【Network】优化问题——Label Smoothing
滴:转载引用请注明哦【握爪】https://www.cnblogs.com/zyrb/p/9699168.html
今天来进行讨论深度学习中的一种优化方法Label smoothing Regularization(LSR),即“标签平滑归一化”。由名字可以知道,它的优化对象是Label(Train_y)。
对于分类问题,尤其是多类别分类问题中,常常把类别向量做成one-hot vector(独热向量)。
简单地说,就是对于多分类向量,计算机中往往用[0, 1, 3]等此类离散的、随机的而非有序(连续)的向量表示,而one-hot vector 对应的向量便可表示为[0, 1, 0],即对于长度为n 的数组,只有一个元素是1,其余都为0。
之后在网络的最后一层(全连接层)后加一层softmax层,由于softmax输出是归一化的,所以认为该层的输出就是样本属于某类别的概率。而由于样本label是独热向量,因此表征我们已知样本属于某一类别的概率是为1的确定事件,属于其他类别的概率则均为0。
【一】、首先明确一些变量的含义:
$z_i$:也为logits,即未被归一化的对数概率;
$p$:predicted probability,预测的example的概率;
$q$:groundtruth probablity,真实的example的label概率;对于one-hot,真实概率为Dirac函数,即$q(k)=δ_{k,y}$,其中y是真实类别。
$loss$:Cross Entropy,采用交叉熵损失。
softmax层的输出预测概率为:\begin{equation} p(k|x)=\frac{exp(z_k)}{\sum_{i}^{i=K}exp(z_i)} \end{equation}
交叉熵损失表示为:\begin{equation}loss=−\sum_{k=1}^{K}q(k|x)log(p(k|x)) \end{equation}
对于logits,交叉熵是可微分的,偏导数的形式也较为简单:$\frac{∂loss}{∂zk}=p(k)−q(k)$(对于$p,q ∈[0, 1]$, 可以知道梯度是有界的∈[-1, 1])
【二】、one-hot 带来的问题
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:1)无法保证模型的泛化能力,容易造成过拟合;2) 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
【三】、解决方案
为了使得模型less confident,提出以下机制: ,将$q(k)$函数改为$q(k)'$。
,将$q(k)$函数改为$q(k)'$。
{原理解释}:对于以Dirac函数分布的真实标签,我们将它变成分为两部分获得(替换)
1) 第一部分:将原本Dirac分布的标签变量替换为(1 - ϵ)的Dirac函数;
2) 第二部分:以概率 ϵ ,在$u(k)$ 中份分布的随机变量。(在文章中,作者采用先验概率也就是均布概率,而K取值为num_class = 1000)
从而交叉熵被替换为: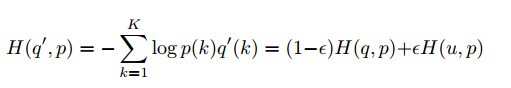
可以认为:Loss 函数为分别对【预测label与真实label】【预测label与先验分布】进行惩罚。
【四】、优化结果
文章表示,对K = 1000,ϵ = 0.1的优化参数,实验结果有0.2%的性能提升。
Reference:
1. Rethinking the Inception Architecture for Computer Vision
2. 深度学习中的各种tricks_1.0_label_smoothing
【Network】优化问题——Label Smoothing的更多相关文章
- 深度学习面试题28:标签平滑(Label smoothing)
目录 产生背景 工作原理 参考资料 产生背景 假设选用softmax交叉熵训练一个三分类模型,某样本经过网络最后一层的输出为向量x=(1.0, 5.0, 4.0),对x进行softmax转换输出为: ...
- softmax求导、cross-entropy求导及label smoothing
softmax求导 softmax层的输出为 其中,表示第L层第j个神经元的输入,表示第L层第j个神经元的输出,e表示自然常数. 现在求对的导数, 如果j=i, 1 如果ji, 2 cross-e ...
- 标签平滑(Label Smoothing)详解
什么是label smoothing? 标签平滑(Label smoothing),像L1.L2和dropout一样,是机器学习领域的一种正则化方法,通常用于分类问题,目的是防止模型在训练时过于自信地 ...
- label smoothing
- DeiT:注意力也能蒸馏
DeiT:注意力也能蒸馏 <Training data-efficient image transformers & distillation through attention> ...
- Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用?
Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用? 2019年07月06日 19:30:55 AI科技大本营 阅读数 675 版权声明:本文为博主原创文章,遵循CC 4.0 B ...
- GAN初步——本质上就是在做优化,对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签 1,体现在loss上!
from:https://www.sohu.com/a/159976204_717210 GAN 从 2014 年诞生以来发展的是相当火热,比较著名的 GAN 的应用有 Pix2Pix.CycleGA ...
- 在 ML2 中配置 OVS vlan network - 每天5分钟玩转 OpenStack(136)
前面我们已经学习了 OVS 的 local 网络 和 falt 网络,今天开始讨论 vlan 网络. vlan network 是带 tag 的网络. 在 Open vSwitch 实现方式下,不同 ...
- Neutron Vlan Network 学习
vlan network 是带 tag 的网络,是实际应用最广泛的网络类型. 下图是 vlan100 网络的示例. 1. 三个 instance 通过 TAP 设备连接到名为 brqXXXX ...
随机推荐
- Nginx-Linux下安装
Nginx一般用来做反向代理,实现负载均衡.由于Nginx是用c开发的,所以安装前我们需要安装相应的环境,比如gcc等.下面是本人安装操作的步骤: step1.安装gcc:yum install gc ...
- java连接sql server数据库(使用用户sa)
一.安装数据库相关软件 sql server management studio是管理sql server数据库的软件,想要使用需到微软官网下载安装sql server,然后再安装sql server ...
- js 倒计时跳转
用js实现简单的倒计时结束页面跳转效果,主要用到setInterval()和clearInterval()方法,页面跳转使用window.location.href = " ".倒 ...
- TiDB 架构及设计实现
一. TiDB的核心特性 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移. 水平弹性扩展 ...
- c/c++ 右值引用,forward关键字
c++ forward关键字 forward的由来:模板函数中的推导类型,作为另一函数的参数时,不管实参是什么类型,作为另一个参数的实参时,都变成了左值.因为C++里规定函数的形参就是左值,不过调用侧 ...
- Win7/Win8.1升级Win10后屏幕一直闪烁怎么办?
有些用户在把Win7/Win8.1升级到Win10正式版后,发现屏幕一直不停闪烁,以至于无法正常使用.出现这种情况的原因可能有很多,微软社区的论坛审阅人Alex_Shen给出了一种解决方案:进入安全模 ...
- bilibili用户信息全栈爬取
- 移动端键盘密码输入框插件(jquery用于支付密码)
最后生成样子: 配置值: * back {function} 回调函数 * msghtml {html} 自定义的html * title {string|object} 标题 * {txt:标题,b ...
- 【html】使用img标签和背景图片之间的区别
1.加载问题 背景图片会等到html结构加载完成才开始加载 img标签是网页结构的一部分,会在html结构加载的时候加载 在网页加载的过程中,背景图片会等到结构加载完成(网页的内容全部显示以后)才开始 ...
- day20 hashlib、hmac、subprocess、configparser模块
hashlib模块:加密 import hashlib# 基本使用cipher = hashlib.md5('需要加密的数据的二进制形式'.encode('utf-8'))print(cipher.h ...