【Network】优化问题——Label Smoothing
滴:转载引用请注明哦【握爪】https://www.cnblogs.com/zyrb/p/9699168.html
今天来进行讨论深度学习中的一种优化方法Label smoothing Regularization(LSR),即“标签平滑归一化”。由名字可以知道,它的优化对象是Label(Train_y)。
对于分类问题,尤其是多类别分类问题中,常常把类别向量做成one-hot vector(独热向量)。
简单地说,就是对于多分类向量,计算机中往往用[0, 1, 3]等此类离散的、随机的而非有序(连续)的向量表示,而one-hot vector 对应的向量便可表示为[0, 1, 0],即对于长度为n 的数组,只有一个元素是1,其余都为0。
之后在网络的最后一层(全连接层)后加一层softmax层,由于softmax输出是归一化的,所以认为该层的输出就是样本属于某类别的概率。而由于样本label是独热向量,因此表征我们已知样本属于某一类别的概率是为1的确定事件,属于其他类别的概率则均为0。
【一】、首先明确一些变量的含义:
$z_i$:也为logits,即未被归一化的对数概率;
$p$:predicted probability,预测的example的概率;
$q$:groundtruth probablity,真实的example的label概率;对于one-hot,真实概率为Dirac函数,即$q(k)=δ_{k,y}$,其中y是真实类别。
$loss$:Cross Entropy,采用交叉熵损失。
softmax层的输出预测概率为:\begin{equation} p(k|x)=\frac{exp(z_k)}{\sum_{i}^{i=K}exp(z_i)} \end{equation}
交叉熵损失表示为:\begin{equation}loss=−\sum_{k=1}^{K}q(k|x)log(p(k|x)) \end{equation}
对于logits,交叉熵是可微分的,偏导数的形式也较为简单:$\frac{∂loss}{∂zk}=p(k)−q(k)$(对于$p,q ∈[0, 1]$, 可以知道梯度是有界的∈[-1, 1])
【二】、one-hot 带来的问题
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:1)无法保证模型的泛化能力,容易造成过拟合;2) 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
【三】、解决方案
为了使得模型less confident,提出以下机制: ,将$q(k)$函数改为$q(k)'$。
,将$q(k)$函数改为$q(k)'$。
{原理解释}:对于以Dirac函数分布的真实标签,我们将它变成分为两部分获得(替换)
1) 第一部分:将原本Dirac分布的标签变量替换为(1 - ϵ)的Dirac函数;
2) 第二部分:以概率 ϵ ,在$u(k)$ 中份分布的随机变量。(在文章中,作者采用先验概率也就是均布概率,而K取值为num_class = 1000)
从而交叉熵被替换为: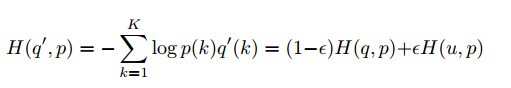
可以认为:Loss 函数为分别对【预测label与真实label】【预测label与先验分布】进行惩罚。
【四】、优化结果
文章表示,对K = 1000,ϵ = 0.1的优化参数,实验结果有0.2%的性能提升。
Reference:
1. Rethinking the Inception Architecture for Computer Vision
2. 深度学习中的各种tricks_1.0_label_smoothing
【Network】优化问题——Label Smoothing的更多相关文章
- 深度学习面试题28:标签平滑(Label smoothing)
目录 产生背景 工作原理 参考资料 产生背景 假设选用softmax交叉熵训练一个三分类模型,某样本经过网络最后一层的输出为向量x=(1.0, 5.0, 4.0),对x进行softmax转换输出为: ...
- softmax求导、cross-entropy求导及label smoothing
softmax求导 softmax层的输出为 其中,表示第L层第j个神经元的输入,表示第L层第j个神经元的输出,e表示自然常数. 现在求对的导数, 如果j=i, 1 如果ji, 2 cross-e ...
- 标签平滑(Label Smoothing)详解
什么是label smoothing? 标签平滑(Label smoothing),像L1.L2和dropout一样,是机器学习领域的一种正则化方法,通常用于分类问题,目的是防止模型在训练时过于自信地 ...
- label smoothing
- DeiT:注意力也能蒸馏
DeiT:注意力也能蒸馏 <Training data-efficient image transformers & distillation through attention> ...
- Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用?
Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用? 2019年07月06日 19:30:55 AI科技大本营 阅读数 675 版权声明:本文为博主原创文章,遵循CC 4.0 B ...
- GAN初步——本质上就是在做优化,对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签 1,体现在loss上!
from:https://www.sohu.com/a/159976204_717210 GAN 从 2014 年诞生以来发展的是相当火热,比较著名的 GAN 的应用有 Pix2Pix.CycleGA ...
- 在 ML2 中配置 OVS vlan network - 每天5分钟玩转 OpenStack(136)
前面我们已经学习了 OVS 的 local 网络 和 falt 网络,今天开始讨论 vlan 网络. vlan network 是带 tag 的网络. 在 Open vSwitch 实现方式下,不同 ...
- Neutron Vlan Network 学习
vlan network 是带 tag 的网络,是实际应用最广泛的网络类型. 下图是 vlan100 网络的示例. 1. 三个 instance 通过 TAP 设备连接到名为 brqXXXX ...
随机推荐
- Windows Azure NotificationHub+Firebase Cloud Message 实现消息推动(付源码)
前期项目一直用的是Windows azure NotificationHub+Google Cloud Message 实现消息推送, 但是GCM google已经不再推荐使用,慢慢就不再维护了, 现 ...
- SSH实现登陆拦截器
/** * 登录验证拦截器 * */ @SuppressWarnings("serial") public class LoginInteceptor implements Int ...
- Java初学习-常见单词
implements 实行/实现 用于实现接口(interface) extends 延伸/扩展 用于类的继承 container 容 ...
- CMMI 2.0术语变化
过程域 vs. 实践域 “过程域”(Process Areas,PAs)在CMMI 2.0中变成了“实践域(Practice Areas,PAs)”.这样的改变,强调了CMMI 2.0是最佳实践的集合 ...
- ES入门REST API
在ES中存在4种数据对象,分别是 index , type , document , field . 其跟我们熟悉的关系型数据库得二维表得对应关系为: index -> table表 ...
- SQLServer之多表联合查询
多表联合查询简介 定义:连接查询是关系型数据库最主要的查询,通过连接运算符可以实现多个表连接数据查询. 分类:内连接,外连接,全外连接. 内连接 定义 内联接使用比较运算符根据每个表的通用列中的值匹配 ...
- js坚持不懈之14:不要在文档加载之后使用 document.write()示例
在看w3school的JavaScript教程时,关于文档输出流中有这么一句话:绝不要在文档加载之后使用 document.write().这会覆盖该文档. 不太明白什么意思,找了一个例子: < ...
- Linux(CentOS7)下如何配置多个Tomcat容器
一.Linux版本 二.上传并解压apache-tomcat-7.0.90压缩包,然后复制粘贴出来多个tomcat 解压缩 tar -xzvf apache-tomcat-7.0.90.tar.gz ...
- properJavaRDP 跑通本地远程桌面
参考:https://www.cnblogs.com/jfqiu/p/3192364.html 包下载:https://mega.nz/#!HnIX0ajA!lcovIdmYWWJJVRngMsQFK ...
- 如何在FineUIMvc(ASP.NET MVC)中显示复杂的表格列数据(列表和对象)?
起源 最初,这个问题是知识星球内的一个网友提出的,如何在FineUIMvc中展现复杂的列数据? 在FineUIPro中,我们都知道有一个 TemplateField 模板列可以使用,我们只需要在后台定 ...