spark 33G表
http://192.168.2.51:4041
http://hadoop1:8088/proxy/application_1512362707596_0006/executors/

Executors
Summary
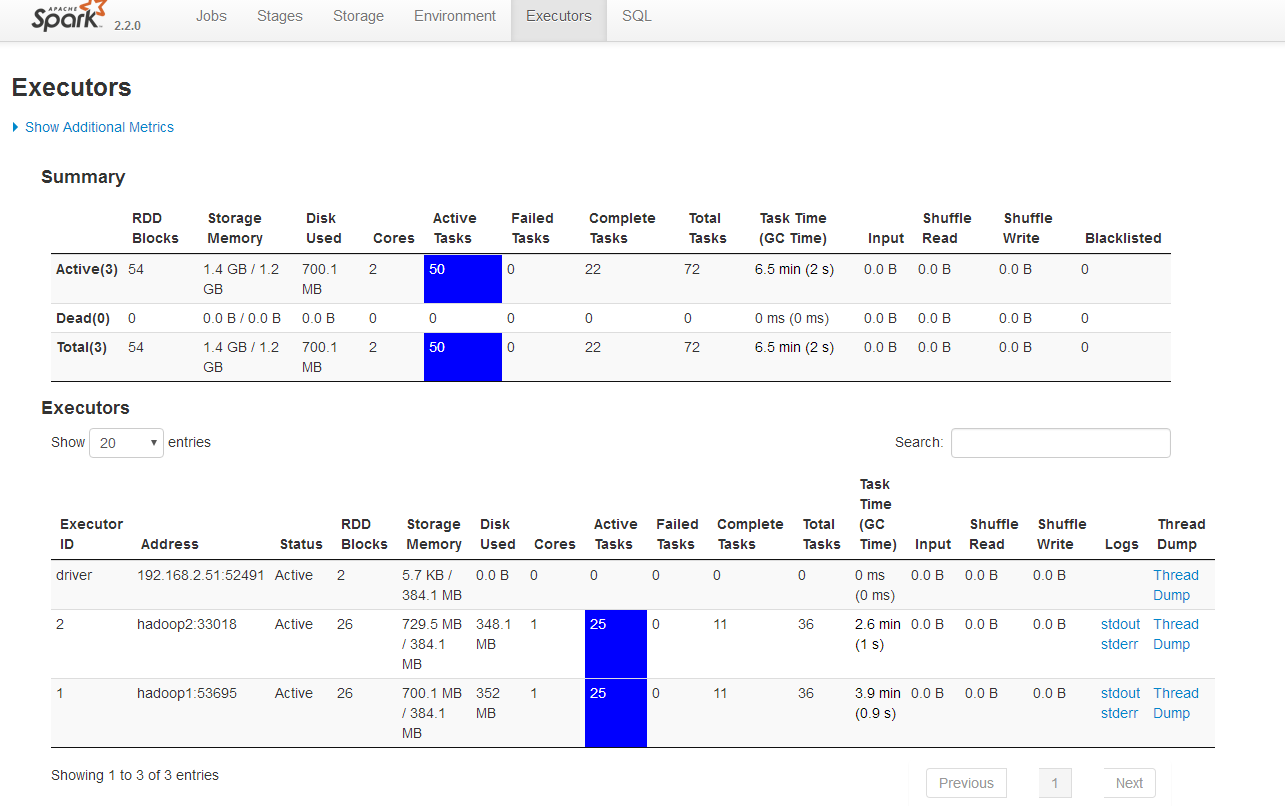
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(0) | 0 | 0.0 B / 0.0 B | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
20
40
60
100
All
entries
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Active | 26 | 729.5 MB / 384.1 MB | 348.1 MB | 1 | 25 | 0 | 11 | 36 | 2.6 min (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Active | 26 | 700.1 MB / 384.1 MB | 352 MB | 1 | 25 | 0 | 11 | 36 | 3.9 min (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
from pyspark.sql import SparkSession my_spark = SparkSession \
.builder \
.appName("myAppYarn-10g") \
.master('yarn') \
.config("spark.mongodb.input.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article") \
.config("spark.mongodb.output.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article") \
.getOrCreate() db_rows = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").load().collect()
Summary
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 31 | 748.4 MB / 1.2 GB | 75.7 MB | 2 | 27 | 0 | 0 | 27 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(2) | 56 | 1.5 GB / 768.2 MB | 790.3 MB | 2 | 0 | 0 | 77 | 77 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(5) | 87 | 2.3 GB / 1.9 GB | 865.9 MB | 4 | 27 | 0 | 77 | 104 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
20
40
60
100
All
entries
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 4 | hadoop2:34394 | Active | 12 | 315.9 MB / 384.1 MB | 0.0 B | 1 | 11 | 0 | 0 | 11 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 3 | hadoop1:39620 | Active | 17 | 432.5 MB / 384.1 MB | 75.7 MB | 1 | 16 | 0 | 0 | 16 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Dead | 27 | 758.7 MB / 384.1 MB | 390.4 MB | 1 | 0 | 0 | 38 | 38 | 1.3 h (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Dead | 29 | 775.9 MB / 384.1 MB | 399.9 MB | 1 | 0 | 0 | 39 | 39 | 1.4 h (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
Logs for container_1512362707596_0006_02_000002 |
|
|
Showing 4096 bytes. Click here for full log Manager: Dropping block taskresult_48 from memory |
|
spark 33G表的更多相关文章
- 基于spark实现表的join操作
1. 自连接 假设存在如下文件: [root@bluejoe0 ~]# cat categories.csv 1,生活用品,0 2,数码用品,1 3,手机,2 4,华为Mate7,3 每一行的格式为: ...
- 利用spark将表中数据拆分
i# coding:utf-8from pyspark.sql import SparkSession import os if __name__ == '__main__': os.environ[ ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
- Databricks 第6篇:Spark SQL 维护数据库和表
Spark SQL 表的命名方式是db_name.table_name,只有数据库名称和数据表名称.如果没有指定db_name而直接引用table_name,实际上是引用default 数据库下的表. ...
- Spark SQL概念学习系列之如何使用 Spark SQL(六)
val sqlContext = new org.apache.spark.sql.SQLContext(sc) // 在这里引入 sqlContext 下所有的方法就可以直接用 sql 方法进行查询 ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
- Spark入门之DataFrame/DataSet
目录 Part I. Gentle Overview of Big Data and Spark Overview 1.基本架构 2.基本概念 3.例子(可跳过) Spark工具箱 1.Dataset ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...
随机推荐
- OkHttpUtil
package jp.co.gunmabank.util import android.os.Handlerimport android.os.Looperimport com.google.gson ...
- 【bzoj1059】[ZJOI2007]矩阵游戏 二分图最大匹配
题目描述 小Q是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏——矩阵游戏.矩阵游戏在一个N*N黑白方阵进行(如同国际象棋一般,只是颜色是随意的).每次可以对该矩阵进行两种操作:行交换 ...
- java.lang.Class解析
java.lang.Class 1.java.lang.Class的概念 当一个类或接口被装入的JVM时便会产生一个与之关联的java.lang.Class对象,java.lang.class类就是用 ...
- Laravel 中视图中使用PHP代码
{{ $name }}{{ date('Y-m-d H:i:s',time()) }}{{ in_array($name,$arr)?'true':'false' }} {{ isset($name) ...
- spring boot -- 无法读取html文件,碰到的坑
碰到的坑,无法Controller读取html文件 1. Controller类一定要使用@Controller注解,不要用@RestController 2. resource目录下创建templa ...
- HTML 中 SELECT 选项分组
<select name="viewType"> <option value selected>选择排序/显示方式</option> <o ...
- Codeforces 487B Strip (ST表+线段树维护DP 或 单调队列优化DP)
题目链接 Strip 题意 把一个数列分成连续的$k$段,要求满足每一段内的元素最大值和最小值的差值不超过$s$, 同时每一段内的元素个数要大于等于$l$, 求$k$的最小值. 考虑$DP$ 设$ ...
- 洛谷——P1746 离开中山路
P1746 离开中山路 题目背景 <爱与愁的故事第三弹·shopping>最终章. 题目描述 爱与愁大神买完东西后,打算坐车离开中山路.现在爱与愁大神在x1,y1处,车站在x2,y2处.现 ...
- All you need to know about SYN floods
http://blog.dubbelboer.com/ Date: 09 Apr 2012Author: Erik Dubbelboer SYN cookies So one day I notice ...
- Action Bar详解(二)
在Android3.0之后,Google对UI导航设计上进行了一系列的改革,其中有一个非常好用的新功能就是引入的ActionBar,他用于取代3.0之前的标题栏,并提供更为丰富的导航效果. 一.添加A ...