[DeeplearningAI笔记]ML strategy_1_2开发测试集评价指标
机器学习策略 ML strategy
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.4 满足和优化指标
Stisficing and optimizing metrics
- 有时候把你要考虑的所有事情组合成单实数评估指标,有时候并不容易,这时候使用满足和优化指标很重要.
- 假设以下是一个猫分类器,在我们已经考虑准确度的情况下,我们还要考虑运行时间(即区分一张猫图片所用的时间)
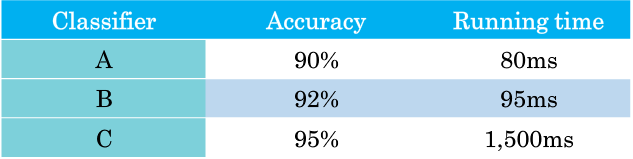
- 我们的做法是在满足运行时间的条件下,最大限度的提高准确度.例如我们这里选取运行时间必须满足小于100ms的条件,达到最大的准确度.即我们会选择满足条件的B分类器.
- 此时我们就成 准确度 是一个优化指标, 运行时间 是一个 满足指标
- 再举一个在 语音识别唤醒 中的例子, 优化指标是唤醒率(即输入语音后进行唤醒成功的概率,在用户说出唤醒词后,设备能够最大可能性的被唤醒) , 满足指标是"假阳性概率",即设备被用户意外唤醒的概率,这个只需要满足小于一天之内被唤醒一次就够了,即是一个(满足指标) .
1.5 训练/开发/测试集划分
- dev集也叫做开发集(development set)有时也被称为保留交叉验证集(hold out cross validation set).
- 在机器学习中的开发流程是:尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善模型在开发集上的性能直到你在开发集上的cost function的到的结果令你满意,然后再用测试集去评估这个模型.
dev set(开发集)和单实数评估指标就是机器学习团队开发的目标,这个目标必须足够准确,并且开发集和测试集一定得来自同一数据分布,应该将获得的所有数据随机的平均分布到开发集和测试集中,避免测试集测试模型时和开发集优化模型时的目标效果不统一.
1.6 开发集和测试集的大小
- 在机器学习的早期时代,我们的数据集数量只有 几千个 或者 几万个 这时候我们划分数据集的方式一般为:
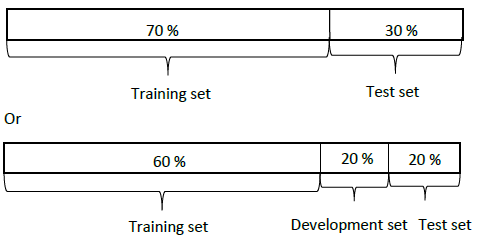
- 但是现在数据集一般在100万的数据集及以上,我们不必使用大规模的数据去构成开发集和测试集.假如我们现在有100万条数据,我们只需要取出2%的数据来构成开发集和测试集.
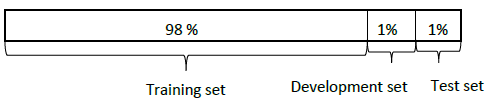
经验法则
- 如果你对最终投产的系统有一个很精确的指标,需要大量的数据.如果你的应用不需要很高的置信度,测试集不需要海量数据.
- 测试集可以帮助评估最终分类器的性能,取决于总体的数据量.如果总体数据量很大,测试集会少于数据集的30%.
- 开发集要足够大能够测试不同的模型.
1.7什么时候需要改变开发集/测试集和评价指标
cat dataset example
- 假设你的产品是一个猫分类器,指定的指标是分类误差(classification error) .以下展示算法A和算法B的误差率.
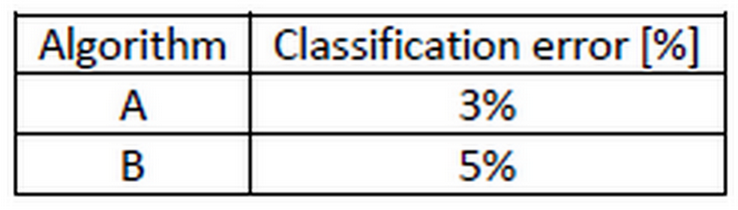
- 从评价指标和开发集的角度来看,我们应该选择A模型,但是某种原因,A算法会让更多的Pron图片通过识别.即是在这个指标中A算法看起来更好,但是在产品实际运用中,公司和用户更加青睐于B种方案.因为B方案没有Pron图片会通过. 在这个例子中我们发现,B算法其实优于A算法,而评价指标没有发挥应有的作用.
- 因此,在这个例子中,我们需要更改评价指标,以及更新开发集和测试集.
- 原有的误差率函数为:
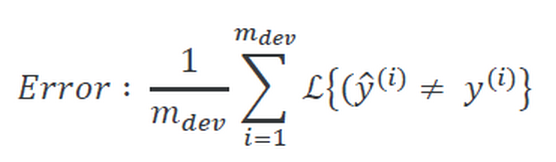
这表示的是开发集上经过归一化后的误差率.
- 原有评价指标的缺点在于:将Pron图片和非Pron图片平等对待,我们解决这个问题的方法可以是,将Pron图片加上更高的误差权重.
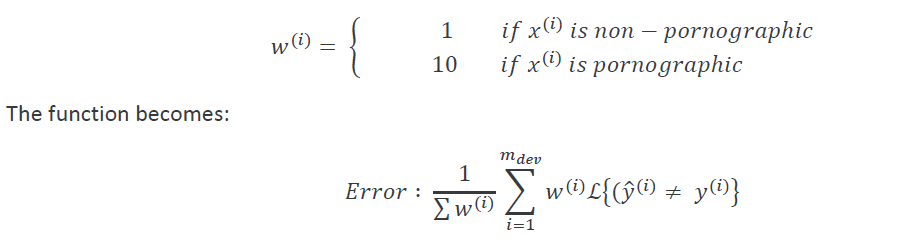
经验法则
- 对于评价指标的选取和训练的过程实际上遵循正交化的原则,即先指定一个评价指标,然后使算法在开发集和测试集上的表现越来越好.在实际的运用中,如果出现适应性问题,再修改评价指标和适当的改变开发集和测试集.
- 总体上说你当前的开发测试集和评价指标和你真正关心必须做好的事情关系不大,我们真正应该关注的是实际应用中你需要处理好的用户数据.通过实际中的表现调整开发测试集合评价指标,让他们更好的反应你真正需要处理好的数据.
- 有一个评估指标和开发集让你可以更快的作出决策,判断算法A还是算法B更优,这真的可以加速你和你的团队迭代的速度.所以即使你当前无法定义一个很完美的评估指标和开发集,你可以直接快速设立出来,然后使用它们来驱动你们的团队的迭代速度.在这之后,如果你发现选的不好,你有更好的想法,那么完全可以马上修改.对于大多数团队建议不要在没有评估指标和开发集时跑太久.因为这样会减慢你的团队的迭代和改善算法的速度.
[DeeplearningAI笔记]ML strategy_1_2开发测试集评价指标的更多相关文章
- [DeeplearningAI笔记]ML strategy_2_2训练和开发/测试数据集不匹配问题
机器学习策略-不匹配的训练和开发/测试数据 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.4在不同分布上训练和测试数据 在深度学习时代,越来越多的团队使用和开发集/测试集不同分布的数据来 ...
- [DeeplearningAI笔记]ML strategy_1_1正交化/单一数字评估指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 什么是ML策略 机器学习策略简介 情景模拟 假设你正在训练一个分类器,你的系统已经达到了90%准确 ...
- [DeeplearningAI笔记]ML strategy_1_3可避免误差与改善模型方法
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.8 为什么是人的表现 今天,机器学习算法可以与人类水平的表现性能竞争,因为它们在很多应用程序中更有生产 ...
- [DeeplearningAI笔记]ML strategy_2_1误差分析
机器学习策略-误差分析 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 误差分析 训练出来的模型往往没有达到人类水平的效果,为了得到人类水平的结果,我们对原因进行分析,这个过程称为误差 ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- [DeeplearningAI笔记]ML strategy_2_4端到端学习
机器学习策略-端到端学习 End-to-end deeplearning 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9 什么是端到端学习-What is End-to-end dee ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- RGMII_PHY测试笔记1 基于开发板MiS603-X25
RGMII_PHY测试笔记1 基于开发板MiS603-X25 作者:汤金元 日期:20150817 公司:南京米联电子科技有限公司 博客:http://blog.chinaaet.com/detail ...
- ML基础 : 训练集,验证集,测试集关系及划分 Relation and Devision among training set, validation set and testing set
首先三个概念存在于 有监督学习的范畴 Training set: A set of examples used for learning, which is to fit the parameters ...
随机推荐
- BZOJ 1800: [Ahoi2009]fly 飞行棋【思维题,n^4大暴力】
1800: [Ahoi2009]fly 飞行棋 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1689 Solved: 1335[Submit][St ...
- Graph(Floyd)
http://acm.hdu.edu.cn/showproblem.php?pid=4034 Graph Time Limit: 2000/1000 MS (Java/Others) Memor ...
- C语言函数的作用域规则
“语言的作用域规则”是一组确定一部分代码是否“可见”或可访问另一部分代码和数据的规则. “同一函数中,不同的结构体成员名能相同,当变量处于不同的作用域时,名称可以相同. 注:作用域,其对象是变量, ...
- Thinking in Java学习笔记-泛型和类型安全的容器
示例: public class Apple { private static long counter; private final long id = counter++; public long ...
- 来说说datatype
今天敲代码一直卡在一个问题上面好久那就是--datatype的未定义,起初不晓得datatype的含义,遇到这种情况首先想到的就是自己又忘记加上面头文件了.随即写了个stdlib.h上去.可是问题并没 ...
- Linux下C++/C的编译调试
这几天因为任务的原因我需要在ubuntu下编写程序.因此恶补了许多linux程序编写的知识.我分以下几个方面总结我所学的知识. gcc,g++,make命令的使用 gdb 调试 VScode的使用 c ...
- 注意SSIS中的DT_NUMERIC类型转换为字符类型(比如DT_WSTR)时,会截断小数点前的0
我们知道SSIS中有许多数据类型,如下图所示: 但是DT_NUMERIC这个类型有个陷进要注意,我们来做个实验,随便定义一个String类型的SSIS包变量,然后打开该变量表达式窗口: 在变量表达式窗 ...
- nginx 防火墙、权限问题
1.nginx安装,配置完成之后,尝试访问没有响应,主机可以ping通,/var/log/nginx/access.log日志没有查到任何记录 解决方法:查看linux防火墙,关闭 命令:ipta ...
- ASP.NET Core下发布网站
一.windows下发布到IIS 1.前奏:IIS上的准备 (1)IIS 必须安装AspNetCoreModule 模块 下载地址:(DotNetCore.2.0.3-WindowsHosting-a ...
- hasResultError
hasResultError 的作用是 让返回的对象可以报错误信息.