文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型。回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示。首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的向量。这样每个文本在分词之后,就可以根据我们之前得到的词袋,构造成一个向量,词袋中有多少个词,那这个向量就是多少维度的了。然后就把这些向量交给计算机去计算,而不再需要文本啦。而向量中的数字表示的是每个词所代表的权重。代表这个词对文本类型的影响程度。
在这个过程中我们需要解决两个问题:1.如何计算出适当的权重。2.如何把词袋给缩小,后面会说到的其实就是降维的思想
先来解决第一个问题:如何计算权重?
上篇说过,使用词频来计算权重是个没什么人去用的方法。而我们大都会使用地球人都知道的算法:TF/IDF
TF/IDF 用来评估一个词在训练集中对某个文本的重要程度。其中TF表示的是某个词在文本中出现的频率也就是词频啦,用公式表示就是:
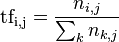
那IDF是什么呢?IDF叫做逆向文件频率: 计算公式是:
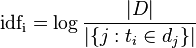
|D| 表示训练集的总文档数|{j:t¡Εdj}|表示包含词ti的所有文档
一般由于|{j:t¡Εdj}|可能会为0,所以分母+1,这么表示:

意思就是文档总数除以包含该词的文档数再取对数。具体意思是啥呢,就是说如果包含某个词的文档很少很少,那么这个词就非常具有区分度。这个道理很好理解,大多数文章都会包含"的" ,而大部分关于搜索引擎的文章才会包含"索引",那么"索引"这个词就比"的"更具有区分度。
而TF/IDF的方法是将TF/IDF结合起来也就是TF*IDF 的值越大,代表这个词的权重就越大,这个词对于文档来说就越重要。所以一个词在某个文档中的出现次数越大,而在别的文档中出现的次数又很少,这个时候就会得出一个很高的权重了。
而在搜索引擎中对文档的排序也有用到TF/IDF方法。
这样的话我们就可以得到一个TF/IDF权重的表示的向量。但是词袋(字典)向量的维度是在太高了,有几万维,很浪费计算机的资源。 高纬度的特征向量中每一维都可以看做是特征(特征也可以用词来表示,其实就是组成文章的一个一个词)。接下来就要介绍特征提取这个概念。我们从高维度特征向量中选取最具代表性的一些特征,从而达到把维度降低的同时也可以很好预测文章的类型。所以特征提取就可以叫做降维。一个维度不高,又能很好预测文章的词袋我们何乐而不为呢?
那么特征提取总体上来说有两类方法:
第一类可以称作特征抽取,它的思想是通过特征之间的关系,组合不同的特征得到新的特征,这样就改变了原始的特征空间,构成了新的特征。而新的特征更具有代表性,并消耗更少的计算机资源。主要方法有:
1.主成成分分析(PCA)
2.奇异值分解
3.Sammon映射
第二类叫做特征选择,它的思想是在原有的特征集合中选出一个更具代表性的子集,主要方法有三类:
1. 卡方检验,信息增益 通过给每一维的特征进行打分,然后进行排序,选择那些排名靠前的特征
2. 递归特征消除算法 将子集的选择看做是一个搜索优化的问题,通过启发式的搜索优化算法来解决
3. 岭回归 确定模型的过程中,挑选出那些对模型的训练有重要意义的属性
后面会对卡方检验和信息增益以及主成成分进行学习和讨论。再见咯。
文本分类学习(三) 特征权重(TF/IDF)和特征提取的更多相关文章
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 文本分类学习(六) AdaBoost和SVM
直接从特征提取,跳到了BoostSVM,是因为自己一直在写程序,分析垃圾文本,和思考文本分类用于识别垃圾文本的短处.自己学习文本分类就是为了识别垃圾文本. 中间的博客待自己研究透彻后再补上吧. 因为获 ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的.因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来. 所以要理解SVM ...
- 文本分类学习 (九)SVM入门之拉格朗日和KKT条件
上一篇说到SVM需要求出一个最小的||w|| 以得到最大的几何间隔. 求一个最小的||w|| 我们通常使用 来代替||w||,我们去求解 ||w||2 的最小值.然后在这里我们还忽略了一个条件,那就是 ...
- 文本分类——NaiveBayes
前面文章已经介绍了朴素贝叶斯算法的原理,这里基于NavieBayes算法对newsgroup文本进行分类測试. 文中代码參考:http://blog.csdn.net/jiangliqing1234/ ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
随机推荐
- 无后台应用 Stash Backend
Stash Backend 是Github上的开源项目 https://github.com/gaboratorium/stash,目的在于提供一套方便使用.方便部署的后台应用.特别适合为Web前端和 ...
- RestSharp 一个.NET(C#)的HTTP辅助类组件
互联网上关于.NET(C#)的HTTP相关的辅助类还是比较多的,这里再为大家推荐一个.NET的HTTP辅助类,它叫RestSharp.RestSharp是一个轻量的,不依赖任何第三方的组件或者类库的H ...
- [转]ICE介绍 (RFC 5245)
[转]ICE介绍 (RFC 5245) http://blog.csdn.net/dxpqxb/article/details/22040017 1关于ICE的10个事实 1 ICE使用STUN和TU ...
- GitHub起步---创建第一个项目
---恢复内容开始--- 刚起步学习GitHub,边学边说! {参考教程:http://blog.csdn.net/steven6977/article/details/10567719}这里描述的很 ...
- luogu3244 bzoj4011 HNOI2015 落忆枫音
这道题目题面真长,废话一堆. 另外:这大概是我第一道独立做出来的HNOI2011年以后的题目了吧.像我水平这么差的都能做出来,dalao您不妨试一下自己想想? 题目大意:给一个DAG,其中1号点没有入 ...
- webpack学习(六)打包压缩js和css
打包压缩js与css 由于webpack本身集成了UglifyJS插件(webpack.optimize.UglifyJsPlugin)来完成对JS与CSS的压缩混淆,无需引用额外的插件, 其命令we ...
- python全栈开发-Day5 元组、字典
python全栈开发-Day5 元组.字典 一.前言 首先,不管学习什么数据类型,我们都带着以下几个问题展开学习: #1:基本使用 1 .用途 2 .定义方式 3.常用操作+内置的方法 #2:该类型 ...
- Navicat通过跳板机连接数据库
完成对应设置后,即可连接数据库,本人亲测!
- Ubuntu修改密码之后无法登录
问题:Ubuntu修改密码之后无法登录,停留在登录界面,输入正确的密码之后,画面一闪又回到了登录界面. 解决:ctrl+alt_f1进入终端,输入用户名和密码,$cd /home/userXXX &a ...
- NGUI_slider
十一.进度条UISlider 1.一般按以下规律使用进度条; 如果某一钟值,他有最大值,需要表达当前的值得占比,则可以使用不可拖动的进度条 如果某一值,他有最大值,需要玩家记性滑动设置,则可以使用可拖 ...