们这里先说那些在html中动手脚的,比如加一些无意义的字符之类的,这样即使我们能爬下来,得到的数据也是没法使用的。比如部分微信公众号的文章里会穿插一些乱七八糟的字符,这里用这篇文章作为例子:
解决办法:
可以看到每个字前面都加了一个span标签,span标签里加入了一个用于干扰的字符,而且有的还使用了strong标签,这就给我们的解析增加了难度。这里我使用的是lxml解析,解析完之后再对数据做一下清洗,完整代码如下:
import requests
from lxml import etree url = "https://mp.weixin.qq.com/s?__biz=MzI0MDYwNjk2OA==&mid=2247484365&idx=4&sn=291a93e8a4ce6e90d3b6ef8b98fe09c4&chksm=e919085ade6e814cc037ecf6a873f22da0e492911a4e539e6f8fdeff022806b4d248c4d54194&scene=4"
res = requests.get(url)
et = etree.HTML(res.text)
lst = et.xpath('//*[@id="js_content"]/p//text()')
lst = [lst[i] for i in range(1, len(lst), 2)]
text = ''.join(lst)
print(text)
【Python3爬虫】常见反爬虫措施及解决办法(一)的更多相关文章
- Python爬虫与反爬虫(7)
[Python基础知识]Python爬虫与反爬虫(7) 很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧 这节我会做个基本分享. 从功能上来讲,爬虫一般分为数据采集,处理, ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- 【Python】爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性) 目录 随机User-Agent 获取代理ip 检测代理ip可用性 随机User-Agent fake_usera ...
- Python爬虫入门教程 65-100 爬虫与反爬虫的修罗场,点评网站,字体反爬之三
爬虫与反爬虫的修罗场 哪种平台最吸引爬虫爱好者,当然是社区类的,那里容易产生原生态,高质量的数据啊, 你看微博,知乎,豆瓣爬的不亦乐乎. 评论也是产生内容的好地方 生活类点评网站 旅游类点评网站 音乐 ...
- C#爬虫与反爬虫--字体加密篇
爬虫和反爬虫是一条很长的路,遇到过js加密,flash加密.重点信息生成图片.css图片定位.请求头.....等手段:今天我们来聊一聊字体: 那是一个偶然我遇到了这个网站,把价格信息全加密了:浏览器展 ...
- C#不用union,而是有更好的方式实现 .net自定义错误页面实现 .net自定义错误页面实现升级篇 .net捕捉全局未处理异常的3种方式 一款很不错的FLASH时种插件 关于c#中委托使用小结 WEB网站常见受攻击方式及解决办法 判断URL是否存在 提升高并发量服务器性能解决思路
C#不用union,而是有更好的方式实现 用过C/C++的人都知道有个union,特别好用,似乎char数组到short,int,float等的转换无所不能,也确实是能,并且用起来十分方便.那C# ...
- 【Python3爬虫】常见反爬虫措施及解决办法(二)
这一篇博客,还是接着说那些常见的反爬虫措施以及我们的解决办法.同样的,如果对你有帮助的话,麻烦点一下推荐啦. 一.防盗链 这次我遇到的防盗链,除了前面说的Referer防盗链,还有Cookie防盗链和 ...
随机推荐
- Java设计模式之《适配器模式》及应用场景
转自https://www.cnblogs.com/V1haoge/p/6479118.html 适配器就是一种适配中间件,它存在于不匹配的二者之间,用于连接二者,将不匹配变得匹配,简单点理解就是平常 ...
- bzoj3811 玛里苟斯
分三种情况讨论 k=1时,对于每一位而言,只要有一个数这一位是1,那么这个就有0.5的概率是1,选他就是1,不选就是0,有第二个的话,在第一个选或不选的前提下,也各有0.5的几率选或不选,0和1的概率 ...
- 【强连通分量+概率】Bzoj2438 杀人游戏
Description 一位冷血的杀手潜入 Na-wiat,并假装成平民.警察希望能在 N 个人里面,查出谁是杀手. 警察能够对每一个人进行查证,假如查证的对象是平民,他会告诉警察,他认识的人, 谁是 ...
- 用Fundebug插件记录网络请求异常
在服务端,不管我们使用Node.js.Java.PHP还是Python等等,都会用日志以文本的形式记录请求以及报错信息.这个对于后端做事后分析是很有用的. 另一方面,前端有时候出问题其实是因为后端接口 ...
- Ubuntu18.04 Desktop Entry
1.Desktop Entry 是什么? 我们都知道,在Windows里软件在安装的时候都会询问是不是要在开始菜单和桌面创建快捷方式,这样就不用在使用软件的时候去安装目录启动,而是直接去开始菜单点击相 ...
- 操作系统--进程管理(Processing management)
一.进程的组成 进程通常由程序.数据和进程控制块(Process Control Block,PCB)组成. 二. 进程的状态以及状态切换 进程执行时的间断性决定了进程可能具有多种状态,最基本的三种状 ...
- COGS2421 [HZOI 2016]简单的Treap
题面见这里 大概是个模板题 Treap暴力插入的做法太暴力了并不优美 这里就需要用到笛卡尔树的构造方法,定义见这里 在 假的O(n) 的时间内构造一棵Treap 把元素从小到大排序 这样从小到大插入时 ...
- python 小练习题做起来
1# 有两个磁盘文件A和B,各存放一行字母,要求把这两个文件中的信息合并# (按字母顺序排列), 输出到一个新文件C中.with open('a') as f1: a=f1.read()with op ...
- 哪些类继承了Collection接口
Collection集合的基本结构: 1.Collection接口 Collection是最基本集合接口,它定义了一组允许重复的对象.Collection接口派生了两个子接口Set和List, ...
- 来聊一聊不low的Linux命令——find、grep、awk、sed
前几天面试,被一位面试官嫌弃了"你的Linux命令有点low".被嫌弃也挺正常的,因为我的简历写的我自己都有点看不下去:了解Linux常用命令,如ls,tail -f等命令,基本满 ...